

DeepSeek는 V3.x 라인의 후속작으로 DeepSeek V3.2를 출시했고, 에이전트/도구 사용을 위한 고성능, 추론 우선 에디션으로 포지셔닝된 DeepSeek-V3.2-Speciale 변형도 함께 공개했다. V3.2는 실험적 작업(V3.2-Exp)을 기반으로 더 높은 추론 능력, “골드급” 수학/경진 프로그래밍 성능에 최적화된 Speciale 에디션, 그리고 DeepSeek이 처음이라 설명하는 듀얼 모드 “사고 + 도구” 시스템을 도입해 내부 단계별 추론을 외부 도구 호출 및 에이전트 워크플로와 긴밀히 통합한다.
DeepSeek V3.2란 무엇이며 V3.2-Speciale는 어떻게 다른가?
DeepSeek-V3.2는 DeepSeek의 실험적 V3.2-Exp 브랜치의 공식 후속작이다. DeepSeek은 이를 “추론 우선” 에이전트를 위해 구축된 모델 계열로 설명한다. 즉, 자연스러운 대화 품질뿐 아니라, 외부 도구(API, 코드 실행, 데이터 커넥터)가 포함된 환경에서 다단계 추론, 도구 호출, 신뢰할 수 있는 연쇄적 사고 스타일의 추론을 수행하도록 특별히 튜닝된 모델이다.
DeepSeek-V3.2(베이스)란
- V3.2-Exp 실험 라인의 주류 프로덕션 후속작으로 포지셔닝되며, DeepSeek의 앱/웹/API를 통해 폭넓게 제공될 예정.
- 에이전트 작업을 위한 견고한 추론과 연산 효율성 간의 균형을 유지.
DeepSeek-V3.2-Speciale란
DeepSeek-V3.2-Speciale는 대회 수준의 추론, 고급 수학, 에이전트 성능에 맞춰 조정된 더 높은 역량의 “스페셜 에디션”으로 DeepSeek이 마케팅하는 변형 모델이다. “추론 능력의 경계를 확장한다”고 하는 상위 성능 변형으로 포지셔닝된다. 현재 DeepSeek는 Speciale을 API 전용 모델로 임시 액세스 라우팅과 함께 공개하고 있으며, 초기 벤치마크는 추론 및 코딩 벤치마크에서 고급 폐쇄형 모델들과 경쟁하는 위치에 있음을 시사한다.
V3.2로 이어진 계보와 엔지니어링 선택은?
V3.2는 DeepSeek이 2025년에 공개한 반복적 엔지니어링의 계보를 잇는다: V3 → V3.1(Terminus) → V3.2-Exp(실험적 단계) → V3.2 → V3.2-Speciale. 실험적 V3.2-Exp는 DeepSeek Sparse Attention(DSA) — 매우 긴 컨텍스트 길이에서도 출력 품질을 유지하면서 메모리와 연산 비용을 낮추기 위한 미세한 희소 어텐션 메커니즘 — 을 도입했다. 이러한 DSA 연구와 비용 절감 작업은 공식 V3.2 계열을 위한 기술적 디딤돌이 되었다.
공식 DeepSeek 3.2의 새로운 점은?
1) 향상된 추론 능력 — 어떻게 개선되었나?
DeepSeek는 V3.2를 **“추론 우선”**으로 내세운다. 이는 아키텍처와 파인튜닝이 다단계 추론을 안정적으로 수행하고 내부 연쇄 사고를 유지하며, 외부 도구를 올바르게 사용하는 데 필요한 구조화된 숙고를 지원하도록 초점을 맞춘다는 뜻이다.
구체적으로 다음과 같은 개선이 포함된다:
- 명시적인 단계별 문제 해결과 안정적인 중간 상태를 유도하도록 조정된 학습과 RLHF(또는 유사한 정렬 절차) — 수학적 추론, 다단계 코드 생성, 논리 작업에 유용.
- 더 긴 컨텍스트 윈도우를 보존하고 이전 추론 단계를 정확하게 참조할 수 있게 하는 아키텍처 및 손실 함수 선택.
- 같은 모델이 더 빠른 “채팅” 스타일 모드 또는 실행 전에 중간 단계를 의도적으로 거치는 “사고” 모드로 동작할 수 있게 하는 실용적 모드(아래 “듀얼 모드” 참조).
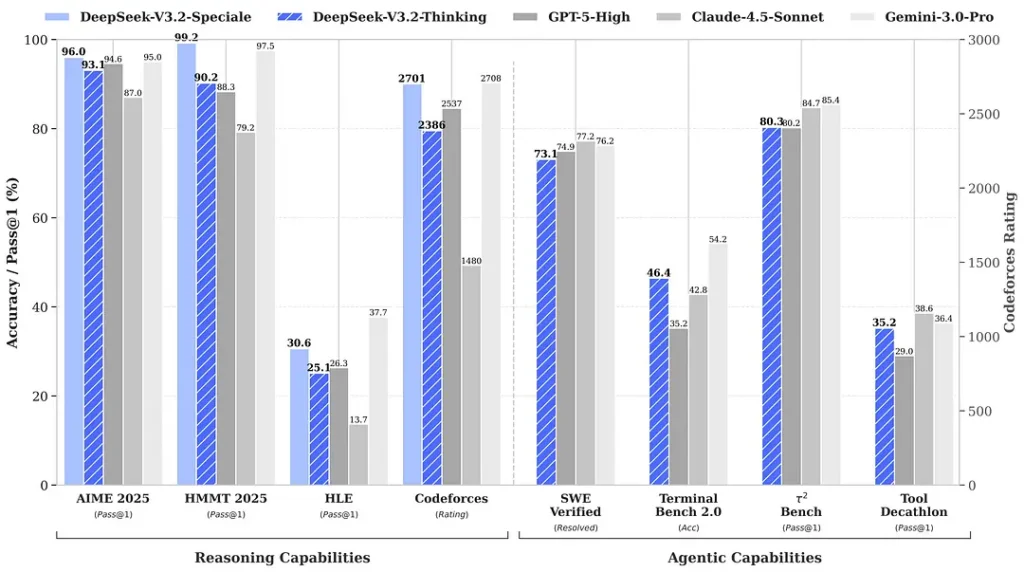
출시 시점에 인용된 벤치마크는 수학과 추론 세트에서 눈에 띄는 향상을 주장하며, 커뮤니티의 초기 독립 벤치마크도 경쟁적 평가 세트에서 인상적인 점수를 보고한다:
2) 스페셜 에디션의 돌파적 성능 — 얼마나 더 나아졌나?
DeepSeek-V3.2-Speciale는 표준 V3.2에 비해 추론 정확도와 에이전트 오케스트레이션에서 한 단계 향상된 성능을 제공한다고 주장된다. 제공자는 Speciale을 고난도의 추론 작업 부하와 도전적인 에이전트 과업을 목표로 한 성능 티어로 규정하며, 현재는 API 전용으로 한시적 상위 역량 엔드포인트로 제공된다(DeepSeek는 Speciale의 초기 제공이 제한적일 것이라고 밝혔다). Speciale 버전은 이전 수학 모델 DeepSeek-Math-V2를 통합했으며, 스스로 수학 정리를 증명하고 논리적 추론을 검증할 수 있다. 또한 여러 세계적 대회에서 놀라운 성과를 달성했다:
- 🥇 IMO(International Mathematical Olympiad) 금메달
- 🥇 CMO(Chinese Mathematical Olympiad) 금메달
- 🥈 ICPC(International Computer Programming Contest) 준우승(인간 대회)
- 🥉 IOI(International Olympiad in Informatics) 10위(인간 대회)
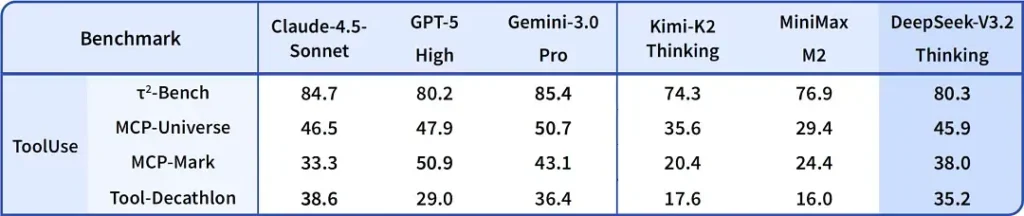
| 벤치마크 | GPT-5 High | Gemini-3.0 Pro | Kimi-K2 Thinking | DeepSeek-V3.2 Thinking | DeepSeek-V3.2 Speciale |
|---|---|---|---|---|---|
| AIME 2025 | 94.6 (13k) | 95.0 (15k) | 94.5 (24k) | 93.1 (16k) | 96.0 (23k) |
| HMMT Feb 2025 | 88.3 (16k) | 97.5 (16k) | 89.4 (31k) | 92.5 (19k) | 99.2 (27k) |
| HMMT Nov 2025 | 89.2 (20k) | 93.3 (15k) | 89.2 (29k) | 90.2 (18k) | 94.4 (25k) |
| IMOAnswerBench | 76.0 (31k) | 83.3 (18k) | 78.6 (37k) | 78.3 (27k) | 84.5 (45k) |
| LiveCodeBench | 84.5 (13k) | 90.7 (13k) | 82.6 (29k) | 83.3 (16k) | 88.7 (27k) |
| CodeForces | 2537 (29k) | 2708 (22k) | — | 2386 (42k) | 2701 (77k) |
| GPQA Diamond | 85.7 (8k) | 91.9 (8k) | 84.5 (12k) | 82.4 (7k) | 85.7 (16k) |
| HLE | 26.3 (15k) | 37.7 (15k) | 23.9 (24k) | 25.1 (21k) | 30.6 (35k) |
3) “사고 + 도구” 듀얼 모드 시스템의 사상 최초 구현
V3.2에서 가장 실용적으로 흥미로운 주장 중 하나는 빠른 대화형 동작과 느리지만 숙고적인 “사고” 모드를 분리(그리고 선택)할 수 있는 듀얼 모드 워크플로다. 이는 도구 사용과의 긴밀한 통합을 제공한다.
- “채팅/고속” 모드: 사용자 지향 대화에서 낮은 지연과 간결한 응답을 위해 설계되며 내부 추론 흔적을 줄였다 — 캐주얼한 도움, 짧은 Q&A, 속도가 중요한 애플리케이션에 적합.
- “사고/추론” 모드: 엄격한 연쇄 사고, 단계별 계획 수립, 외부 도구(API, 데이터베이스 질의, 코드 실행) 오케스트레이션에 최적화. 사고 모드에서 모델은 보다 명시적인 중간 단계를 산출하며, 이는 점검하거나 에이전틱 시스템에서 안전하고 올바른 도구 호출을 구동하는 데 사용할 수 있다.
이 패턴(2가지 모드 설계)은 이전의 실험적 브랜치에도 존재했으며, DeepSeek는 이를 V3.2와 Speciale에 더욱 깊이 통합했다 — Speciale은 현재 사고 모드만을 지원한다(따라서 API 게이팅이 존재). 속도와 숙고 사이를 전환할 수 있는 능력은, 실세계 시스템과 상호작용해야 하는 에이전트를 구축할 때 지연 시간과 신뢰성 사이의 적절한 절충을 개발자가 선택할 수 있게 해 주므로 엔지니어링에 매우 유용하다.
주목할 점: 많은 최신 시스템은 강력한 연쇄 사고 모델(추론 설명)이나 별도의 에이전트/도구 오케스트레이션 레이어 중 하나만 제공한다. DeepSeek의 프레이밍은 더 긴밀한 결합을 시사한다 — 모델이 “생각”한 다음 결정적으로 도구를 호출하고, 도구의 응답을 이후 사고에 반영할 수 있어, 자율 에이전트를 구축하는 개발자에게 더 매끄럽다.
DeepSeek v3.2를 얻는 방법
간단히 말해 — 필요에 따라 여러 방법으로 DeepSeek v3.2를 이용할 수 있다:
- 공식 웹/앱(온라인 사용) — DeepSeek 웹 인터페이스나 모바일 앱에서 V3.2를 상호작용적으로 사용해 보라.
- API 액세스 — DeepSeek는 API를 통해 V3.2를 제공한다(문서에는 모델 이름/
base_url및 가격이 포함). API 키를 신청하고 v3.2 엔드포인트를 호출하라. - 다운로드/오픈 가중치(Hugging Face) — 모델(V3.2 / V3.2-Exp 변형)은 Hugging Face에 게시되어 있으며(오픈 웨이트) 다운로드할 수 있다. 파일은
huggingface-hub또는transformers로 가져오라. - CometAPI — AI API 집합 플랫폼으로 V3.2-Exp의 호스팅 엔드포인트를 제공한다. 가격은 공식가보다 저렴하다.
몇 가지 실용적 참고 사항:
- 로컬에서 실행할 가중치가 필요하다면, Hugging Face 모델 페이지로 이동(그곳의 라이선스/액세스 조건을 수락)하여
huggingface-cli또는transformers를 사용해 다운로드하라; GitHub 리포지토리에는 보통 정확한 명령이 안내된다. - 프로덕션 용도의 API 사용이 필요하다면, CometAPI와 같은 플랫폼의 API 문서를 참고하여 엔드포인트 이름과 V3.2 변형에 대한 올바른
base_url을 확인하라.
DeepSeek-V3.2-Speciale:* 연구용으로만 공개, “Thinking Mode” 대화를 지원하지만 도구 호출은 지원하지 않음.
- 최대 출력은 128K tokens까지 가능(초장문 Thinking Chain).
- 현재 2025년 12월 15일까지 무료 테스트 제공.
마무리
DeepSeek-V3.2는 추론 중심 모델의 성숙화에서 의미 있는 진전이다. 향상된 다단계 추론, 특화된 고성능 에디션(Speciale), 그리고 “사고 + 도구” 통합의 프로덕션화된 구현의 결합은, 숙고와 외부 동작을 교차시켜야 하는 고급 에이전트, 코딩 보조, 연구 워크플로를 구축하는 모든 이에게 주목할 만하다.
개발자는 CometAPI를 통해 DeepSeek V3.2에 접근할 수 있다. 시작하려면 Playground에서 CometAPI의 모델 기능을 탐색하고, 자세한 지침은 API guide를 참고하라. 접근 전에 CometAPI에 로그인하고 API 키를 발급받았는지 확인하라. CometAPI는 통합을 돕기 위해 공식가보다 훨씬 낮은 가격을 제공한다.
Ready to Go?→ Sign up for CometAPI today !
AI 관련 더 많은 팁, 가이드, 소식을 알고 싶다면 VK, X 그리고 Discord에서 우리를 팔로우하세요!