

クウェン2.5-VL-32B APIは、 優れた性能 さまざまな複雑なタスクにおいて、 画像とテキストデータ 世界をより深く理解するために。 アリババこの32億パラメータモデルは、以前の Qwen2.5-VL シリーズは、 AIによる推論 および 視覚的理解.

Qwen2.5-VL-32Bの概要
Qwen2.5-VL-32Bは 最先端のオープンソースマルチモーダルモデル テキストと画像の両方を含むさまざまなタスクを処理するように設計されています。 32億のパラメーターを提供します。 強力なアーキテクチャ の 画像認識, 数学的推論, 対話生成、そしてその他多数。強化された 学習能力強化学習に基づいて、人間の好みにより合った回答を生成できるようになります。
主な特徴と機能
Qwen2.5-VL-32B は、複数のドメインにわたって優れた機能を発揮します。
画像の理解と説明: このモデルは 画像分析物体やシーンを正確に識別し、詳細な自然言語による説明を生成し、 きめ細かな洞察 オブジェクトの属性とそれらの関係を分析します。
数学的推論と論理: このモデルは、次のような複雑な数学的問題を解くことができます。 幾何学から代数学へ—雇用することによって 多段階推論 明確なロジックと構造化された出力を備えています。
テキスト生成と対話: 高度な言語モデルを備えたQwen2.5-VL-32Bは、入力されたテキストや画像に基づいて、一貫性があり文脈に適した応答を生成します。また、 マルチターンダイアログより自然で継続的なやり取りが可能になります。
ビジュアル質問応答: モデルは画像の内容に関する質問に答えることができます。例えば、 物体認識 および シーンの説明洗練されたビジュアルロジックと推論機能を提供します。
Qwen2.5-VL-32Bの技術的基礎
Qwen2.5-VL-32B のパワーを理解するには、その技術的原理を調べることが重要です。以下は、そのパフォーマンスに貢献する主要な側面です。
- マルチモーダル事前トレーニング: モデルは以下を使用して事前トレーニングされています 大規模データセット 両方からなる テキストと画像データこれにより、多様な視覚的特徴と言語的特徴を学習し、シームレスなクロスモーダル理解が可能になります。
- 変圧器のアーキテクチャ: 堅牢な 変圧器のアーキテクチャこのモデルは、 エンコーダ および デコーダ 画像やテキストの入力を処理し、非常に正確な出力を生成する構造。 自己注意メカニズム 入力データ内の重要なコンポーネントに焦点を当てることができるため、精度が向上します。
- 強化学習最適化: Qwen2.5-VL-32Bは強化学習の恩恵を受けており、人間のフィードバックに基づいて微調整されます。このプロセスにより、モデルの応答がより正確になります。 人間の好みに合致する 複数の目標を最適化しながら、 精度, ロジック, 流ちょうさ.
- 視覚と言語の整合:スルー 対照学習 および調整戦略により、モデルは 視覚的な特徴 および テキスト情報 適切に統合されている 言語空間非常に効果的です マルチモーダルタスク.
業績ハイライト
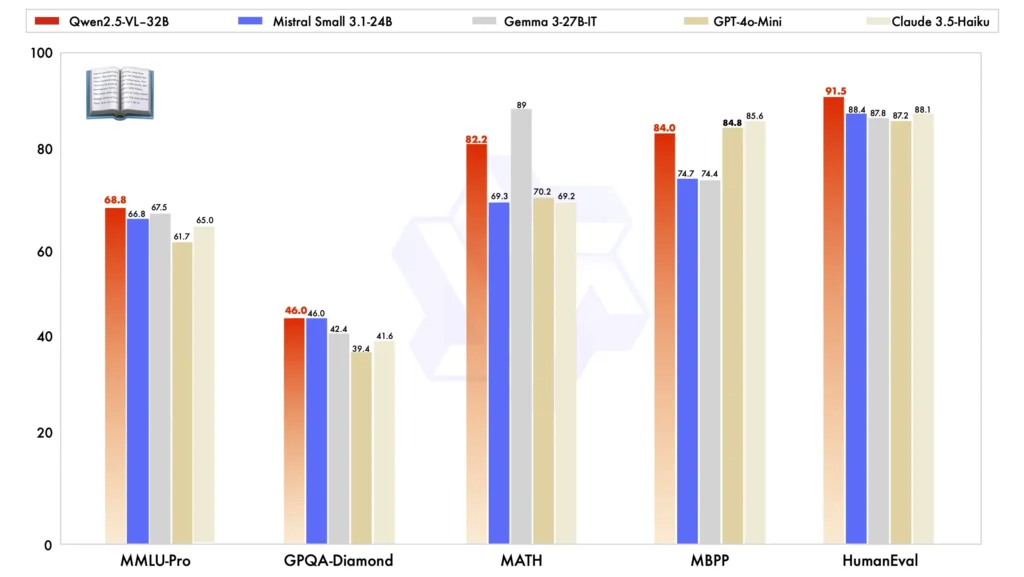
他の大型モデルと比較すると、Qwen2.5-VL-32Bはいくつかの重要なベンチマークで際立っており、 優れた性能 両者に マルチモーダル および プレーンテキストタスク:
モデルの比較: 他のモデルと比較して ミストラル-スモール-3.1-24B および ジェマ-3-27B-ITQwen2.5-VL-32Bは大幅に改善された機能を発揮します。特に、 より大きなQwen2-VL-72Bよりも優れている さまざまなタスクで。
マルチモーダルタスクパフォーマンス: 複雑な マルチモーダルタスク など MMMU, MMMUプロ, MathVistaQwen2.5-VL-32B は、同様のサイズの他のモデルとは一線を画す正確な結果を提供します。
MM-MT-ベンチベンチマーク: 旧バージョンのQwen2-VL-72B-Instructと比較すると、新バージョンでは特に 論理的推論 および マルチモーダル推論 機能を提供します。
プレーンテキストのパフォーマンス: プレーンテキストベースのタスクでは、Qwen2.5-VL-32Bが トップパフォーマー 同クラスでは、 強化されたテキスト生成, 推論、そして全体的な精度。
プロジェクトリソース
Qwen2.5-VL-32B をさらに詳しく知りたい開発者や AI 愛好家向けに、いくつかの重要なリソースが用意されています。
- 公式ウェブサイト: Qwen2.5-VL-32B プロジェクト
- ハギングフェイスモデル: ハギングフェイス Qwen2.5-VL-32B-インストラクト
実際のアプリケーション
Qwen2.5-VL-32Bは汎用性が高く、幅広い用途に適しています。 実用的なアプリケーション さまざまな業界にわたって:
インテリジェントな顧客サービス: このモデルは、顧客からの問い合わせを自動処理するために使用することができ、理解と生成の能力を活用することができる。 テキストベースと画像ベースの応答.
教育支援: 解決することで 数学的問題、通訳 画像コンテンツ、概念を説明することで、学生の学習プロセスを大幅に強化することができます。
画像注釈: コンテンツ管理システムでは、Qwen2.5-VL-32Bは、 画像のキャプション および 説明メディアやクリエイティブ業界にとって非常に貴重なツールとなります。
自動運転: 視覚処理機能を通じて道路標識や交通状況を分析することで、モデルはリアルタイムの洞察を提供し、改善することができます。 安全運転.
コンテンツ制作メディアや広告では、このモデルは 클라우드 기반 AI/ML및 고성능 컴퓨팅을 통한 디지털 트윈의 기초 – Edward Hsu, Rescale CPO
많은 엔지니어링 중심 기업에게 클라우드는 R&D디지털 전환의 첫 단계일 뿐입니다. 클라우드 자원을 활용해 엔지니어링 팀의 제약을 해결하는 단계를 넘어, 시뮬레이션 운영을 통합하고 최적화하며, 궁극적으로는 모델 기반의 협업과 의사 결정을 지원하여 신제품을 결정할 때 데이터 기반 엔지니어링을 적용하고자 합니다. Rescale은 이러한 혁신을 돕기 위해 컴퓨팅 추천 엔진, 통합 데이터 패브릭, 메타데이터 관리 등을 개발하고 있습니다. 이번 자리를 빌려 비즈니스 경쟁력 제고를 위한 디지털 트윈 및 디지털 스레드 전략 개발 방법에 대한 인사이트를 나누고자 합니다. 視覚刺激に基づいて、コンテンツ作成者がビデオや広告の魅力的な物語を制作するのを支援します。
今後の展望と課題
Qwen2.5-VL-32B はマルチモーダル AI における飛躍的な進歩を表していますが、今後も課題と機会が残されています。 微調整 より具体的なタスクのためのモデルを開発し、リアルタイムアプリケーションと統合し、 スケーラビリティ より複雑なマルチモーダルデータセットを処理するには、継続的な研究開発が必要な分野です。
さらに、同様の機能を備えたAIモデルがさらにリリースされるにつれて、 倫理的な問題 AI生成コンテンツを取り巻く バイアス, データプライバシー 引き続き注目を集めています。Qwen2.5-VL-32B および類似のモデルが責任を持って訓練され、使用されるようにすることが、長期的な成功にとって重要です。
関連トピック:8 年に最も人気の高い AI モデル 2025 選の比較
結論
Qwen2.5-VL-32Bは、AIモデルを扱うための強力なツールです。 マルチモーダルタスク 驚くほどの精度と洗練性を備えています。高度な 強化学習, トランスアーキテクチャ, 視覚言語の整合、それは 以前のモデルを上回る だけでなく、さまざまな産業に刺激的な可能性をもたらします。 教育 〜へ 自動運転オープンソーステクノロジーとして、開発者や AI ユーザーが実際のアプリケーションで実験、最適化、実装するための大きな可能性を提供します。
CometAPI から Qwen2.5-VL-32B API を呼び出す方法
1.ログイン 〜へ コムタピまだユーザーでない場合は、まず登録してください
2.アクセス認証情報APIキーを取得する インターフェースの。パーソナルセンターのAPIトークンで「トークンの追加」をクリックし、トークンキー:sk-xxxxxを取得して送信します。
-
このサイトの URL を取得します。 https://api.cometapi.com/
-
APIリクエストを送信するためにQwen2.5-VL-32Bエンドポイントを選択し、リクエストボディを設定します。リクエストメソッドとリクエストボディは以下から取得されます。 当社のウェブサイトAPIドキュメント弊社のウェブサイトでは、お客様の便宜を図るため、Apifox テストも提供しています。
-
API レスポンスを処理して、生成された回答を取得します。API リクエストを送信すると、生成された補完を含む JSON オブジェクトが受信されます。