

Luma AIのUni-1は、単なる新しいテキスト画像生成モデルではありません。Luma自身の表現では、これは「ピクセルを生成できるマルチモーダル推論モデル」であり、「Unified Intelligence」に基づいて構築されているため、意図を理解し、指示に応答し、あなたと一緒に「考える」ことができます。同社の技術レポートによれば、このモデルは、テキストと画像を単一のインターリーブされた系列で表現するデコーダ専用の自己回帰型トランスフォーマーを採用しており、画像生成の前および生成中に構造化された内部推論を実行できます。この組み合わせこそが、Uni-1を2026年でもっとも興味深い画像モデルのリリースの1つにしている理由です。
UNI-1画像モデルとは何ですか?
Uni-1は、理解と生成の両方を1つのシステムで必要とするタスク向けの、Luma AIの新しい画像モデルです。Lumaはこれを、従来の拡散専用画像エンジンではなく、マルチモーダル推論モデルとして提示しています。これは重要です。なぜなら、このモデルは単に視覚的に魅力的な出力を生成するだけでなく、指示を解釈し、参照制約を維持し、生成の一部としてシーンロジックを推論するよう設計されているからです。同社の技術レポートでは、Uni-1を、マルチモーダル汎用知能への道筋における、初の統合理解・生成モデルと説明しています。
Uni-1が異なる理由
従来のパイプラインには限界があります。理解を伴わない画像生成では、到達できる範囲に限りがあります。Uni-1は、「統合知能」への一歩として提示されており、言語、知覚、想像、計画、実行を1つのアーキテクチャ内で処理します。これは単なるブランディング以上の意味を持ちます。Uni-1は、視覚的な類似性から、意図的な構図、妥当性、シーンロジックへと進むことができます。
より大きな流れとして、画像モデルはますますエージェント的になっています。Googleの最新画像スタックは、会話型編集、検索グラウンディング、複数画像の融合、キャラクターの一貫性を重視しています。OpenAIのGPT Imageファミリーは、ネイティブなマルチモーダル性と指示追従を重視しています。Uni-1もこの流れに加わっていますが、画像を描く前にモデルがその画像について「考える」べきだという考え方を、より強く打ち出しています。そのため、視覚的な華やかさと同じくらい精度と再現性が重要なワークフローにおいて、Uni-1は特に興味深い存在です。
Uni-1は実際にどのように動作するのですか?
🔬 トークン化プロセス
- テキスト → トークン列
- 画像 → トークン化されたパッチ
- 単一のインターリーブされた系列に結合
🔁 生成プロセス
- 入力プロンプト + 参照
- モデルが内部推論を実行
- 構図を計画
- トークンを逐次生成
数式: P(x1,...,xn)=∏P(xi∣x1,...,xi−1)P(x_1,...,x_n) = \prod P(x_i | x_1,...,x_{i-1})P(x1,...,xn)=∏P(xi∣x1,...,xi−1)
🧠 内部推論レイヤー
Uni-1:
- 指示を分解する
- 制約を解決する
- レンダリング前にレイアウトを計画する
👉 これは拡散モデルと比べて大きな飛躍です。
デコーダ専用の自己回帰型生成
もっとも重要な技術的ポイントは、Uni-1が拡散ベースではなく自己回帰型であることです。Lumaの技術レポートによると、これはデコーダ専用の自己回帰型トランスフォーマーであり、テキストと画像は単一のインターリーブされた系列にエンコードされます。平易に言えば、このモデルは単にノイズから開始し、徐々に「ノイズ除去」して画像に近づけるのではありません。代わりに、トークンを1つずつ生成することで、レンダリングの前および最中に、プロンプトを推論し、制約を解決し、構図を計画することができます。
🔬 トークン化プロセス
- テキスト → トークン列
- 画像 → トークン化されたパッチ
- 単一のインターリーブされた系列に結合
拡散 vs 自己回帰
| Feature | Diffusion Models | Uni-1 (Autoregressive) |
|---|---|---|
| 生成 | Noise → Image | Token-by-token |
| 推論 | Limited | Strong |
| 編集 | Weak | Multi-turn |
| テキスト描画 | Poor | Strong |
| 制御 | Low | High |
コアアーキテクチャ
Uni-1は次のとおりです:
- デコーダ専用の自己回帰型トランスフォーマー
- テキストと画像のための共有トークン空間
このアーキテクチャが重要なのは、プロンプトが複雑な場合でもモデルが一貫性を維持する機会を与えるからです。Lumaによれば、Uni-1は指示を分解し、相反する制約を解決し、レンダリング開始前に画像を計画できます。これは、構造化されたシーン補完、複数被写体の配置、マルチターンのリファイン、そして新しい指示に従いながら出力を参照画像に忠実に保つ必要のある編集といったタスクで特に有用です。
このモデルがより得意になるよう設計されていること
画像生成を学ぶことで理解力は向上します。Lumaによれば、このモデルの画像生成トレーニングは、特に領域、オブジェクト、レイアウトに関する細粒度の視覚理解を大きく改善します。だからこそ、Uni-1は一方向の生成器ではなく、生成と理解が相互に強化し合う統合システムとして位置づけられています。推論時の観点では、これはUni-1が「見ること」と「作ること」の間のギャップを埋めようとしていることを意味します。これは拡散モデルに対する大きな飛躍です。
生成プロセス:
- 入力プロンプト + 参照
- モデルが内部推論を実行
- 構図を計画
- トークンを逐次生成
数式: P(x1,...,xn)=∏P(xi∣x1,...,xi−1)P(x_1,...,x_n) = \prod P(x_i | x_1,...,x_{i-1})P(x1,...,xn)=∏P(xi∣x1,...,xi−1)
Uni-1はどのような機能と中核的な利点を提供しますか?
強力な指示追従性と操作性
Uni-1の最大の訴求点は制御性です。このモデルは、精密な編集、構造化された参照利用、再現可能なワークフローのために構築されています。クリエイターにとって、これはプロンプト頼みのギャンブルが減り、より再現性の高い出力が得られることを意味します。
Uni-1の実用的な利点の1つは、制御された反復作業のために構築されていることです。シードによりユーザーは結果を再現でき、参照ロールにより、画像がキャラクターの同一性、ムード、パレット、または構図のどれを導くべきかをモデルが理解できます。そのため、Uni-1は純粋にプロンプト駆動のモデルよりも操作しやすく、特に一貫性が重要な広告、ストーリーボード、製品モックアップ、ブランドアセットを制作するチームに適しています。
同一性を保持する参照ベース生成
大きな利点は参照処理です。Lumaは、Uni-1がソースに基づく制御を使用し、1つまたは複数の参照から同一性、構図、主要な視覚制約を保持できると明言しています。これにより、ブランドキャラクター、製品モックアップ、キャンペーン素材、または各バリエーションで被写体が認識可能であり続けなければならないあらゆるプロジェクトといった商用ワークフローにとって魅力的です。これは、Uni-1がより純粋に美的な画像システムと異なる、もっとも明確な点の1つです。
文化的流暢性と幅広いスタイル
Lumaはまた、文化を理解した生成も強調しています。その「Cultured」セクションでは、ミーム、マンガ、シネマティックなルック、カジュアル写真、スポーツ、動物画像が示されており、このモデルが単一の汎用スタイルではなく、多様なビジュアル言語にまたがって機能することを意図しているとわかります。これは重要です。なぜなら、優れた現代の画像モデルには、リアルなシーンを描写するだけでなく、インターネット文化、エディトリアルデザイン、スタイライズされたイラスト、ソーシャルコンテンツの視覚的慣習も理解する必要があるからです。
設計上の選択としてのマルチモーダル思考
真の差別化要因は、Uni-1が画像を生成することだけではなく、Lumaが画像生成を推論タスクとして位置づけている点です。Uni-1は構造化された内部推論を実行でき、また、画像生成を学ぶことで領域、オブジェクト、レイアウトに関する細粒度の視覚理解が向上します。これは、単にプロンプトを統計的に近似するのではなく、レンダリング前にシーンを理解することを目的としたモデルであることを示唆しています。
パフォーマンスベンチマーク
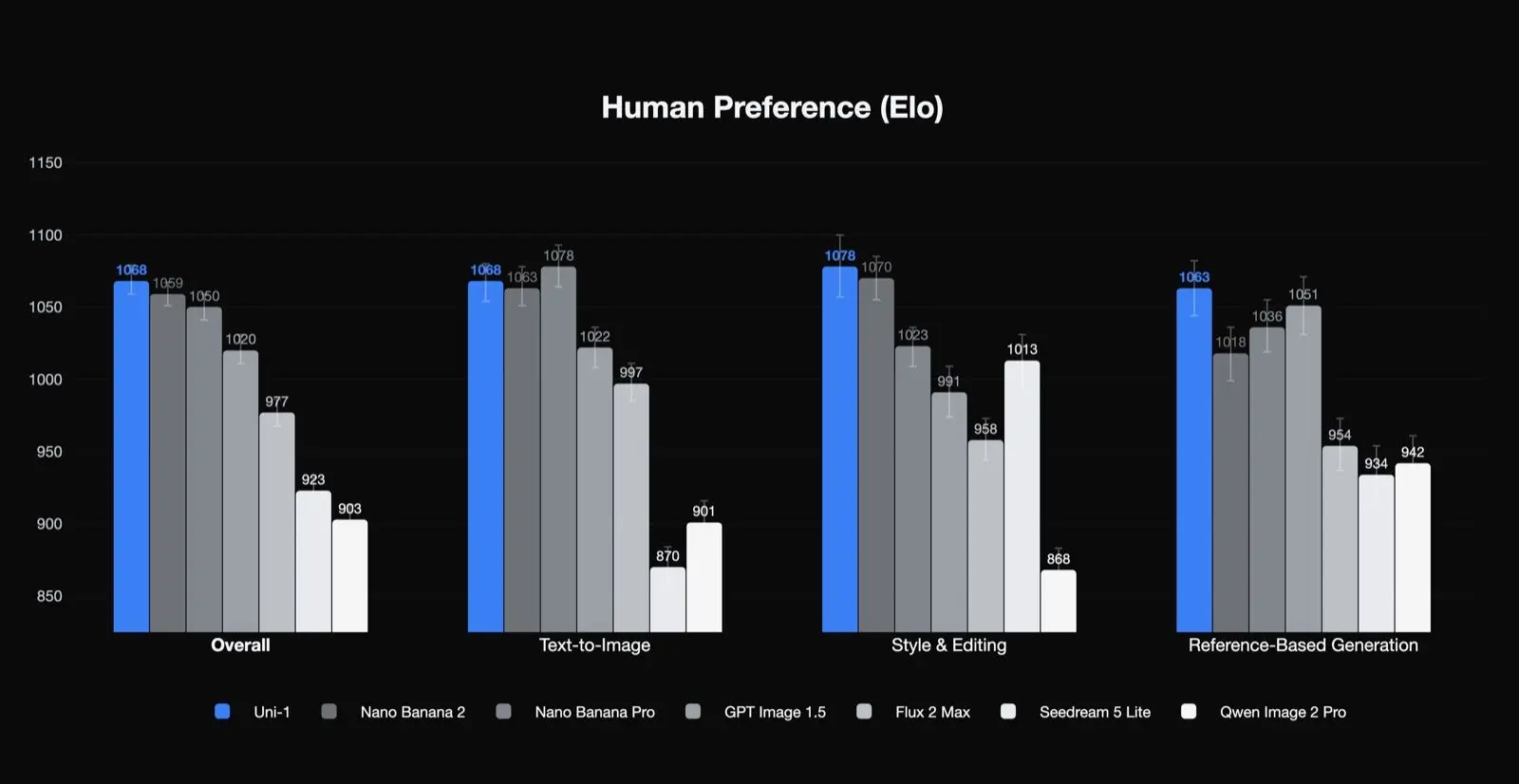
Luma独自の人間選好結果
Uni-1は、総合品質、スタイルと編集、参照ベース生成の人間選好Eloで1位、テキスト画像生成で2位にランクされています。これは重要な結果です。なぜなら、このモデルが制作チームにとって重要な種類のタスク、すなわち編集、一貫性、誘導された変換に特に強いことを示唆しているからです。また、その最適なユースケースが、単純な一発のテキスト画像生成だけではない可能性も示しています。
RISEBench: 推論情報を活用したビジュアル編集
もっとも注目を集めるベンチマークは、時間的、因果的、空間的、論理的推論にまたがる推論情報活用型ビジュアル編集を評価するRISEBenchです。Lumaのローンチに関するサードパーティ報道によると、Uni-1はRISEBench全体で0.51を記録し、GoogleのNano Banana 2の0.50、Nano Banana Proの0.49、OpenAIのGPT Image 1.5の0.46を上回っています。空間推論では、Uni-1は0.58、Nano Banana 2は0.47と報告されています。論理推論では、Uni-1は0.32で、GPT Image 1.5の0.15の2倍以上です。全体では差はそれほど大きくありませんが、もっとも難しい推論カテゴリでは大きな差があります。

ODinW-13と「生成は理解を向上させる」という主張
Uni-1は、オープンボキャブラリ高密度検出ベンチマークであるODinW-13でも高い性能を示しています。Lumaの技術データに関する報道では、完全版モデルは46.2 mAPを記録し、GoogleのGemini 3 Proの46.3にほぼ匹敵しています。同じ報道では、理解専用バリアントは43.9 mAPであり、生成トレーニングによって理解が2.3ポイント向上したことを示唆しています。これは注目に値する発見です。なぜなら、Lumaの中核的な主張、すなわち画像生成と画像理解は競合する目標ではなく、相互に強化し合う可能性があることを裏づけているからです。
Uni-1 APIの価格
| Input price (text) | $0.50 |
|---|---|
| Input price (images) | $1.20 |
| Output price (text and thinking) | $3.00 |
| Output price (images) | $45.45 |
コンシューマー向けでは、Lumaの価格ページに、Plusが月額$30、Proが月額$90、Ultraが月額$300と記載されており、すべてのプランに無料トライアルクレジットが含まれています。つまり、考慮すべき価格体系は実質的に2層あります。プラットフォーム向けのコンシューマーメンバーシップと、本番利用向けのモデルレベルAPI価格です。
現時点では、CometAPIのUni-1 APIは近日提供予定で、ローンチ時には割引が約束されています。現在、CometAPIはMidjourneyやNano Banana 2など、優れたraw画像モデルも提供しています。
Uni-1 vs GPT Image 1.5 vs Nano Banana 2
Uni-1とGoogleのNano Banana 2の比較
Nano Banana 2は、参照処理の幅広さとエコシステム統合でより強力に見えます。Googleは、画像検索グラウンディング、会話型反復、最大14件の参照を使う参照重視ワークフローを強調しています。一方のUni-1は、推論、シーンの妥当性、精密な編集を、統一モデルアーキテクチャの中でより明確に前面に押し出しています。実際には、Googleは速度、主流の本番スケール、Googleネイティブのグラウンディングに最適化されているように見え、Lumaは構造化された視覚推論と操作可能な画像編集に最適化されているように見えます。
Uni-1をめぐる公開比較では、トレードオフは明確です。Nano Banana 2は、純粋なテキスト画像品質と速度において依然として非常に強力に見える一方で、Uni-1は推論負荷の高い編集、参照制御、指示忠実性により強く踏み込んでいます。
Uni-1とOpenAIのGPT Imageの比較
ベンチマーク報道では、Uni-1はRISEBench全体でGPT Image 1.5を上回り、特に論理推論でより明確な差をつけています。OpenAIのGPT Imageファミリーと比べると、Uni-1は視覚推論と制御された編集に、より狭く、かつ積極的に位置づけられています。OpenAIのドキュメントは、世界知識、マルチモーダル理解、文脈認識を強調しています。一方、Lumaのドキュメントは、構造化された内部推論、参照に基づく制御、ベンチマークで検証されたビジュアル編集能力を強調しています。したがって、両者ともマルチモーダルではありますが、Uni-1はより明確に「画像特化型の推論モデル」であり、GPT Imageはむしろ、たまたま非常に優れた画像生成もできる汎用マルチモーダルシステムのように読めます。
3者間の価格比較
価格面では、比較は出力サイズと製品ティアに依存するため、完全に同条件の比較ではありません。Uni-1の公表されている2048px相当は、画像1枚あたり約$0.0909です。Googleの最新画像モデル価格ページでは、最新のGemini画像プレビューについて、1K/2K画像が$0.134、4K画像が$0.24と記載されています。一方、OpenAIのGPT Image価格ページでは、1024x1024の低品質で$0.011、中品質で$0.042、高品質で$0.167、より大きな高品質出力で$0.25の画像単位出力価格が記載されています。つまり、OpenAIは低価格帯ではかなり安価になり得て、Googleは速度とスケール重視の領域で積極的な価格設定をしており、Uni-1は強力な2K志向の価格性能プロファイルでその中間に位置しています。
哲学的な違い
| Model | Approach |
|---|---|
| Uni-1 | Unified multimodal intelligence |
| GPT Image | LLM + image generation |
| Nano Banana 2 | Optimized production diffusion |
詳細比較表
| Feature | Uni-1 | GPT Image 1.5 | Nano Banana 2 |
|---|---|---|---|
| アーキテクチャ | Autoregressive | Hybrid | Diffusion |
| マルチモーダル統合 | ✅ Native | Partial | ❌ |
| 推論能力 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ |
| 画質 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| テキスト描画 | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐ |
| 編集ワークフロー | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ |
| 速度 | Medium | Fast | Fast |
| 制御性 | High | Medium | Medium |
CometAPIは、GPT Image 1.5、Nano Banana 2、および今後提供予定のUni-1向けに、インタラクティブなraw画像とAPIプログラミングを提供しています。割引価格と従量課金オプションにより、開発者にとって好ましい選択肢となっています。
Uni-1がもっとも適している用途
Uni-1は、再現性、キャラクターの一貫性、または複数参照の制御が必要なケースで特に強力に見えます。これには、ブランドキャンペーン、製品モックアップ、エディトリアルコンセプト、ストーリーボード、ローカライズ版、そして構図は維持しつつスタイルや環境を変更したい画像編集が含まれます。Luma自身の例もこれらのユースケースに大きく寄っており、モデルの「Create vs Modify」の分離は、よくある制作上の痛点に対する直接的な答えと言えます。
もしあなたの作業が主に「1つのプロンプトから何か見栄えの良いものを作る」ことであれば、その差別化要因はそれほど劇的には感じられないかもしれません。しかし、ワークフローが「関連する5つのバージョンを作り、同じキャラクターを維持し、フレーミングを保ち、照明を変え、来週も再現可能にする」というものであれば、Uni-1の設計は非常に理にかなっています。これは推測ではありますが、Lumaが強調している制御機能から自然に導かれる結論です。
Uni-1でより良い結果を得るためのベストプラクティス
まず、正しいモードを使うことから始めてください。Lumaのガイダンスはシンプルです。新しいシーンが欲しいときはCreate、既存のシーンを保持したいときはModifyです。これらの意図を混ぜると、出力は不安定になりやすくなります。
参照ラベルはプロのように使いましょう。Lumaは、「Use IMAGE1 as a STYLE reference」や「Use IMAGE2 as LIGHTING」のような表現を推奨しています。各参照に曖昧な「インスピレーション」ではなく役割を与えると、モデルはよりうまく機能します。
良い結果を見つけたら、シードを固定してください。Lumaはまずシードなしで探索し、その後、強い結果が得られた時点でシードを保存することを明確に推奨しています。その後は、1回に1つの変数だけを変更します。これが、生成を制御された制作システムへと変えるもっとも簡単な方法です。
具体的に、明確に書いてください。Lumaは「beautiful」や「amazing」のような曖昧な語を避け、「1970s Italian giallo film poster」のような名前付きの美学や、正確なカメラスタイルの手がかりを使うことを推奨しています。実際には、具体的なプロンプトのほうが詩的なプロンプトよりも優れることが多いです。なぜなら、モデルが実際の構造に基づいて解釈できるからです。
Create → Modifyチェーンを使ってください。Lumaはこれをもっとも強力なワークフローの1つとして明確に挙げています。Createで探索し、その後Modifyで洗練させます。これは本格的な制作作業における最適なポイントです。なぜなら、後戻りを減らし、構図の良い部分を保ちながらディテールを詰められるからです。
最終評価
Uni-1は、画像生成が「プロンプトを入れて、画像が出る」という段階から、推論に導かれたビジュアル創造へ移行しつつあることを示す、Lumaのこれまででもっとも明確な表明です。その公に示されている強みは、制御性、参照処理、再現性、そして言語とピクセルを同じシステム内に保持するモデルアーキテクチャにあります。
高いクリック率を生むビジュアル出力、一貫したキャラクター、精密な編集、高解像度における価格の明確さを重視するクリエイターやチームにとって、Uni-1は非常に注目に値するモデルです。APIの展開が順調に進めば、2026年においてGoogleのNano Banana 2やOpenAIのGPT Image 1.5に対するもっとも興味深い代替候補の1つになる可能性があります。
raw画像の作成を始める予定ですか? マルチモーダルモデルAPIのワンストップ集約プラットフォームであるCometAPIが、あなたを歓迎します!