

Luma AI’s Uni-1 is more than a new text-to-image model. In Luma’s own framing, it is a “multimodal reasoning model that can generate pixels,” built on “Unified Intelligence” so it can understand intention, respond to direction, and “think with you.” The company’s technical report says the model uses a decoder-only autoregressive transformer in which text and images are represented in a single interleaved sequence, and that Uni-1 can perform structured internal reasoning before and during image synthesis. That combination is what makes Uni-1 one of the most interesting image-model releases of 2026.
What is the UNI-1 image model?
Uni-1 is Luma AI’s new image model for tasks that require both understanding and generation in one system. Luma presents it as a multimodal reasoning model rather than a classic diffusion-only image engine, which matters because the model is meant to do more than produce visually pleasing outputs: it is designed to interpret instructions, preserve reference constraints, and reason through scene logic as part of generation. The company’s technical report describes Uni-1 as its first unified understanding-and-generation model on the path toward multimodal general intelligence.
Why Uni-1 is different
The old pipeline has a ceiling: image generation without understanding can only go so far. Uni-1 is presented as a step toward “unified intelligence,” where language, perception, imagination, planning, and execution are handled inside one architecture. This is more than branding. Uni-1 can move from visual resemblance toward intentional composition, plausibility, and scene logic.
The bigger story is that image models are becoming more agentic. Google’s newest image stack now emphasizes conversational editing, search grounding, multi-image fusion, and character consistency; OpenAI’s GPT Image family emphasizes native multimodality and instruction following. Uni-1 joins that shift, but it leans harder into the idea that the model should “think” about the image before drawing it. That makes Uni-1 especially interesting for workflows where precision and repeatability matter as much as visual flair.
How does Uni-1 actually work?
🔬 Tokenization Process
- Text → token sequence
- Image → tokenized patches
- Combined into single interleaved sequence
🔁 Generation Process
- Input prompt + references
- Model performs internal reasoning
- Plans composition
- Generates tokens sequentially
Mathematically: P(x1,...,xn)=∏P(xi∣x1,...,xi−1)P(x_1,...,x_n) = \prod P(x_i | x_1,...,x_{i-1})P(x1,...,xn)=∏P(xi∣x1,...,xi−1)
🧠 Internal Reasoning Layer
Uni-1:
- Decomposes instructions
- Resolves constraints
- Plans layout before rendering
👉 This is a major leap vs diffusion models.
Decoder-only autoregressive generation
The most important technical detail is that Uni-1 is autoregressive rather than diffusion-based. Luma’s tech report says it is a decoder-only autoregressive transformer, and that text and images are encoded in a single interleaved sequence. In plain English, the model does not merely start from noise and gradually “denoise” toward an image. Instead, it generates tokens step by step, allowing the model to reason through the prompt, resolve constraints, and plan composition before and during rendering.
🔬 Tokenization Process
- Text → token sequence
- Image → tokenized patches
- Combined into single interleaved sequence
Diffusion vs Autoregressive
| Feature | Diffusion Models | Uni-1 (Autoregressive) |
|---|---|---|
| Generation | Noise → Image | Token-by-token |
| Reasoning | Limited | Strong |
| Editing | Weak | Multi-turn |
| Text rendering | Poor | Strong |
| Control | Low | High |
Core Architecture
Uni-1 is:
- Decoder-only autoregressive transformer
- Shared token space for text + images
That architecture matters because it gives the model a chance to maintain coherence when the prompt is complicated. Luma says Uni-1 can decompose instructions, resolve conflicting constraints, and plan the image before rendering begins. That is especially useful for tasks like structured scene completion, multi-subject placement, multi-turn refinement, and edits that require the output to stay faithful to a reference image while still obeying new instructions.
What the model seems designed to do better
Learning to generate images improves understanding. Luma says the model’s image-generation training materially improves fine-grained visual understanding, especially over regions, objects, and layouts. That is why the Uni-1 not as a one-way generator but as a unified system whose generation and comprehension reinforce each other. Inference-wise, this means Uni-1 is trying to close the gap between “seeing” and “making.” This is a major leap vs diffusion models.
Generation Process:
- Input prompt + references
- Model performs internal reasoning
- Plans composition
- Generates tokens sequentially
Mathematically: P(x1,...,xn)=∏P(xi∣x1,...,xi−1)P(x_1,...,x_n) = \prod P(x_i | x_1,...,x_{i-1})P(x1,...,xn)=∏P(xi∣x1,...,xi−1)
What features and core advantages does Uni-1 offer?
Strong instruction-following and directability
Uni-1’s strongest selling point is control. the model is built for precision editing, structured reference use, and repeatable workflows. For creators, that means less prompt gambling and more repeatable output.
One of Uni-1’s practical advantages is that it is built for controlled iteration. Seeds let users reproduce results, while reference roles help the model know whether an image should guide character identity, mood, palette, or composition. That makes Uni-1 easier to direct than a purely prompt-driven model, especially for teams producing ads, storyboards, product mockups, or brand assets where consistency matters.
Reference-based generation that preserves identity
A major advantage is reference handling. Luma explicitly says Uni-1 uses source-grounded controls and can preserve identity, composition, and key visual constraints from one or more references. That makes it attractive for commercial workflows such as brand characters, product mockups, campaign assets, and any project where a subject must remain recognizable across variants. This is one of the clearest ways Uni-1 differs from more purely aesthetic image systems.
Cultural fluency and style breadth
Luma also emphasizes culture-aware generation. Its “Cultured” section points to memes, manga, cinematic looks, casual photos, sports, and animal imagery, showing that the model is intended to operate across visual languages rather than one generic style. That matters because a good modern image model does not just need to render a realistic scene; it also needs to understand the visual conventions of internet culture, editorial design, stylized illustration, and social content.
Multimodal thinking as a design choice
The real differentiator is not only that Uni-1 generates images, but that Luma frames image generation as a reasoning task. Uni-1 can perform structured internal reasoning and that learning to generate images improves fine-grained visual understanding over regions, objects, and layouts. That suggests a model meant to understand the scene before rendering it, rather than simply approximate the prompt statistically.
Performance Benchmarks
Luma’s own human-preference results
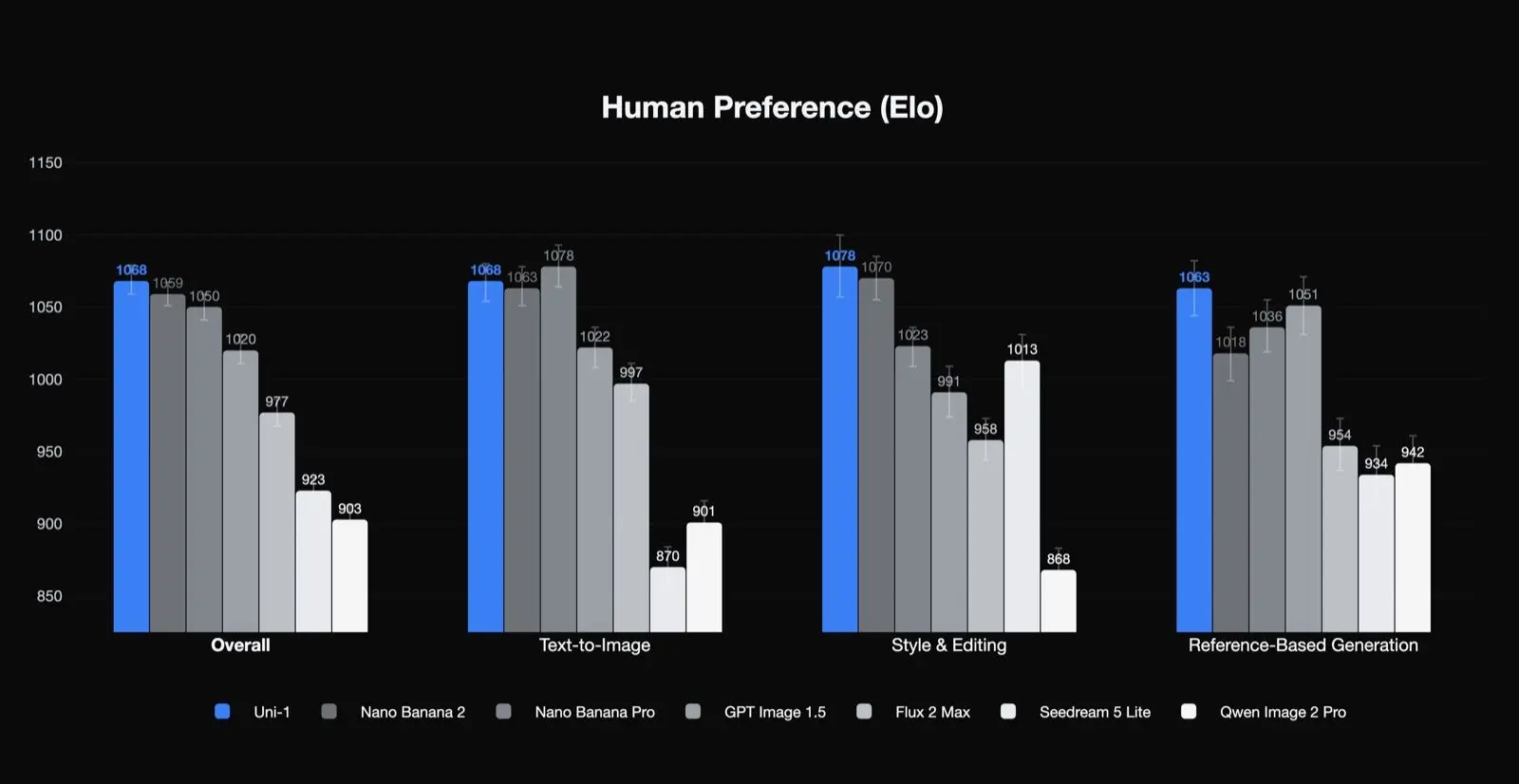
Uni-1 ranks first in human-preference Elo for overall quality, style and editing, and reference-based generation, and second in text-to-image. That is a meaningful result because it suggests the model is especially strong in the kinds of tasks that production teams care about: editing, consistency, and guided transformation. It also suggests that its best use cases may not be plain one-shot text-to-image generation alone.
RISEBench: reasoning-informed visual editing
The most attention-grabbing benchmark is RISEBench, which evaluates reasoning-informed visual editing across temporal, causal, spatial, and logical reasoning. Third-party reporting on Luma’s launch says Uni-1 scores 0.51 overall on RISEBench, ahead of Google’s Nano Banana 2 at 0.50, Nano Banana Pro at 0.49, and OpenAI’s GPT Image 1.5 at 0.46. On spatial reasoning, Uni-1 is reported at 0.58 versus Nano Banana 2 at 0.47. On logical reasoning, Uni-1 is reported at 0.32, more than double GPT Image 1.5’s 0.15. The margins are not huge overall, but they are large in the hardest reasoning categories.

ODinW-13 and the “generation improves understanding” claim
Uni-1 also performs strongly on ODinW-13, an open-vocabulary dense detection benchmark. Reporting on Luma’s technical data says the full model scores 46.2 mAP, nearly matching Google’s Gemini 3 Pro at 46.3. The same reporting says an understanding-only variant scores 43.9 mAP, which implies that generation training improves understanding by 2.3 points. That is a notable finding because it supports Luma’s core thesis: image generation and image understanding may be mutually reinforcing rather than competing objectives.
Price of Uni-1 API
| Input price (text) | $0.50 |
|---|---|
| Input price (images) | $1.20 |
| Output price (text and thinking) | $3.00 |
| Output price (images) | $45.45 |
On the consumer side, Luma's pricing page lists Plus at $30/month, Pro at $90/month, and Ultra at $300/month, with free trial credits included across plans. This means there are essentially two layers of pricing to consider: the consumer membership for the platform and the model-level API pricing for production use.
For now, CometAPI's Uni-1 API is Available Soon, with a promised discount upon launch. Currently, CometAPI also offers excellent raw image models, such as Midjourney and Nano Banana 2.
Uni-1 vs GPT Image 1.5 vs Nano Banana 2
Uni-1 versus Google’s Nano Banana 2
Nano Banana 2 looks stronger on breadth of reference handling and ecosystem integration. Google emphasizes image search grounding, conversational iteration, and reference-heavy workflows with up to 14 references. Uni-1, by contrast, is more explicitly framed around reasoning, scene plausibility, and precision editing in a unified model architecture. In practical terms, Google appears optimized for speed, mainstream production scale, and native Google grounding; Luma appears optimized for structured visual reasoning and directable image editing.
In the public comparisons around Uni-1, the tradeoff is clear: Nano Banana 2 appears to remain very strong for pure text-to-image quality and speed, while Uni-1 pushes harder on reasoning-heavy editing, reference control, and instruction fidelity.
Uni-1 versus OpenAI’s GPT Image
In benchmark reporting, Uni-1 edges GPT Image 1.5 on RISEBench overall and more decisively on logical reasoning. Compared with OpenAI’s GPT Image family, Uni-1 is more narrowly and aggressively positioned around visual reasoning and controlled editing. OpenAI’s docs emphasize world knowledge, multimodal understanding, and contextual awareness; Luma’s docs emphasize structured internal reasoning, reference-grounded control, and benchmarked visual-editing skill. So while both are multimodal, Uni-1 is the more obviously “image-specialist reasoning model,” whereas GPT Image reads more like a general multimodal system that happens to generate images extremely well.
Price comparison across the three
On pricing, the comparison depends on output size and product tier, so it is not perfectly apples-to-apples. Uni-1’s published 2048px equivalent is about $0.0909 per image. Google’s latest image-model pricing page lists $0.134 per 1K/2K image and $0.24 per 4K image for its latest Gemini image preview, while OpenAI’s GPT Image pricing page lists per-image output pricing of $0.011 at low quality for 1024x1024, $0.042 at medium quality, and $0.167 at high quality, with larger high-quality outputs at $0.25. In other words, OpenAI can be much cheaper at the low end, Google is aggressive at the speed-and-scale end, and Uni-1 lands in the middle with a strong 2K-oriented price-performance profile.
Philosophical Differences
| Model | Approach |
|---|---|
| Uni-1 | Unified multimodal intelligence |
| GPT Image | LLM + image generation |
| Nano Banana 2 | Optimized production diffusion |
Detailed Comparison Table
| Feature | Uni-1 | GPT Image 1.5 | Nano Banana 2 |
|---|---|---|---|
| Architecture | Autoregressive | Hybrid | Diffusion |
| Multimodal unification | ✅ Native | Partial | ❌ |
| Reasoning ability | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ |
| Image quality | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| Text rendering | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐ |
| Editing workflows | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ |
| Speed | Medium | Fast | Fast |
| Control | High | Medium | Medium |
CometAPI provides interactive raw images for GPT Image 1.5, Nano Banana 2, and the upcoming Uni-1, as well as API programming. Discounted pricing and pay-as-you-go options make it a preferred choice for developers.
What Uni-1 is best for
Uni-1 looks especially strong for cases where you need repeatability, character consistency, or multi-reference control. That includes brand campaigns, product mockups, editorial concepts, storyboards, localization variants, and image edits where composition must stay intact but style or environment should change. Luma’s own examples lean heavily into these use cases, and the model’s “Create vs Modify” split is basically a direct answer to common production pain points.
If your work is mostly “make something pretty from a single prompt,” the differentiator may feel less dramatic. But if your workflow is “make five related versions, keep the same character, preserve framing, change the lighting, and make it reproducible next week,” Uni-1’s design starts to make a lot of sense. That is an inference, but it follows naturally from the control features Luma emphasizes.
Best practices for getting better results with Uni-1
Start by using the correct mode. Luma’s guidance is simple: Create when you want a new scene, Modify when you want to preserve an existing one. Mixing those intents makes outputs wobblier.
Use reference labels like a professional. Luma recommends phrases such as “Use IMAGE1 as a STYLE reference” or “Use IMAGE2 as LIGHTING.” The model does better when each reference has a job, instead of vague “inspiration.”
Lock the seed after you find something good. Luma explicitly recommends exploring without a seed first, then saving the seed once you have a strong result. After that, change one variable at a time. That is the easiest way to turn generation into a controlled production system.
Be specific, and be concrete. Luma warns against vague words like “beautiful” or “amazing,” and instead encourages named aesthetics such as “1970s Italian giallo film poster” or exact camera-style cues. In practice, specific prompts usually beat poetic prompts because the model can anchor on real structure.
Use the Create → Modify chain. Luma explicitly calls this one of its most powerful workflows: explore in Create, then refine in Modify. That’s the sweet spot for serious production work, because it reduces backtracking and preserves the good parts of a composition while tightening the details.
Final verdict
Uni-1 is Luma’s clearest statement yet that image generation is moving from “prompt in, picture out” toward reasoning-guided visual creation. Its public strengths are control, reference handling, reproducibility, and a model architecture that keeps language and pixels in the same system.
For creators and teams who care about high-click visual output, consistent characters, precise edits, and high-resolution pricing clarity, Uni-1 is very much a model worth watching. If the API rollout lands cleanly, it could become one of the most interesting alternatives to Google’s Nano Banana 2 and OpenAI’s GPT Image 1.5 in 2026.
Planning to start creating raw images? CometAPI, a one-stop aggregation platform for multimodal model APIs, welcomes you!