

On November 19–20, 2025 OpenAI는 서로 관련되어 있지만 구별되는 두 가지 업그레이드를 출시했습니다: GPT-5.1-Codex-Max는 Codex용 새로운 에이전트형 코딩 모델로, 장기적 코딩, 토큰 효율성, 그리고 다중 창 세션을 지속하기 위한 “compaction”을 강조합니다. GPT-5.1 Pro는 복잡하고 전문적인 작업에서 더 명확하고 더 유능한 답변을 제공하도록 조정된 Pro 등급 ChatGPT 모델의 업데이트 버전입니다.
GPT-5.1-Codex-Max란 무엇이며, 어떤 문제를 해결하려고 하나요?
GPT-5.1-Codex-Max는 지속적이고 장기적인 추론 및 실행이 필요한 코딩 워크플로에 맞게 조정된 OpenAI의 특화된 Codex 모델입니다. 일반적인 모델은 매우 긴 컨텍스트에서 어려움을 겪을 수 있습니다. 예를 들어, 여러 파일에 걸친 리팩터링, 복잡한 에이전트 루프, 또는 지속적인 CI/CD 작업 같은 경우입니다. Codex-Max는 여러 컨텍스트 창에 걸쳐 세션 상태를 자동으로 압축하고 관리하도록 설계되어, 하나의 프로젝트가 수천 개 이상의 토큰에 걸쳐 확장되더라도 일관성 있게 작업을 계속할 수 있습니다. OpenAI는 Codex-Max를 코드 작업이 가능한 에이전트를 장시간의 엔지니어링 업무에 진정으로 유용하게 만드는 다음 단계로 설명합니다.
GPT-5.1-Codex-Max란 무엇이며, 어떤 문제를 해결하려고 하나요?
GPT-5.1-Codex-Max는 지속적이고 장기적인 추론 및 실행이 필요한 코딩 워크플로에 맞게 조정된 OpenAI의 특화된 Codex 모델입니다. 일반적인 모델은 매우 긴 컨텍스트에서 어려움을 겪을 수 있습니다. 예를 들어, 여러 파일에 걸친 리팩터링, 복잡한 에이전트 루프, 또는 지속적인 CI/CD 작업 같은 경우입니다. Codex-Max는 여러 컨텍스트 창에 걸쳐 세션 상태를 자동으로 압축하고 관리하도록 설계되어, 하나의 프로젝트가 수천 개 이상의 토큰에 걸쳐 확장되더라도 일관성 있게 작업을 계속할 수 있습니다.
OpenAI는 이를 “개발 주기의 모든 단계에서 더 빠르고, 더 지능적이며, 더 토큰 효율적”이라고 설명하며, Codex 환경에서 기본 모델로 GPT-5.1-Codex를 대체하도록 명시적으로 설계되었다고 밝히고 있습니다.
기능 요약
- 다중 창 연속성을 위한 compaction: 핵심 컨텍스트를 선별하고 보존하여 수백만 개의 토큰과 수시간에 걸쳐 일관되게 작업합니다. 0
- GPT-5.1-Codex 대비 향상된 토큰 효율성: 일부 코드 벤치마크에서 유사한 추론 작업에 대해 최대 ~30% 더 적은 thinking tokens 사용.
- 장기 지향 에이전트 내구성: 내부적으로 수시간/수일에 걸친 에이전트 루프를 유지하는 것이 관찰되었으며(OpenAI는 24시간 초과 내부 실행 사례를 문서화함).
- 플랫폼 통합: 현재 Codex CLI, IDE 확장, 클라우드, 코드 리뷰 도구에서 이용 가능하며, API 접근은 추후 제공 예정.
- Windows 환경 지원: OpenAI는 Codex 워크플로에서 처음으로 Windows를 지원한다고 명시했으며, 이를 통해 실제 개발자 도달 범위를 넓혔습니다.
경쟁 제품(예: GitHub Copilot, 기타 코딩 AI)과 비교하면 어떤가요?
GPT-5.1-Codex-Max는 요청 단위 완성 도구보다 더 자율적이고 장기 지향적인 협업자로 포지셔닝됩니다. Copilot 및 유사한 도우미가 에디터 내 단기 완성에 뛰어난 반면, Codex-Max의 강점은 다단계 작업을 조율하고, 세션 전반에 걸쳐 일관된 상태를 유지하며, 계획·테스트·반복이 필요한 워크플로를 처리하는 데 있습니다. 다만 대부분의 팀에 가장 좋은 접근 방식은 하이브리드일 것입니다. 복잡한 자동화 및 지속적인 에이전트 작업에는 Codex-Max를 사용하고, 줄 단위 완성에는 더 가벼운 도우미를 사용하는 방식입니다.
GPT-5.1-Codex-Max는 어떻게 작동하나요?
“compaction”이란 무엇이며, 장시간 작업을 어떻게 가능하게 하나요?
핵심적인 기술적 발전은 compaction입니다. 이는 세션 기록을 선별하면서도 중요한 컨텍스트를 보존해 모델이 여러 컨텍스트 창에 걸쳐 일관된 작업을 계속할 수 있도록 하는 내부 메커니즘입니다. 실제로는 Codex 세션이 컨텍스트 한계에 가까워질 때 압축이 수행되어(오래되었거나 가치가 낮은 토큰은 요약/보존), 에이전트가 새로운 창을 확보하고 작업이 완료될 때까지 반복적으로 계속 작업할 수 있게 됩니다. OpenAI는 모델이 24시간 이상 연속으로 작업한 내부 실행 사례를 보고했습니다.
적응형 추론과 토큰 효율성
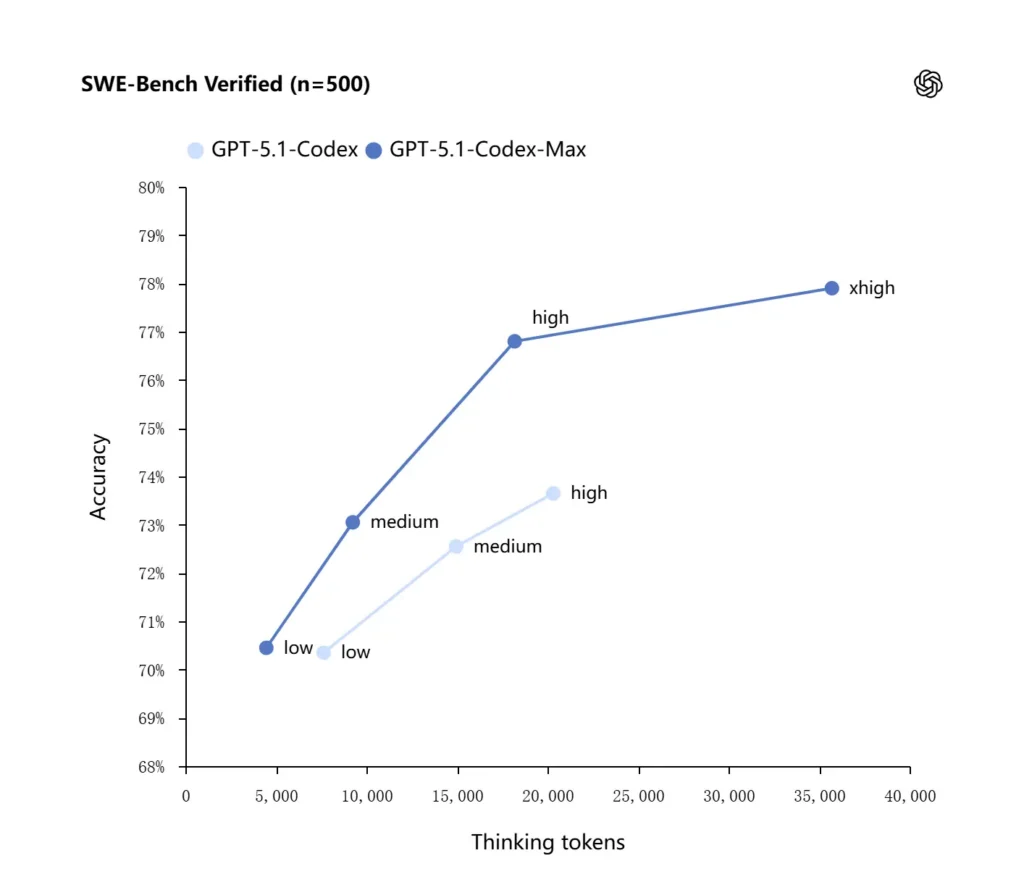
GPT-5.1-Codex-Max는 더 나은 추론 전략을 적용해 토큰 효율성을 높입니다. OpenAI의 내부 벤치마크에 따르면, Max 모델은 GPT-5.1-Codex와 비슷하거나 더 나은 성능을 내면서도 훨씬 적은 “thinking” 토큰을 사용합니다. OpenAI는 동일한 추론 노력 수준으로 실행했을 때 SWE-bench Verified에서 대략 30% 더 적은 thinking tokens를 사용한다고 밝혔습니다. 또한 이 모델은 지연 시간에 덜 민감한 작업을 위한 “Extra High (xhigh)” 추론 노력 모드를 도입해, 더 높은 품질의 출력을 얻기 위해 더 많은 내부 추론을 사용할 수 있게 합니다.
시스템 통합과 에이전트형 도구
Codex-Max는 Codex 워크플로(CLI, IDE 확장, 클라우드, 코드 리뷰 환경) 내에서 배포되어 실제 개발자 도구 체인과 상호작용할 수 있도록 설계되었습니다. 초기 통합에는 Codex CLI와 IDE 에이전트(VS Code, JetBrains 등)가 포함되며, API 접근도 이후 제공될 예정입니다. 설계 목표는 더 똑똑한 코드 생성에 그치지 않고, 파일 열기, 테스트 실행, 실패 수정, 리팩터링, 재실행 같은 다단계 워크플로를 수행할 수 있는 AI를 만드는 것입니다.
GPT-5.1-Codex-Max는 벤치마크와 실제 업무에서 어떻게 성능을 보이나요?
지속적 추론과 장기 과제
평가 결과는 지속적 추론과 장기 과제에서 측정 가능한 개선을 보여줍니다.
- OpenAI 내부 평가: Codex-Max는 내부 실험에서 “24시간 이상” 작업을 수행할 수 있었고, Codex를 개발자 도구와 통합했을 때 내부 엔지니어링 생산성 지표(예: 사용량 및 풀 리퀘스트 처리량)가 증가했다고 합니다. 이는 OpenAI의 내부 주장으로, 실제 생산성에서 과제 단위 개선을 시사합니다.
- 독립 평가(METR): METR의 독립 보고서는 GPT-5.1-Codex-Max의 관측된 50% 시간 지평선(모델이 장기 작업을 일관되게 유지할 수 있는 중앙값 시간 통계)을 약 2시간 40분으로 측정했으며(신뢰구간은 넓음), 이는 유사한 측정에서 GPT-5의 2시간 17분보다 증가한 수치입니다. 이는 지속적 일관성 측면에서 의미 있는 추세상 개선입니다. METR의 방법론과 신뢰구간은 변동성을 강조하지만, 이 결과는 Codex-Max가 실질적인 장기 성능을 향상시킨다는 서사를 뒷받침합니다.
코드 벤치마크
OpenAI는 최첨단 코딩 평가, 특히 SWE-bench Verified에서 GPT-5.1-Codex-Max가 GPT-5.1-Codex보다 더 나은 토큰 효율성과 함께 향상된 결과를 보였다고 보고합니다. 회사는 동일한 “medium” 추론 노력에서 Max 모델이 대략 30% 더 적은 thinking tokens를 사용하면서 더 좋은 결과를 낸다고 강조합니다. 더 긴 내부 추론을 허용하는 사용자에게는 xhigh 모드가 지연 시간의 대가로 응답 품질을 더 높일 수 있습니다.
| GPT‑5.1-Codex (high) | GPT‑5.1-Codex-Max (xhigh) | |
| SWE-bench Verified (n=500) | 73.7% | 77.9% |
| SWE-Lancer IC SWE | 66.3% | 79.9% |
| Terminal-Bench 2.0 | 52.8% | 58.1% |
GPT-5.1-Codex-Max는 GPT-5.1-Codex와 어떻게 비교되나요?
성능 및 목적 차이
- 범위: GPT-5.1-Codex는 GPT-5.1 계열의 고성능 코딩 변형이었고, Codex-Max는 Codex 및 Codex 유사 환경에서 권장 기본값이 되도록 설계된, 명시적으로 에이전트형이고 장기 지향적인 후속 모델입니다.
- 토큰 효율성: Codex-Max는 SWE-bench 및 내부 사용에서 의미 있는 토큰 효율 향상(OpenAI의 ~30% 적은 thinking tokens 주장)을 보여줍니다.
- 컨텍스트 관리: Codex-Max는 단일 컨텍스트 창을 초과하는 작업을 지속하기 위해 compaction과 기본적인 다중 창 처리를 도입했습니다. Codex는 같은 규모에서 이러한 기능을 기본 제공하지 않았습니다.
- 도구 준비도: Codex-Max는 CLI, IDE, 코드 리뷰 환경 전반에서 기본 Codex 모델로 제공되며, 이는 실제 프로덕션 개발 워크플로의 전환을 시사합니다.
어떤 경우에 어떤 모델을 사용해야 하나요?
- GPT-5.1-Codex 사용: 대화형 코딩 지원, 빠른 수정, 작은 리팩터링, 그리고 전체 관련 컨텍스트가 단일 창에 쉽게 들어가는 저지연 사용 사례에 적합합니다.
- GPT-5.1-Codex-Max 사용: 여러 파일에 걸친 리팩터링, 많은 반복 주기가 필요한 자동화된 에이전트형 작업, CI/CD 유사 워크플로, 또는 많은 상호작용 전반에 걸쳐 프로젝트 수준의 관점을 유지해야 하는 경우에 적합합니다.
실용적인 프롬프트 패턴과 최상의 결과를 위한 예시는 무엇인가요?
잘 작동하는 프롬프트 패턴
- 목표와 제약 조건을 명확히 제시하세요: “X를 리팩터링하고, 공개 API는 유지하고, 함수 이름은 유지하며, 테스트 A,B,C가 통과하도록 하라.”
- 최소 재현 가능한 컨텍스트를 제공하세요: 전체 리포지토리를 한꺼번에 넣기보다는 실패한 테스트 링크, 스택 트레이스, 관련 파일 조각을 포함하세요. Codex-Max는 필요에 따라 기록을 압축합니다.
- 복잡한 작업에는 단계별 지시를 사용하세요: 큰 작업을 일련의 하위 작업으로 나누고, Codex-Max가 이를 반복적으로 수행하게 하세요(예: “1) 테스트 실행 2) 가장 많이 실패하는 상위 3개 테스트 수정 3) linter 실행 4) 변경 사항 요약”).
- 설명과 diff를 함께 요청하세요: 사람이 검토할 때 안전성과 의도를 빠르게 평가할 수 있도록 패치와 짧은 근거를 함께 요청하세요.
예시 프롬프트 템플릿
리팩터링 작업
“
payment/모듈을 리팩터링하여 결제 처리를payment/processor.py로 추출하라. 기존 호출자를 위해 공개 함수 시그니처는 안정적으로 유지하라.process_payment()에 대해 성공, 네트워크 실패, 유효하지 않은 카드 사례를 다루는 단위 테스트를 작성하라. 테스트 스위트를 실행하고, 실패한 테스트와 unified diff 형식의 패치를 반환하라.”
버그 수정 + 테스트
“테스트
tests/test_user_auth.py::test_token_refresh가 traceback 과 함께 실패한다. 근본 원인을 조사하고, 최소한의 변경으로 수정안을 제안하며, 회귀를 방지하기 위한 단위 테스트를 추가하라. 패치를 적용하고 테스트를 실행하라.”
반복적 PR 생성
“기능 X를 구현하라: 내보내기 결과를 스트리밍하고 인증되는 엔드포인트
POST /api/export를 추가하라. 엔드포인트를 만들고, 문서를 추가하고, 테스트를 작성하고, 요약과 수동 확인 항목 체크리스트가 포함된 PR을 열어라.”
이러한 작업 대부분에서는 medium 노력 수준으로 시작하고, 여러 파일과 여러 차례의 테스트 반복에 걸친 깊은 추론이 필요할 때는 xhigh로 전환하세요.
GPT-5.1-Codex-Max에 어떻게 접근하나요
현재 사용 가능한 위치
OpenAI는 현재 Codex 도구 체계에 GPT-5.1-Codex-Max를 통합했습니다. Codex CLI, IDE 확장, 클라우드, 코드 리뷰 흐름에서 Codex-Max가 기본으로 사용됩니다(Codex-Mini를 선택할 수도 있음). API 제공은 준비 중이며, GitHub Copilot은 GPT-5.1 및 Codex 계열 모델이 포함된 공개 프리뷰를 제공하고 있습니다.
개발자는 CometAPI를 통해 GPT-5.1-Codex-Max와 GPT-5.1-Codex API에 접근할 수 있습니다. 시작하려면 CometAPI의 Playground에서 모델 기능을 살펴보고, 자세한 지침은 API 가이드를 참조하세요. 접근하기 전에 CometAPI에 로그인하고 API 키를 발급받았는지 확인해 주세요. CometAPI는 통합을 돕기 위해 공식 가격보다 훨씬 낮은 가격을 제공합니다.
바로 시작할 준비가 되셨나요?→ 지금 CometAPI에 가입하세요 !
AI에 대한 더 많은 팁, 가이드, 뉴스를 알고 싶다면 VK, X, Discord에서 저희를 팔로우하세요!
빠른 시작(실용적인 단계별 안내)
- 접근 권한이 있는지 확인하세요: ChatGPT/Codex 제품 플랜(Plus, Pro, Business, Edu, Enterprise) 또는 개발자 API 플랜이 GPT-5.1/Codex 계열 모델을 지원하는지 확인하세요.
- Codex CLI 또는 IDE 확장을 설치하세요: 로컬에서 코드 작업을 실행하려면 Codex CLI 또는 VS Code / JetBrains / Xcode용 Codex IDE 확장을 설치하세요. 지원되는 설정에서는 도구가 기본적으로 GPT-5.1-Codex-Max를 사용합니다.
- 추론 노력 수준을 선택하세요: 대부분의 작업에서는 medium으로 시작하세요. 심층 디버깅, 복잡한 리팩터링, 또는 응답 지연 시간을 신경 쓰지 않고 모델이 더 깊게 생각하길 원한다면 high 또는 xhigh 모드로 전환하세요. 빠르고 작은 수정에는 low도 적절합니다.
- 리포지토리 컨텍스트를 제공하세요: 모델에 명확한 시작점을 주세요 — 리포지토리 URL 또는 파일 세트와 짧은 지시문(예: “결제 모듈을 async I/O를 사용하도록 리팩터링하고 단위 테스트를 추가하되, 함수 수준 계약은 유지하라”). Codex-Max는 컨텍스트 한계에 가까워지면 기록을 압축하고 작업을 계속합니다.
- 테스트와 함께 반복하세요: 모델이 패치를 생성한 후 테스트 스위트를 실행하고, 실패 내용을 진행 중인 세션의 일부로 다시 제공하세요. compaction과 다중 창 연속성을 통해 Codex-Max는 중요한 실패 테스트 컨텍스트를 유지하면서 반복할 수 있습니다.
결론:
GPT-5.1-Codex-Max는 향상된 효율성과 추론 능력으로 복잡하고 장시간 지속되는 엔지니어링 작업을 수행할 수 있는 에이전트형 코딩 도우미를 향한 중요한 진전을 보여줍니다. 기술적 발전(compaction, 추론 노력 모드, Windows 환경 학습)은 이 모델을 현대 엔지니어링 조직에 특히 적합하게 만들지만, 팀은 보수적인 운영 통제, 명확한 human-in-the-loop 정책, 강력한 모니터링과 함께 이를 도입해야 합니다. 신중하게 채택하는 팀에게 Codex-Max는 소프트웨어가 설계되고, 테스트되고, 유지보수되는 방식을 바꿀 잠재력이 있습니다. 즉, 반복적인 엔지니어링 잡무를 인간과 모델 간의 더 높은 가치의 협업으로 전환할 수 있습니다.