

Claude Opus 4.5는 Anthropic의 최신 “Opus급” 모델입니다(2025년 11월 말 출시). 이 모델은 전문 소프트웨어 엔지니어링, 장기 에이전트형 워크플로, 고위험 엔터프라이즈 작업을 위한 최상위 모델로 포지셔닝되며, Anthropic은 높은 성능을 프로덕션 사용자들이 더 쉽게 활용할 수 있도록 의도적으로 가격을 책정했습니다. 아래에서는 Claude Opus 4.5 API가 무엇인지, 이 모델이 실제 엔지니어링 벤치마크에서 어떻게 성능을 보이는지, 가격 체계가 정확히 어떻게 작동하는지(API 및 구독), 기존 Anthropic 모델 및 경쟁사(OpenAI, Google Gemini)와 비교했을 때 어떤 차이가 있는지, 그리고 프로덕션 워크로드를 비용 효율적으로 운영하기 위한 실용적인 모범 사례를 정리합니다. 또한 그대로 복사해 실행할 수 있는 지원 코드와 소규모 벤치마킹 및 비용 계산 툴킷도 포함했습니다.
Claude Opus 4.5 API란 무엇인가요?
Claude Opus 4.5는 최신 Opus급 모델로, 전문 소프트웨어 엔지니어링, 에이전트형 도구 사용(즉, 외부 도구를 호출하고 조합하는 작업), 컴퓨터 사용 작업에 특화되도록 조정된 고성능 멀티모달 모델입니다. 이 모델은 확장 사고 기능(스트리밍할 수 있는 투명한 단계별 내부 추론)을 유지하면서, 세밀한 런타임 제어 기능(특히 effort 파라미터)을 추가했습니다. Anthropic은 이 모델을 프로덕션 에이전트, 코드 마이그레이션/리팩터링, 견고성과 낮은 반복 횟수가 필요한 엔터프라이즈 워크플로에 적합한 모델로 제시합니다.
핵심 API 기능과 개발자 UX
Opus 4.5는 다음을 지원합니다.
- 표준 텍스트 생성 + 높은 충실도의 지시 이행.
- 확장 사고 / 다단계 추론 모드(코딩, 긴 문서에 유용).
- 도구 사용(웹 검색, 코드 실행, 커스텀 도구), 메모리 및 프롬프트 캐싱.
- “Claude Code” 및 에이전트형 플로(코드베이스 전반의 다단계 작업 자동화).
Claude Opus 4.5의 성능은 어떤가요?
Opus 4.5는 소프트웨어 엔지니어링 벤치마크에서 최첨단 수준이며, **SWE-bench Verified에서 약 80.9%**를 기록했다고 주장하고, OSWorld 같은 “컴퓨터 사용” 벤치마크에서도 강력한 점수를 보입니다. 또한 Opus 4.5는 Sonnet 4.5와 동등하거나 그 이상의 성능을 더 적은 토큰 사용량으로 달성할 수 있습니다(즉, 토큰 효율성이 더 높습니다).
소프트웨어 엔지니어링 벤치마크(SWE-bench / Terminal Bench / Aider Polyglot): Anthropic은 Opus 4.5가 SWE-bench Verified에서 선두를 차지하고, Terminal Bench에서 Sonnet 4.5 대비 약 15% 향상되었으며, Aider Polyglot에서는 Sonnet 4.5 대비 10.6% 상승했다고 보고했습니다(사내 비교 기준).
장시간 자율 코딩: Anthropic에 따르면 Opus 4.5는 30분 자율 코딩 세션에서도 성능을 안정적으로 유지하며, 다단계 워크플로에서 막다른 경로에 빠지는 경우가 더 적습니다. 이는 에이전트 테스트 전반에서 반복적으로 확인된 사내 결과입니다.
실제 작업 개선(Vending-Bench / BrowseComp-Plus 등): Anthropic은 Sonnet 4.5 대비 Vending-Bench(장기 작업)에서 +29% 향상되었고, BrowseComp-Plus에서 에이전트형 검색 지표가 개선되었다고 밝혔습니다.
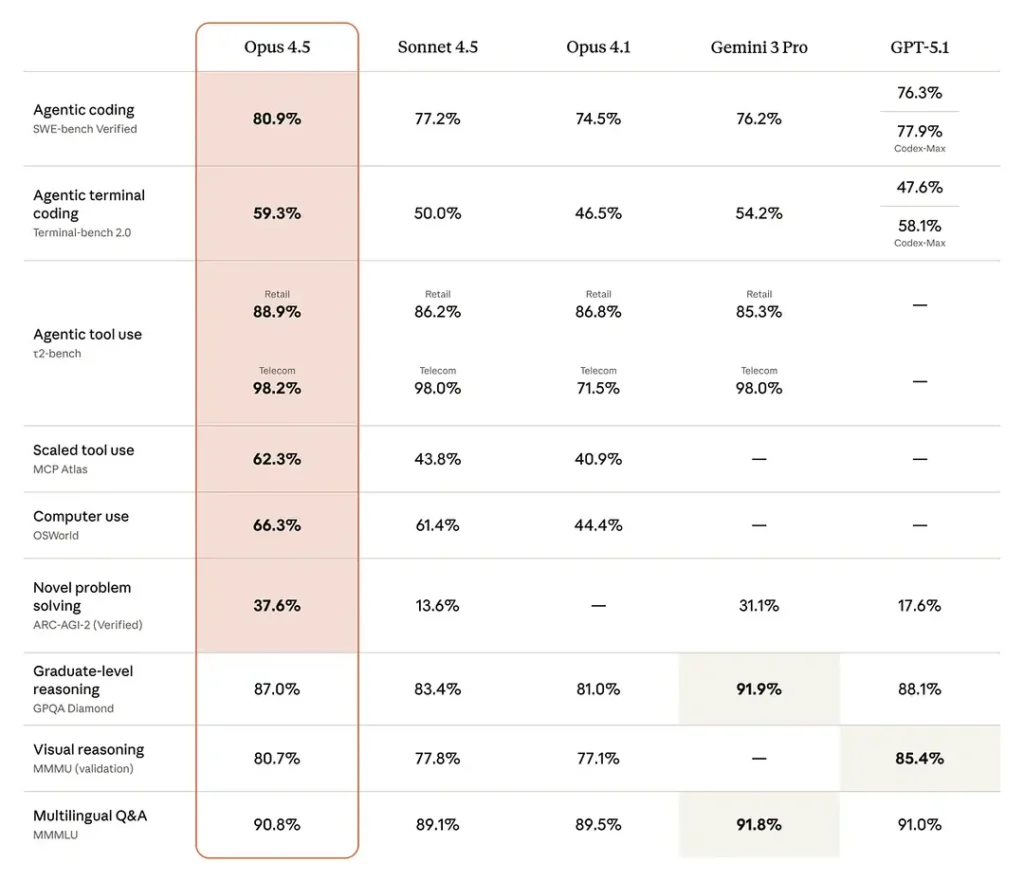
보고 내용을 통해 얻을 수 있는 몇 가지 구체적인 시사점은 다음과 같습니다.
- 코딩 리더십: Opus 4.5는 소프트웨어 엔지니어링 벤치마크 종합(SWE-bench Verified 및 Terminal-bench 변형)에서 이전 Opus/Sonnet 계열과 많은 동시대 경쟁 모델을 종종 능가합니다.
- 오피스 자동화: 리뷰어들은 더 나은 스프레드시트 생성과 PowerPoint 제작 성능을 강조하며, 이는 분석가와 제품 팀의 사후 편집 작업을 줄여 줍니다.
- 에이전트 및 도구 신뢰성: Opus 4.5는 다단계 에이전트형 워크플로와 장시간 실행 작업에서 개선되어, 다중 호출 파이프라인의 실패를 줄입니다.
Claude Opus 4.5의 비용은 얼마인가요?
이것이 당신이 물은 핵심 질문입니다. 아래에서는 API 가격 구조, 구독 등급, 비용 계산 예시, 그리고 실제 의미를 기준으로 나누어 설명합니다.
API 가격 구조 — Anthropic이 공개한 내용
Anthropic은 Opus 4.5의 API 가격을 다음과 같이 책정했습니다.
- 입력(토큰): 1,000,000 입력 토큰당 $5
- 출력(토큰): 1,000,000 출력 토큰당 $25
Anthropic은 이 가격이 Opus급 성능을 폭넓게 접근 가능하게 만들기 위한 의도적인 인하라고 명시했습니다. 개발자용 모델 식별자는 claude-opus-4-5-20251101 문자열입니다.
CometAPI에서는 Claude Opus 4.5 API가 Opus 4.5 기준으로 입력 1M 토큰당 $4, 출력 1M 토큰당 $20이며, 공식 Google 가격보다 약 20% 저렴합니다.
가격표(간략화, 백만 토큰당 USD)
| Model | Input ($ / MTok) | Output ($ / MTok) | Notes |
|---|---|---|---|
| Claude Opus 4.5 (base) | $5.00 | $25.00 | Anthropic 정가. |
| Claude Opus 4.1 | $15.00 | $75.00 | 이전 Opus 릴리스 — 더 높은 정가. |
| Claude Sonnet 4.5 | $3.00 | $15.00 | 많은 작업에 더 저렴한 계열. |
중요: 이 가격은 요청당이 아니라 토큰 기반입니다. 청구는 요청에서 소비된 토큰 수, 즉 입력(프롬프트 + 컨텍스트)과 출력(모델이 생성한 토큰) 모두를 기준으로 이루어집니다.
구독 플랜 및 앱 등급(consumer/Pro/Team)
API는 커스텀 빌드에 적합한 반면, Claude의 구독 플랜은 Opus 4.5 접근 권한을 UI 도구와 함께 묶어 제공하므로 대화형 시나리오에서는 토큰별 사용량에 대한 부담을 줄여 줍니다. 무료 플랜($0)은 기본 채팅과 Haiku/Sonnet 모델로 제한되며 Opus는 포함되지 않습니다.
Pro 플랜($20/월 또는 $17/년)과 Max 플랜(1인당 월 $100, Pro 사용량의 5배~20배 제공)은 Opus 4.5, Claude Code, 파일 실행, 무제한 프로젝트를 제공합니다.
토큰 사용량은 어떻게 최적화하나요?
effort를 적절히 사용: 일반적인 답변에는low, 꼭 필요할 때만high를 선택하세요.- 구조화된 출력과 스키마를 선호하여 장황한 왕복을 피하세요.
- Files API 사용으로 큰 문서를 프롬프트에 반복 전송하지 마세요.
- 컨텍스트를 프로그램적으로 압축 또는 요약한 뒤 전송하세요.
- 반복 응답을 캐시하고 프롬프트 입력이 동일하거나 유사할 때 재사용하세요.
실용적인 원칙: 초기에 사용량을 계측하고(요청당 토큰 추적), 대표 프롬프트로 부하 테스트를 수행하며, 최적화가 실제 ROI를 겨냥하도록 성공한 작업당 비용을 계산하세요(토큰당 비용이 아니라).
빠른 샘플 코드: Claude Opus 4.5 호출 + 비용 계산
아래는 그대로 복사해 사용할 수 있는 예시입니다: (1) curl, (2) Anthropic SDK를 사용하는 Python, (3) 측정된 입력/출력 토큰 수를 기반으로 비용을 계산하는 소규모 Python 헬퍼.
중요: API 키는 환경 변수에 안전하게 저장하세요. 예제는
ANTHROPIC_API_KEY가 설정되어 있다고 가정합니다. 표시된 모델 id는claude-opus-4-5-20251101(Anthropic)입니다.
1) cURL 예제(간단한 프롬프트)
curl https://api.anthropic.com/v1/complete \
-H "x-api-key: $ANTHROPIC_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model":"claude-opus-4-5-20251101",
"prompt":"You are an assistant. Given the following requirements produce a minimal Python function that validates emails. Return only code.",
"max_tokens": 600,
"temperature": 0.0
}'
2) Python (anthropic SDK) — 기본 요청
# pip install anthropic
import os
from anthropic import Anthropic, HUMAN_PROMPT, AI_PROMPT
client = Anthropic(api_key=os.getenv("ANTHROPIC_API_KEY"))
prompt = HUMAN_PROMPT + "Given the following requirements produce a minimal Python function that validates emails. Return only code.\n\nRequirements:\n- Python 3.10\n- Use regex\n" + AI_PROMPT
resp = client.completions.create(
model="claude-opus-4-5-20251101",
prompt=prompt,
max_tokens_to_sample=600,
temperature=0.0
)
print(resp.completion) # model output
참고: Anthropic의 Python SDK 명칭과 호출 시그니처는 달라질 수 있습니다. 위 예시는 공개 SDK와 문서의 일반적인 패턴을 따른 것입니다. 정확한 메서드 이름은 설치한 버전의 문서를 확인하세요. GitHub+1
3) 비용 계산기(Python) — 토큰 기준 비용 계산
def compute_claude_cost(input_tokens, output_tokens,
input_price_per_m=5.0, output_price_per_m=25.0):
"""
Compute USD cost for Anthropic Opus 4.5 given token counts.
input_price_per_m and output_price_per_m are dollars per 1,000,000 tokens.
"""
cost_input = (input_tokens / 1_000_000) * input_price_per_m
cost_output = (output_tokens / 1_000_000) * output_price_per_m
return cost_input + cost_output
# Example: 20k input tokens and 5k output tokens
print(compute_claude_cost(20000, 5000)) # => ~0.225 USD
팁: 실제 요청의 토큰 수는 서버 로그 / 제공자 텔레메트리로 측정하세요. 로컬에서 정확한 토큰화 수치가 필요하다면 Claude의 토큰화 방식과 호환되는 토크나이저를 사용하거나, 가능할 경우 제공자의 토큰 카운터를 활용하세요.
언제 Opus 4.5를 선택하고, 언제 더 저렴한 모델을 선택해야 하나요?
다음과 같은 경우 Opus 4.5를 사용하세요.
- 첫 시도에서의 정확성이 실질적으로 중요한 미션 크리티컬 엔지니어링 워크로드가 있을 때(복잡한 코드 생성, 아키텍처 제안, 장시간 에이전트형 실행).
- 하나의 워크플로 안에서 도구 오케스트레이션이나 깊은 다단계 추론이 필요할 때. 프로그래밍 방식의 도구 호출은 핵심 차별점입니다.
- 사람의 검토 루프를 줄이려는 경우 — 모델의 높은 첫 통과 정확도는 후속 인적 시간을 줄여 총비용을 낮출 수 있습니다.
다음과 같은 경우 Sonnet / Haiku 또는 경쟁 모델을 고려하세요.
- 저렴한 토큰 비용과 높은 처리량이 중요한 대화량이 많고, 고위험이 아닌 요약 작업. Sonnet(균형형) 또는 Haiku(경량형)가 더 비용 효율적일 수 있습니다.
- 일부 성능/정확도 저하를 감수하고라도 절대적으로 가장 저렴한 토큰당 비용이 필요할 때(예: 단순 요약, 기본 어시스턴트).
Opus 4.5용 프롬프트는 어떻게 설계해야 하나요?
어떤 메시지 역할과 프리필 전략이 가장 효과적인가요?
세 부분 패턴을 사용하세요.
- System (
role: system): 전역 지시사항 — 어조, 가드레일, 역할. - Assistant (선택 사항): 예시 또는 프라이밍 콘텐츠.
- User (
role: user): 즉각적인 요청.
원하는 출력 형식, 길이, 안전 정책, JSON 스키마가 있다면 system 메시지에 제약 조건을 미리 넣으세요. 에이전트의 경우 Opus 4.5가 도구를 정확히 호출할 수 있도록 도구 사양과 사용 예시를 포함하세요.
컨텍스트 압축과 프롬프트 캐싱으로 어떻게 토큰을 절약하나요?
- 컨텍스트 압축: 대화의 이전 부분을 모델이 여전히 활용할 수 있는 간결한 요약으로 압축합니다. Opus 4.5는 핵심 추론 블록을 잃지 않으면서 컨텍스트를 압축하는 자동화를 지원합니다.
- 프롬프트 캐싱: 반복되는 프롬프트에 대해 모델 응답을 캐시합니다(Anthropic은 지연 시간/비용 절감을 위한 프롬프트 캐싱 패턴을 제공합니다).
두 기능 모두 긴 상호작용의 토큰 사용량을 줄여 주며, 장시간 실행 에이전트 워크플로와 프로덕션 어시스턴트에 권장됩니다.
모범 사례: 비용을 통제하면서 Opus급 결과 얻기
1) 프롬프트와 컨텍스트 최적화
- 불필요한 컨텍스트를 최소화하세요 — 필요한 이력만 보내세요. 긴 왕복 대화가 예상되면 이전 대화를 자르고 요약하세요.
- 검색/임베딩 + RAG를 사용해 특정 질의에 필요한 문서만 가져오세요(전체 코퍼스를 프롬프트 토큰으로 보내는 대신). Anthropic 문서도 토큰 비용 절감을 위해 RAG와 프롬프트 캐싱을 권장합니다.
2) 가능한 경우 응답을 캐시하고 재사용
프롬프트 캐싱: 많은 요청이 동일하거나 거의 동일한 프롬프트를 갖는다면, 매번 모델을 다시 호출하는 대신 출력을 캐시하고 캐시된 버전을 제공하세요. Anthropic 문서도 프롬프트 캐싱을 비용 최적화 수단으로 명시합니다.
3) 작업에 맞는 모델 선택
- 사람이 다시 손봐야 하는 비용이 큰 비즈니스 핵심 고가치 작업에는 Opus 4.5를 사용하세요.
- 고용량, 저위험 작업에는 Sonnet 4.5 또는 Haiku 4.5를 사용하세요. 이런 혼합 모델 전략은 전체 스택에서 더 나은 가격/성능을 제공합니다.
4) max tokens와 스트리밍 제어
출력이 장황할 필요가 없다면 max_tokens_to_sample를 제한하세요. 지원되는 경우 스트리밍을 사용하여 조기에 생성을 중단하고 출력 토큰 비용을 절감하세요.
최종 의견: 지금 Opus 4.5를 도입할 가치가 있을까요?
Opus 4.5는 더 높은 충실도의 추론, 긴 상호작용에서 더 낮은 토큰 비용, 더 안전하고 견고한 에이전트 동작이 필요한 조직에게 의미 있는 진전입니다. 제품이 지속적인 추론(복잡한 코드 작업, 자율 에이전트, 심층 리서치 종합, 무거운 Excel 자동화)에 의존한다면, Opus 4.5는 실제 성능과 비용을 조정할 수 있는 추가적인 제어 수단(effort, 확장 사고, 향상된 도구 처리)을 제공합니다.
개발자는 Claude Opus 4.5 API를 통해 CometAPI에서 Claude Opus 4.5 API에 접근할 수 있습니다. 시작하려면 CometAPI의 Playground에서 모델 기능을 살펴보고, 자세한 안내를 위해 API 가이드를 참고하세요. 사용 전에 CometAPI에 로그인하고 API 키를 발급받았는지 확인해 주세요. CometAPI는 통합을 돕기 위해 공식 가격보다 훨씬 낮은 가격을 제공합니다.
Ready to Go?→ 지금 CometAPI에 가입하세요 !