

2026년 3월 3일, Google은 개발자와 엔터프라이즈 워크로드를 위한 고처리량·저지연·비용 효율 엔진으로 설계된 Gemini 3 패밀리의 최신 모델인 Gemini 3.1 Flash-Lite를 공개했다. Google은 Flash-Lite를 Gemini 3 라인업에서 “가장 빠르고 가장 비용 효율적인” 모델로 포지셔닝하고 있으며, 스트리밍 상호작용, 대규모 백그라운드 처리, 고빈도 프로덕션 작업(예: 번역, 추출, UI 생성, 대량 분류)을 훨씬 낮은 가격으로 제공하는 경량형 변종으로 설명한다.
아래에서 Flash-Lite가 무엇인지 살펴본다.
What is Gemini 3.1 Flash-Lite
Gemini 3.1 Flash-Lite는 속도와 비용 효율성을 위해 최고 수준의 추론 깊이 일부를 의도적으로 교환한 Google의 Gemini 3 패밀리 구성원이다. Gemini 계보의 네이티브 멀티모달 특성(텍스트, 이미지 등 다양한 모달리티 입력 수용)은 유지하되, 최대한의 초당 토큰 처리량과 낮은 토큰당 과금을 제공하도록 튜닝·배포되어, 최대 인지 깊이보다는 신속하고 반복적인 추론이 필요한 워크로드에 적합하다. 이 모델은 3.1 Pro 아키텍처에서 파생되었으나 처리량·지연·비용을 최적화한 것으로 설명된다.
Key design tradeoffs
“Lite”라는 명칭은 다음과 같은 엔지니어링 초점을 시사한다:
- Throughput over heavyweight reasoning: Flash-Lite는 토큰당 연산을 의도적으로 줄여 더 빠른 첫 토큰 시간(TTFT)과 지속적인 출력 속도를 달성한다. 이는 각 요청을 빠르고 대규모로 처리해야 하는 파이프라인(예: 안전성 필터, 실시간 어시스턴트, 대량 생성)에 적합하다.
- Cost efficiency for high volumes: 토큰당 연산을 낮춤으로써, 백만 토큰당 가격을 낮게 책정할 수 있어 월 수백만~수십억 토큰 규모의 애플리케이션에서 한계 비용을 줄인다. Google의 프리뷰 가격은 Pro 티어 대비 의미 있는 차이를 보여준다.
- Quality tuned for pragmatic tasks: 초기 점수 요약에 따르면, Flash-Lite는 표준 분류, 다국어, 많은 멀티모달 과제에서 강력한 결과를 유지하지만, 복잡한 다단계 추론이나 코드 생성처럼 깊이가 중요한 벤치마크에서는 Pro를 능가하도록 포지셔닝되어 있지 않다.
이러한 워크로드는 신뢰할 수 있는 출력과 높은 처리량이 필요하지만, 항상 플래그십 모델의 복잡한 다단계 추론 능력이 필요한 것은 아니다.
Key Features of Gemini 3.1 Flash-Lite
1. Low latency and fast first-token time
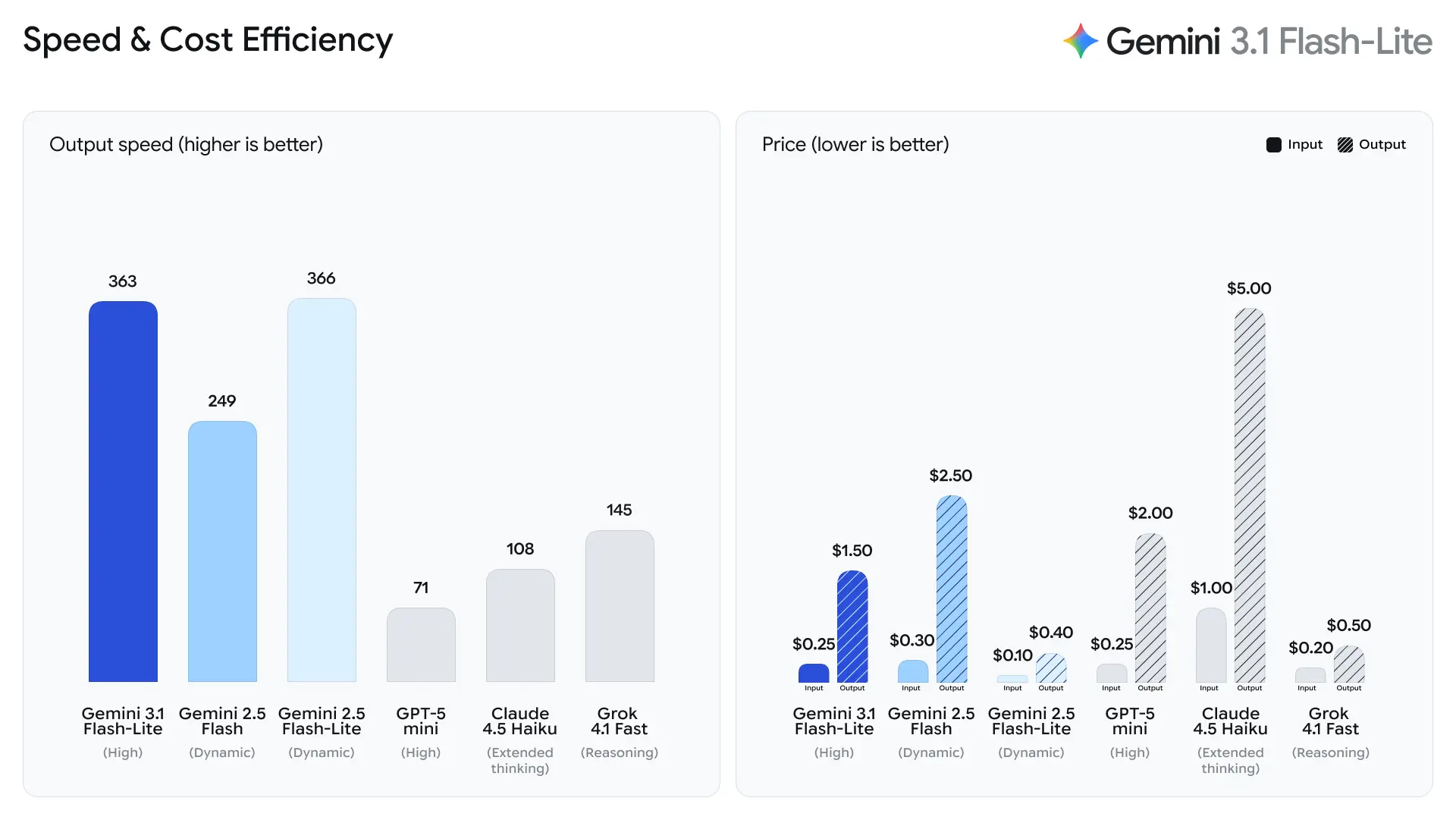
Google은 Flash-Lite의 주요 지표로 첫 답변 토큰까지의 시간을 강조한다. 회사에 따르면 Gemini 2.5 Flash 대비 ~2.5× 빠른 첫 토큰 시간과 최대 45% 더 빠른 출력 생성을 보고했으며, 이는 최종 사용자 체감 반응성과 백엔드 시스템의 처리 비용에 직접적인 영향을 준다. 이러한 개선은 앱 내에 내장된 챗봇 등 인터랙티브 기능과 마이크로초 단위가 중요한 고 QPS 파이프라인에 특히 적합하다.
이 개선은 다음과 같은 실시간 애플리케이션에서 효과가 크다:
- 대화형 AI
- AI 기반 검색 어시스턴트
- 인터랙티브 챗봇
- 실시간 번역 서비스
낮은 지연은 대기 시간을 줄이고 더 유려한 상호작용을 가능하게 해 사용자 경험을 향상시킨다.
2. Cost-Efficient Token Pricing
AI 추론 비용은 종종 토큰 기준으로 계산되므로, 대규모 배포에서는 가격이 핵심 요소가 된다.
Gemini 3.1 Flash-Lite는 매우 경쟁력 있는 가격 구조를 도입했다:
| Token Type | Price |
|---|---|
| Input tokens | $0.25 per 1M 토큰 |
| Output tokens | $1.50 per 1M 토큰 |
이는 이전 Flash 모델 대비 인하된 가격으로, 대규모 워크로드를 운영하는 조직에 매력적이다.
비교:
| Model | Input Price | Output Price |
|---|---|---|
| Gemini 3 Flash | $0.50 / 1M | $3.00 / 1M |
| Gemini 3.1 Flash-Lite | $0.25 / 1M | $1.50 / 1M |
이 가격 전략을 통해 개발자는 운영 비용을 급격히 늘리지 않고도 대규모로 AI를 실행할 수 있다.
더 나은 가격을 찾고 있다면, Gemini Flash-Lite가 CometAPI에서 20% 할인을 제공한다.
3. “Thinking levels” (controllable inference depth)
Gemini 3.1 Flash-Lite에는 “thinking levels” 기능이 포함되어 있어, 개발자가 사소한 작업에는 더 빠르고 얕은 처리를, 어려운 작업에는 더 깊은 추론을 선호하도록 모델을 구성할 수 있다. 이는 요청별로 모델을 바꾸지 않고도 동적으로 비용/지연을 조절할 수 있다는 점에서 실무적으로 중요하다.
개발자는 작업 복잡도에 맞춰 모델의 추론 깊이를 구성할 수 있다. Thinking levels: Minimal, Low, Medium, High의 네 가지 레벨을 지원한다.
이 동적 접근은 품질을 유지해야 하는 곳에서는 품질을 유지하면서 리소스 사용을 최적화할 수 있게 한다. 실무 전략은 대략 다음과 같다:
- Minimal/Low: 번역, 분류, 감성 분석처럼 논리적으로 단순하지만 동시성이 높은 작업에 적합하며, 속도와 비용 최소화를 최우선한다.
- Medium: 대부분의 프로덕션 작업에 적합하며, 품질과 효율 간의 균형을 맞춘다.
- High: 사용자 인터페이스 생성, 시뮬레이션 생성, 복잡한 지시 실행 등 깊은 추론이 필요한 작업에 적합하다.
4. Multimodal capability with a lightweight footprint
Flash-Lite는 속도와 비용에 최적화되어 있지만, Gemini 3 라인의 멀티모달 기반은 유지한다. 필요 시 분류나 경량 멀티모달 추론을 위해 이미지 입력을 받을 수 있지만, 경제적인 설계 특성상 매우 크고 이미지 중심의 워크플로보다는 짧고 범위가 제한된 멀티모달 작업에 더 적합하다. 다른 Gemini 모델과 마찬가지로, Gemini 3.1 Flash-Lite는 멀티모달 입력을 지원해 다양한 유형의 데이터를 처리할 수 있다.
지원 입력:
- Text
- Images
- Video
- Audio
- PDFs
여러 유형의 정보를 분석할 수 있는 능력은 다음과 같은 새로운 활용 사례를 가능하게 한다:
- 문서 자동 처리
- 시각 데이터 추출
- 멀티미디어 요약
이전 Gemini 모델들도 다양한 시각/지식 벤치마크에서 강한 멀티모달 추론 능력을 보여준 바 있다.
Performance benchmarks — real numbers and what they mean
Google의 발표와 제품 문서에는 Flash-Lite의 생태계 내 위치를 이해하는 데 도움이 되는 여러 벤치마크 데이터 포인트가 제시되어 있다.
Developer-facing speed metrics
- Gemini 2.5 Flash 대비 2.5× 빠른 첫 답변 토큰 시간(Google의 내부 비교치).
- Gemini 2.5 Flash 대비 45% 더 빠른 출력 생성 속도.
이는 사람 평가 기반 품질 지표가 아닌 성능 엔지니어링 지표로, 단문 응답 지연을 줄이는 런타임 마이크로아키텍처, 배칭, 추론 스택 최적화의 개선을 반영한다. 더 빠른 첫 토큰 시간은 인터랙티브 애플리케이션에서 지연 체감을 줄이고 서버당 전체 처리량을 높여 동일 QPS에서 총 연산 비용을 낮출 수 있다.
Tokens-per-second (t/s) and throughput
Artificial Analysis의 테스트 데이터에 따르면, 3.1 Flash-Lite는 초당 388.8 토큰의 출력 속도를 달성했으며(동일 가격대 모델의 중앙값은 96.7 토큰/초), 이는 동급 최고 수준이다.
다만 Artificial Analysis는 다음과 같은 문제도 지적했다: 3.1 Flash-Lite의 첫 토큰 지연(TTFT)은 5.18초로, 동일 가격대 추론 모델의 중앙값(1.82초) 대비 비교적 높다. 또한 평가 과정에서 모델이 생성한 토큰 수는 53 million으로 평균인 20 million 대비 상대적으로 높다. 따라서 첫 토큰 지연에 매우 민감하거나 출력 간결성에 엄격한 요구가 있는 시나리오에서는 thinking level과 프롬프트를 최적화할 필요가 있다.
Benchmark scores for reasoning and factuality
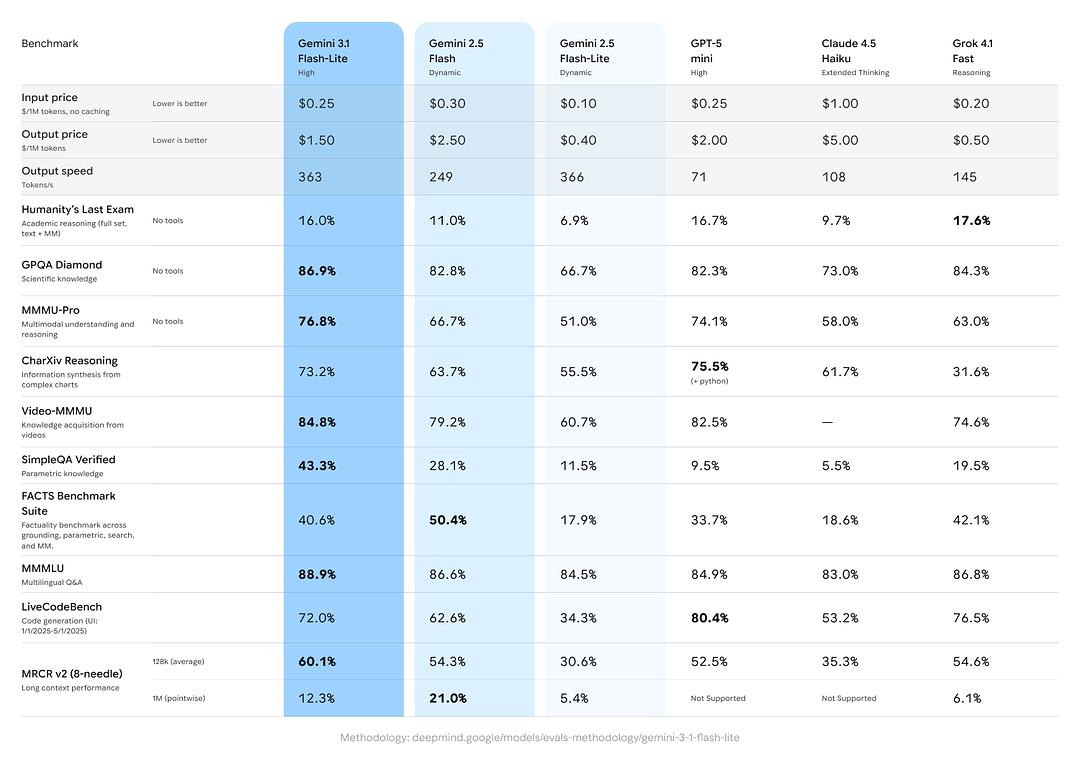
Google은 종합 추론/사실성 과제에서 Gemini 3.1 Flash-Lite가 동급 및 이전 Gemini 변종 대비 강력한 성능을 보였다는 교차 모델 비교 결과를 포함했다:
- Arena.ai Elo score: Arena 리더보드에서 Elo 1432를 기록(직접 대결 기반의 상대적 성능 지표).
- GPQA Diamond: 86.9%(질의응답 견고성 지표).
- MMMU Pro: 76.8%(일부 연구기관 내·외부에서 사용하는 멀티모달/멀티태스크 지표).
- LiveCodeBench (Coding Ability): 72.0%
- CharXiv Reasoning (Graphical Reasoning): 73.2%
- Video-MMMU (Video Comprehension): 84.8%
Gemini 3.1 Flash-Lite는 속도/비용을 크게 개선하면서도 여러 지표에서 기존 Gemini 2.5 Flash를 상회한다.
Use cases that fit Gemini 3.1 Flash-Lite
Gemini 3.1 Flash-Lite는 토큰당 비용과 처리량이 결정적인 실무형 워크로드를 중심으로 설계되었다:
High-frequency conversational agents & streaming UI
실시간 챗봇, 실시간 음성 받아쓰기 + 번역 스트림, 그리고 생성 중 부분 답변을 표시하는 협업형 UI 등은 Flash-Lite의 스트리밍 토큰 출력과 낮은 첫 토큰 시간을 통해 이점을 얻는다.
Bulk data processing (RAG, transformation pipelines)
대규모 문서 적재: 엔터티 추출, 메타데이터 태깅, 분류, 번역 등 수백만 문서에 걸친 작업—Gemini 3.1 Flash-Lite는 템플릿화·규칙 기반 출력에 대해 수용 가능한 정확도를 제공하면서 추론 비용을 낮춘다.
Edge-style or background compute
수신되는 텔레메트리나 비정형 데이터를 지속적으로 처리하는 워크로드(예: 콘텐츠 검열 분류 파이프라인, 자동 보고서 생성)는 Flash-Lite의 단위당 비용 최소화와 잘 맞는다.
Developer tooling and batch code completion
멀티파일 스캐폴딩, 대규모 코드 린팅, 템플릿 대량 생성 등 기능에서, 최대 추론 깊이가 필요하지 않은 개발자 경험 도구에 대해 Flash-Lite의 속도 이점은 지연과 비용을 줄여준다.
Comparing Gemini 3.1 Flash-Lite to other Gemini models and competitors
Within the Gemini family
- Gemini 3.1 Pro: 복잡한 추론과 다단계 계획에서 최고 능력; 토큰당 비용과 속도는 더 느리고 비싸지만, 깊이 있는 정교한 작업에 적합.
- Gemini 3.1 Flash (non-Lite): 처리량과 능력의 중간 지점을 목표—Flash-Lite는 처리량을 위해 더 낮은 레벨에서 연산을 최적화.
Versus competing “fast” models
Gemini 3.1 Flash-Lite는 여러 “fast/mini” 모델과 비교해 처리량과 품질 지표에서 앞서거나 대등한 성능을 보인다—다만 독립 분석가들은 정면 비교가 평가 방법론과 데이터셋 선택에 매우 민감하다고 경고한다. 최고 난도의 추론 지표에서는 중위권에 머물 가능성이 있지만, 처리량과 비용 면에서는 매우 경쟁력이 높을 것으로 예상된다.
Conclusion — where Flash-Lite fits in the AI stack
Gemini 3.1 Flash-Lite는 사례당 연산 일부를 희생해 지연과 비용을 극적으로 개선하도록 설계된, Gemini 3 패밀리의 효율·처리량 중심 모델이다. 번역, 배치 처리, 스트리밍 UI, 중간 복잡도의 에이전트형 작업 등 대량 파이프라인을 구축하는 기업과 개발자에게 합리적인 기본 엔진이 된다. 반면 최고 수준의 추론 정밀도가 필요한 경우에는 Pro 모델이 적합하다.
워크로드가 짧고 반복적인 추론이 다수를 차지하거나 대규모에서 빠른 스트리밍 출력이 필요한 경우, Flash-Lite를 파일럿할 가치가 있다. 반대로 깊은 멀티홉 추론이 핵심인 워크로드라면 하이브리드 접근을 계획하자: 처리량 위주의 트래픽은 Flash-Lite로 라우팅하고, 고가치·고난도 쿼리는 Pro 모델로 승격하는 방식이다.
개발자는 지금 Gemini 3.1 Flash Lite를 CometAPI를 통해 이용할 수 있다. 시작하려면 Playground에서 모델 기능을 탐색하고, 자세한 지침은 API guide를 참고하자. 접근 전에 CometAPI에 로그인하고 API 키를 발급받아야 한다. CometAPI는 통합을 돕기 위해 공식 가격보다 훨씬 낮은 가격을 제공한다.
Ready to Go?→ 지금 Gemini 3.1 Flash-Lite에 가입하세요 !