

Gemini Embedding 2는 텍스트, 이미지, 오디오, 비디오, PDF를 단일 3,072차원의 의미 벡터 공간으로 매핑하는 Google의 최초의 네이티브 멀티모달 임베딩 모델입니다(출력 크기 구성 가능). Matryoshka Representation Learning을 도입하여 중첩/절단 임베딩을 제공하고, 향상된 다국어 성능(100+개 언어)과 작업별 임베딩을 위한 최적화된 제어(예: task:search, task:code)를 지원합니다.
Gemini Embedding 2란 무엇인가요?
Gemini Embedding 2는 Google의 통합 임베딩 모델로, 텍스트, 이미지, 오디오, 비디오, 문서를 단일 의미 벡터 공간에 매핑합니다. 각 임베딩은(기본적으로) 입력의 의미를 표현하는 3,072차원 부동소수점 벡터로, 모달리티와 관계없이 의미적으로 유사한 항목들이 벡터 공간에서 서로 가깝게 배치됩니다. 주요 기능은 다음과 같습니다:
- 광범위한 언어 및 포맷 지원: 텍스트, 이미지, 오디오, 비디오, 문서를 하나의 의미 벡터 공간에 배치하는 단일 모델. Gemini Embedding 2는 100+개 언어 전반의 의도적 의미를 포착하도록 문서화되었으며, 일반적인 파일 포맷(PNG/JPEG, MP4/MOV, MP3/WAV, PDF)을 지원합니다. 요청별 구체적인 제한(예: 한 번의 요청당 소수의 이미지 또는 수십 초의 오디오/비디오—아래 “How to use” 참조)이 있습니다.
- 진정한 멀티모달: 단일 모델이 텍스트, 이미지, 오디오, 비디오, 문서를 하나의 의미 벡터 공간에 배치하므로 모달리티 간 비교/검색(예: 텍스트→이미지, 오디오→텍스트)이 가능합니다.
- 큰 기본 차원수와 유연한 절단: 모델은 기본적으로 3072차원 벡터를 출력하지만, *Matryoshka Representation Learning(MRL)*을 사용해 중요한 의미를 앞쪽 차원에 집중시킵니다. 따라서 1536, 768(또는 더 낮게)까지 절단해도 검색 품질 저하는 비교적 완만하며, 저장 및 연산 비용을 줄일 수 있습니다.
왜 중요한가. 과거 임베딩은 대부분 텍스트 전용이거나 모달리티마다 별도 인코더와 복잡한 크로스모달 정렬 레이어가 필요했습니다. Gemini Embedding 2는 여러 포맷을 원천적으로 지원하여 텍스트 쿼리로 의미적 유사성에 따라 이미지를 찾거나 짧은 클립을 검색할 수 있게 해줍니다(중간 전사나 수동 매핑 없이). 이는 RAG(검색 증강 생성), 시맨틱 검색, 멀티모달 검색 파이프라인을 단순화합니다.
주요 기능 및 역량(새로운 점)
1. 진정한 네이티브 멀티모달(하나의 임베딩 공간)
단일 모델이 텍스트, 이미지, 오디오, 비디오, 문서를 하나의 의미 벡터 공간에 배치합니다. Gemini Embedding 2는 텍스트, 이미지, 오디오, 비디오, 문서를 같은 임베딩 공간에 매핑하므로 크로스모달 검색(텍스트→이미지, 오디오→텍스트)이 별도의 크로스모델 정렬 없이 직접 동작합니다. 이는 파이프라인 복잡도를 줄이고 RAG(검색 증강 생성) 스택을 단순화합니다.
2. 기본 3,072차원 벡터 및 조정 가능한 출력
Gemini Embedding 2는 기본적으로 3072차원 벡터를 출력하지만, *Matryoshka Representation Learning(MRL)*을 사용해 가장 중요한 의미 정보를 앞쪽 차원에 집중시킵니다. 따라서 1536, 768(또는 더 낮게)까지 절단해도 검색 품질 저하는 비교적 완만하며, 저장/연산 비용 간 트레이드오프를 완화합니다.
3. Matryoshka Representation Learning(MRL)
MRL은 “중첩된” 임베딩을 생성합니다—러시아의 마트료시카 인형처럼—그래서 더 낮은 차원 슬라이스가 상위 수준의 의미를 보존합니다. 이를 통해 여러 개의 별도 임베딩 모델을 유지하지 않고도 시스템이 저장/정확도 트레이드오프에 맞는 운영 지점을 선택할 수 있습니다. 초기 블로그 분석과 문서에서는 이 기법을 유연성을 위한 핵심 혁신으로 설명합니다.
4. 작업 힌트 / 맞춤형 임베딩 목표
API는 task:search, task:code retrieval, task:semantic-similarity와 같은 task 힌트를 받아, 특정 다운스트림 관계에 맞도록 임베딩 기하를 최적화합니다—이전 임베딩 시스템에서의 작업 조건부 최적화와 유사하지만 멀티모달 입력으로 확장됩니다.
5. 언어 및 모달리티 범위
Gemini Embedding 2는 100+개 언어 전반의 의도적 의미를 포착하는 것으로 문서화되어 있으며, 일반적인 파일 포맷(PNG/JPEG, MP4/MOV, MP3/WAV, PDF)을 지원합니다. 요청당 구체적인 제한(예: 한 번의 요청에 이미지 몇 장, 오디오/비디오 수십 초—아래 “How to use” 참조)이 있습니다.
성능 벤치마크
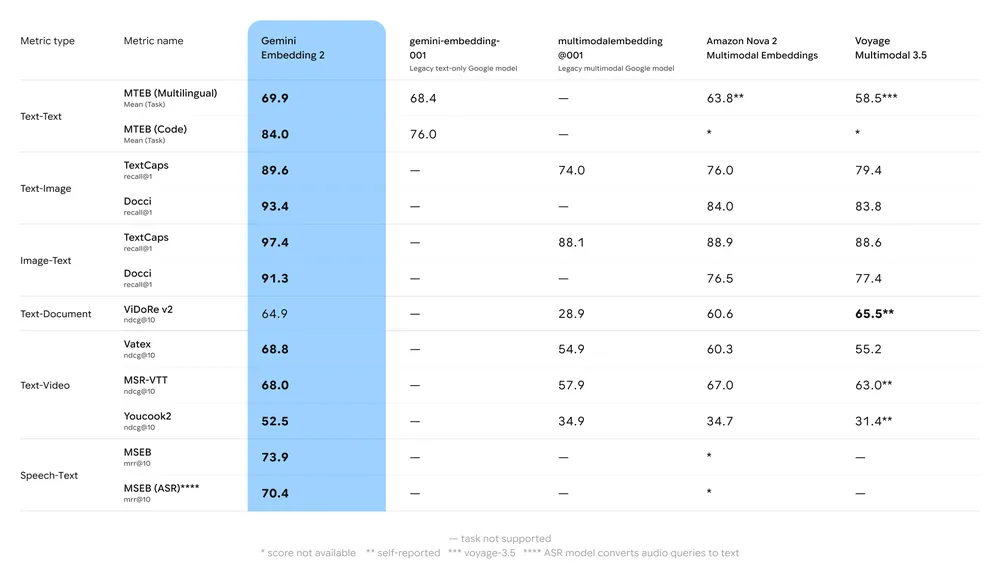
주요 벤치마크 요약:
- MTEB(Massive Text Embedding Benchmark): 영어 및 다국어 과제에서 다국어 MTEB 리더보드 상위권을 보고했으며; 분석에 따르면 Gemini의 기존 임베딩 모델과 여러 상용 대안 대비 의미 있는 상승폭을 보입니다.
- 멀티모달 검색: 네이티브 멀티모달 학습 덕분에 크로스모달 유사도(예: 텍스트→이미지 검색)에서 선도적인 단일모달 임베딩을 능가하거나 동급의 성능을 보여줍니다.
- 지연시간 및 처리량: 클라우드 호스팅 임베딩 생성이지만, 지연시간에 민감한 사용 사례는 절단 벡터 또는 경량 임베딩 모델을 엣지에서 선호할 수 있습니다.
Gemini Embedding 2 vs gemini-embedding-001 및 text-embedding-3-large
| 속성 | Gemini Embedding 2 (embedding-2) | Gemini Embedding (gemini-embedding-001) | OpenAI text-embedding-3-large |
|---|---|---|---|
| 출시 / 가용성 | Mar 10, 2026 — public preview (Gemini API / Vertex AI). | Earlier Gemini embedding (text-only variants) — GA earlier. | Announced Jan 2024 (text-only GA). |
| 지원 모달리티 | Text, images, audio, video, documents (PDF) — unified vector space. | Text (primarily). | Text only (high-quality multilingual). |
| 기본 임베딩 차원 | 3072 (MRL / truncation recommended: 1536, 768). | 3072 (for large) — text only. | 3072 (text-embedding-3-large). |
| 보고된 MTEB(예) | High-60s on MTEB; shows 68.17 at 1536 in vendor table (see docs). | gemini-embedding-001 reported ~68.32 mean in some leaderboards. | ~64.6 (MTEB average reported by OpenAI for text-embedding-3-large). |
| 네이티브 오디오/비디오 지원 | Yes (direct audio/video embedding). | No (text only). | No (text only). |
| 일반 사용 사례 | Multimodal retrieval, RAG, semantic search across file types, speech retrieval, video search. | Text retrieval, multilingual RAG. | Text retrieval, semantic search, RAG — strong multilingual text performance. |
기술 사양 및 제한사항
기본 및 조정 가능한 임베딩 크기
- 기본: 3,072차원.
- 조정 가능:
output_dimensionality파라미터로 더 낮은 차원의 출력을 요청해 저장소/CPU 절약이 가능합니다. 대규모 벡터 스토어 사용 사례에서는 비용 이유로 차원을 512–1,024로 줄이되 일정 수준의 정확도 저하를 수용하기도 합니다.
지원 모달리티 및 요청당 제한
- 이미지: PNG, JPEG — 요청당 최대 6장(벤더 보고 기준).
- 비디오: MP4, MOV — 벤더 보고 기준 단일 요청 임베딩에서 비디오당 ~128초까지.
- 오디오: MP3, WAV — 벤더 보고 기준 오디오 입력 ~80초까지.
- 문서: PDFs — 요청당 최대 6페이지(벤더 보고).
- 텍스트 콘텐츠 토큰 제한: 모델은 큰 토큰 입력을 지원하나, 실제 요청당 토큰 한도는 존재합니다(API 문서 및 Vertex AI 할당량 참조).
가용성 및 접근
- Public preview: Gemini Embedding 2는 public preview로 출시되었으며, 즉시 실험적으로 사용하기 위해 Gemini API와 Google Cloud의 Vertex AI를 통해 제공됩니다
자주 묻는 질문(FAQ)
Q1: Gemini Embedding 2는 어떤 모달리티를 지원하나요?
A: 텍스트, 이미지(PNG/JPEG), 비디오(MP4/MOV), 오디오(MP3/WAV), PDF 문서—모두 같은 의미 벡터 공간에 매핑됩니다.
Q2: Gemini Embedding 2의 기본 벡터 크기는 얼마인가요?
A: 기본은 3,072차원입니다. API를 통해 더 작은 출력 차원을 요청할 수 있습니다.
Q3: Gemini Embedding 2는 지금 사용할 수 있나요?
A: 예 — public preview로 발표되었으며 Gemini API와 Vertex AI에서 사용 가능합니다(모델 id gemini-embedding-2-preview 및 최신 변경 로그 확인).
Q4: 다른 제공업체의 임베딩과 비교하면 어떤가요?
A: 독립 벤더 테스트에 따르면 Gemini Embedding 2는 다국어 텍스트에서 상위권에 속하며, 여러 멀티모달 과제에서 최첨단 성능을 보여줍니다. 정확한 순위는 과제와 데이터셋에 따라 달라지므로, 자체 데이터로 테스트하세요.
Q5: 오디오를 사용하려면 전사를 해야 하나요?
A: 아니요 — Gemini Embedding 2는 오디오를 직접 입력받아 먼저 텍스트로 전사하지 않고도 임베딩을 생성하므로, 엔드-투-엔드 오디오 의미 검색이 가능합니다.
Q6: 3,072차원 벡터로 인한 저장 비용을 어떻게 낮출 수 있나요?
A: output_dimensionality를 낮게 요청하거나, float16/양자화/PQ를 사용하고 벡터 DB에 압축 표현을 저장하는 방법이 있습니다. 벤더 게시물에서 워크플로와 모범 사례를 제공합니다.
앞으로의 계획 — 지금 도입해야 할까요?
Gemini Embedding 2는 멀티모달 검색을 통합하는 데 큰 진전을 이루었고, 이전에 텍스트/비전/음성 각각에 별도의 리트리버가 필요했던 아키텍처를 단순화합니다. 도입을 위한 핵심 판단 기준:
- 빠른 도입: 제품이 견고한 크로스모달 검색(텍스트↔이미지/비디오/오디오)을 필요로 하거나, 단일모달 리트리버를 여러 개 유지하는 비용과 복잡도가 높은 경우.
- 지금 파일럿: MRL 절단을 평가하고 비용 대비 품질을 측정하세요(하이브리드 배포 권장: 1536을 기본, 3072는 리랭킹에 사용).
- 대기: 워크로드가 극도로 비용 민감하고 텍스트 검색만 필요한 경우—최상급 텍스트 전용 모델(OpenAI text-embedding-3-large)은 여전히 경쟁력이 있으며 파이프라인과 계약에 따라 더 저렴할 수 있습니다.
개발자는 지금 CometAPI를 통해 Gemini Embedding 2와 OpenAI text-embedding-3 API에 액세스할 수 있습니다. 시작하려면 Playground에서 모델의 기능을 탐색하고, 자세한 지침은 API guide를 참고하세요. 액세스 전에 CometAPI에 로그인하고 API 키를 발급받아야 합니다. CometAPI는 통합을 돕기 위해 공식 가격보다 훨씬 저렴한 가격을 제공합니다.
Ready to Go?→ 오늘 cometapi에 가입하세요 !