

GLM-5-Turbo ialah LLM asas baharu daripada Zhipu AI yang dilatih dan ditala khusus untuk aliran kerja gaya ejen (syarikat menamakan ekosistem sasaran sebagai OpenClaw / senario “lobster”). Ia menawarkan konteks yang sangat panjang (sehingga ~200K token), penstriman dan output berstruktur, kadar ralat panggilan alat yang lebih rendah (dilaporkan ~0.67% dalam ujian pihak ketiga), serta harga per token yang ketara lebih rendah. Model ini bertujuan “mengorbankan” sedikit throughput puncak satu pusingan untuk kestabilan yang jauh lebih baik, kebolehpercayaan alat, pengendalian tugas berjadual/berterusan dan pelaksanaan rantaian panjang—berguna untuk ejen autonomi, sistem orkestrasi dan saluran paip berbilang alat.
Apa itu GLM-5-Turbo?
GLM-5-Turbo dikemukakan oleh Zhipu sebagai model asas yang dibina untuk orkestrasi ejen dan aliran kerja automatik kompleks dan bukannya model sembang atau multimodal umum. Pilihan reka bentuk menekankan:
- Latihan mesra ejen secara asli (penggunaan alat, pematuhan perintah, tugas bertempoh/berterusan).
- Tetingkap konteks yang sangat besar dan kapasiti output besar untuk menyokong sesi panjang, memori, dan perancangan rantaian pemikiran.
- Inferens stabil, ber-throughput tinggi untuk aliran perniagaan panjang dan tugas berjadual.
Tidak seperti LLM tradisional yang dioptimumkan untuk sembang atau penjanaan teks, GLM-5-Turbo adalah:
- Utamakan ejen (bukan utamakan sembang)
- Dibina untuk persekitaran OpenClaw (“lobster”)
- Direka untuk aliran kerja autonomi berbilang langkah
🦞 Apa maksud “Ejen Lobster”?
Konsep “lobster” merujuk kepada OpenClaw, ekosistem ejen AI Zhipu di mana model:
- Menggunakan alat secara dinamik
- Melaksanakan rantaian tugas yang panjang
- Mengekalkan memori berterusan
- Beroperasi merentas terminal, apl dan API
GLM-5-Turbo dioptimumkan secara mendalam untuk paradigma ini, menyelesaikan masalah utama ejen seperti:
- Kebolehpercayaan panggilan alat
- Penguraian tugas
- Perancangan jangka panjang
- Kestabilan pelaksanaan
Ciri utama dan sebab ia penting
Konteks panjang + kapasiti output besar (200K / 128K)
Tetingkap konteks 200K token dan keupayaan output 128K membolehkan GLM-5-Turbo:
- Mengekalkan memori lanjutan terhadap konteks terdahulu (perbualan, output alat, hasil perantaraan).
- Menghasilkan artifak yang sangat panjang (pelan berbilang peringkat, laporan panjang, asas kod) tanpa perlu mengikat semula konteks berulang kali.
- Mengehos ejen berbilang pusingan yang perlu mengekalkan keseluruhan sejarah pelaksanaan untuk membuat keputusan yang tepat.
Ini ialah pilihan teknikal yang disengajakan untuk ejen — bukannya memecahkan tugas kepada prompt pendek, ejen boleh mengekalkan keadaan koheren merentas ribuan pusingan perbualan atau langkah.
Primitif ejen disepadukan dalam latihan
Daripada menyesuaikan model serba guna kepada tugas ejen, GLM-5-Turbo dilatih dengan objektif gaya ejen (contohnya, tingkah laku pemanggilan alat, penghurai perintah/argumen). Kesan yang didakwa ialah halusinasi lebih sedikit ketika panggilan alat, pelan berbilang langkah lebih stabil, dan kependaman bertambah baik dalam larian panjang — semua ini bernilai apabila automasi perlu merantai banyak API atau alat luaran dengan kebolehpercayaan.
Throughput dan kestabilan pelaksanaan
Varian GLM-5-Turbo memperbaiki kestabilan pelaksanaan dan throughput untuk aliran perniagaan panjang berbanding model besar yang digeneralisasi — bahasa pemasaran menekankan "pelaksanaan ber-throughput tinggi" dan "kestabilan respons terkemuka" di kalangan model serupa. Ini bermakna untuk penggunaan ejen perusahaan di mana satu langkah gagal boleh merosakkan keseluruhan saluran paip. Penanda aras pihak ketiga bebas masih muncul.
Data penanda aras GLM-5-Turbo
Nota: Zhipu telah menerbitkan penilaian dalaman, dan penanda aras pihak ketiga/akademik untuk GLM-5 tersedia. GLM-5-Turbo baru dilancarkan; larian penanda aras komuniti bebas akan mengambil masa untuk muncul. Di bawah kami menyenaraikan angka yang paling boleh dipertahankan dan konteks yang diterbitkan.
GLM-5 (rujukan) — metrik yang diterbitkan representatif
GLM-5 (penanda aras utama, pendahulu kepada Turbo) melaporkan kedudukan teratas dalam banyak tugas kejuruteraan/aliran kerja — sebagai contoh:
- SWE-bench Verified: 77.8 (dilaporkan dalam dokumentasi GLM-5 sebagai skor model terbuka terkemuka).
- Terminal Bench 2.0: 56.2 (dilaporkan sebagai prestasi model terbuka teratas pada taburan yang diberikan).
Nombor tersebut menetapkan GLM-5 sebagai garis dasar tinggi dalam tugas kejuruteraan perisian dan pelaksanaan; GLM-5-Turbo diposisikan untuk menukar sebahagian penekanan saiz/parameter mentah kepada kebolehpercayaan ejen dan throughput yang lebih baik. GLM-5-Turbo menunjukkan ~0.67% ralat panggilan alat dalam larian perbandingan mereka, jauh lebih rendah daripada larian pembekal GLM-5 perbandingan yang berada dalam julat ~2.33% hingga 6.41%.
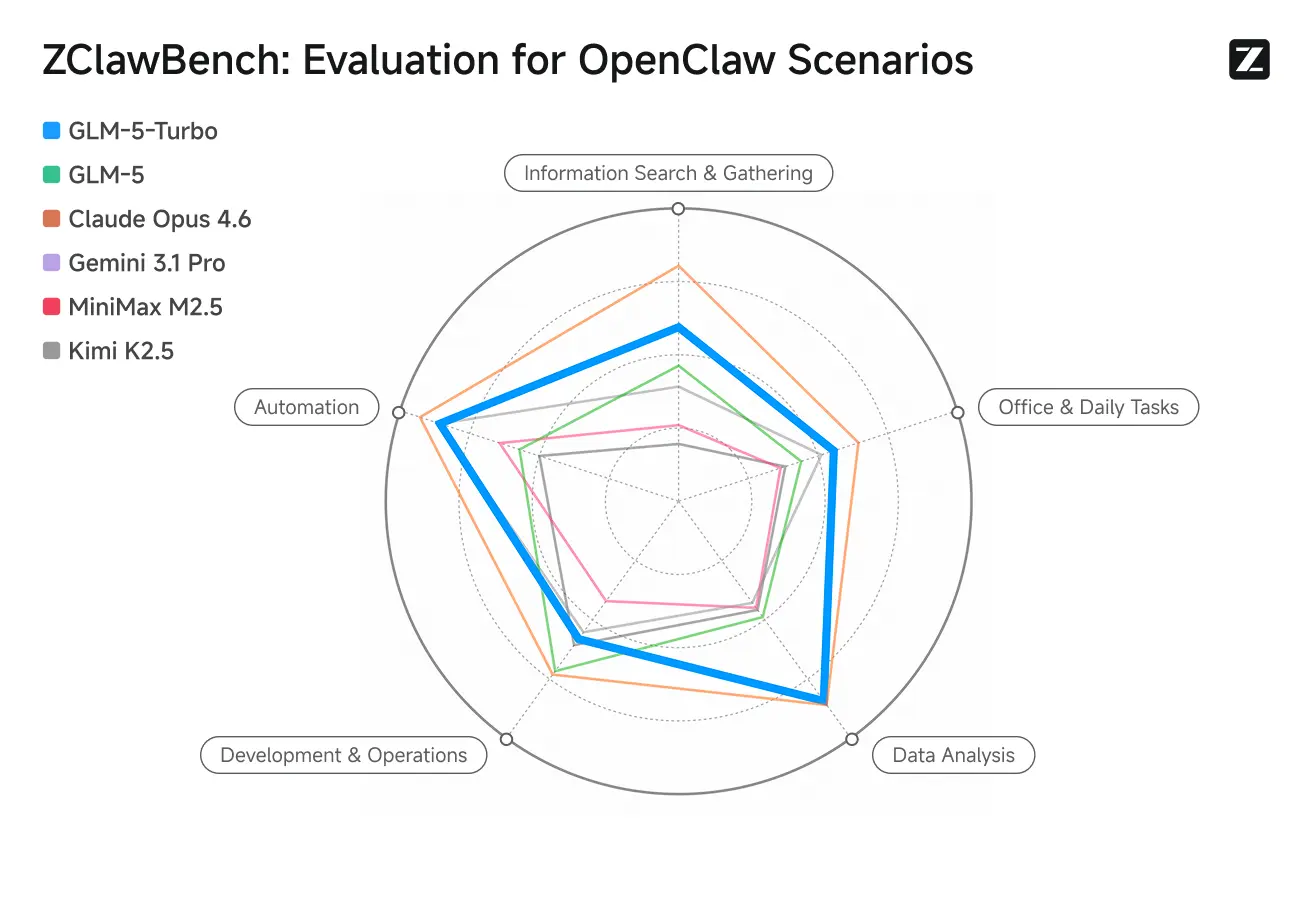
ZClawBench: Ujian Penanda Aras untuk Senario Proksi OpenClaw
Zhipu turut mengeluarkan penanda aras ZClawBench untuk menilai ejen pintar. Dalam ujian buta merangkumi pelbagai bidang seperti pembangunan kod, analisis data dan penciptaan kandungan, model baharu berkod nama Pony-Alpha-2 mendapat sokongan 90% daripada responden.
Harga & ketersediaan (siapa yang menjual dan berapa)
Zhipu melaksanakan kenaikan harga API ~20% untuk tawaran GLM-5-Turbo ketika pelancaran dan serentak memperkenalkan peringkat langganan “Lobster Package” yang bertujuan melicinkan harga token untuk penggunaan ejen.
Peringkat langganan yang dilaporkan (pakej contoh)
Dua pakej Lobster ilustratif (harga ialah penukaran yang dilaporkan dan anggaran):
- Pelan Lobster Permulaan:
39 CNY / bulan (US$5.66) untuk 35,000,000 token. - Pelan Lobster Pertengahan:
99 CNY / bulan (US$14.36) untuk 100,000,000 token.
Berdasarkan nombor yang diterbitkan itu, kos bagi 1 juta token adalah lebih kurang:
- Pelan Permulaan: ~US$0.162 setiap 1M token.
- Pelan Pertengahan: ~US$0.144 setiap 1M token.
Angka per-1M tersebut ialah penukaran mudah daripada kos langganan yang diterbitkan dan had token, menggambarkan ekonomi untuk beban kerja ejen berkelantangan tinggi. (Pengiraan berdasarkan mata wang dan kuantiti token yang dilaporkan media.)
Harga API
Penyenaraian pasaran wakil (CometAPI): $0.96 per 1M token input dan $3.20 per 1M token output untuk GLM-5-Turbo.
Halaman harga pembangun Zhipu sendiri (Z.ai) menyenaraikan kadar langsung yang sedikit lebih tinggi untuk GLM-5-Turbo: $1.20 per 1M token input dan $4.00 per 1M token output (kadar input cache lebih rendah).
GLM-5-Turbo vs GLM-5 — perbandingan sebelah-menyebelah
Pada aras tinggi:
- GLM-5 = model asas perdana serba guna (penaakulan, pengekodan, penanda aras)
- GLM-5-Turbo = varian dioptimumkan untuk ejen bagi GLM-5 (fokus pada aliran kerja panjang, penggunaan alat, kestabilan)
GLM-5-Turbo bukan seni bina model yang serba baharu, tetapi versi khusus GLM-5 yang dioptimumkan untuk produksi yang direka untuk sistem ejen seperti OpenClaw.
Pemposisian teras
| Model | Pemposisian |
|---|---|
| GLM-5 | Model asas perdana serba guna (penaakulan, pengekodan, penanda aras) |
| GLM-5-Turbo | Model utamakan ejen (automasi, orkestrasi, penggunaan alat) |
👉 Secara ringkas:
- Guna GLM-5 → apabila anda mahukan kecerdasan maksimum
- Guna GLM-5-Turbo → apabila anda mahukan automasi/ejen yang stabil
Perbandingan keupayaan ejen (PALING PENTING)
GLM-5 (keupayaan ejen) sudah menyokong:
- Penggunaan alat
- Penaakulan berbilang langkah
- Ejen pengekodan
Namun hadnya:
- Boleh kehilangan konteks dalam rantaian panjang
- Panggilan alat boleh merosot dari semasa ke semasa
- Memerlukan lebih banyak logik orkestrasi
GLM-5-Turbo dioptimumkan secara eksplisit untuk ejen:
Penambahbaikan utama:
- Kebolehpercayaan panggilan alat ↑
- Penguraian tugas (perancangan) ↑
- Konsistensi rantaian panjang ↑
- Sokongan pelaksanaan berterusan ↑
Contoh penambahbaikan:
- Pelaksanaan stabil merentas 10+ langkah tanpa kehilangan konteks
👉 Ini penting untuk:
- Sistem gaya AutoGPT
- Aliran kerja berbilang ejen
- Automasi SaaS
Kelajuan & kecekapan
| Aspek | GLM-5 | GLM-5-Turbo |
|---|---|---|
| Kelajuan inferens | Sederhana | Lebih pantas |
| Throughput | Standard | Lebih tinggi |
| Kelewatan tugas panjang | Boleh merosot | Dioptimumkan |
GLM-5-Turbo direka untuk menyelesaikan masalah industri sebenar:
Model besar menjadi perlahan atau gagal semasa aliran kerja yang panjang
Perbandingan harga
| Model | Input ($/1M token) | Output ($/1M token) |
|---|---|---|
| GLM-5 | ~$1.00 | ~$3.20 |
| GLM-5-Turbo | ~$1.20 | ~$4.00 |
👉 GLM-5-Turbo lebih mahal (~20% lebih tinggi)
Mengapa lebih mahal?
Kerana ia menyediakan:
- Kebolehpercayaan orkestrasi yang lebih baik
- Kestabilan produksi yang lebih tinggi
- Pengoptimuman khusus ejen
👉 Dalam perusahaan:
- Anda membayar lebih per token
- Tetapi mengurangkan kos kegagalan + cubaan semula
| Atribut | GLM-5 | GLM-5-Turbo |
|---|---|---|
| Matlamat utama | Model asas perdana serba guna (keupayaan luas, pengekodan/penanda aras yang kukuh) | Model asas dioptimumkan untuk ejen/“OpenClaw” / lobster |
| Tetingkap konteks | (dilaporkan tinggi; GLM-5 memfokus ~200K (GLM-5 juga menyokong konteks panjang) | 200,000 token (didokumentasikan secara jelas). |
| Token output maksimum | (besar, bergantung model) | 128,000 token (didokumentasikan). |
| Skor penanda aras ketara | SWE-bench: 77.8; Terminal Bench 2.0: 56.2 (nombor yang dilaporkan GLM-5). | Penilaian dalaman mendakwa kestabilan rantaian panjang dan throughput yang dipertingkat untuk aliran kerja ejen; penanda aras awam bebas masih belum ada. |
| Modaliti | Teks (utama), keluarga GLM mempunyai varian visi dalam model adik | Teks sahaja (menurut dokumen) — dioptimumkan untuk ejen berasaskan alat. |
| Kes penggunaan yang disyorkan | Luas: sembang, kod, penaakulan, kandungan | Orkestrasi ejen, pemanggilan alat, automasi jangka panjang |
| Harga | Harga GLM-5 sedia ada (berubah mengikut pelan) | Pelancaran baharu — dilaporkan kenaikan harga API ~20%; peringkat langganan Lobster baharu diperkenalkan |
Cara menggunakan GLM-5-Turbo
CometAPI — akses API tunggal kepada banyak model (serasi OpenAI)
CometAPI menyenaraikan GLM-5-Turbo sebagai tersedia dan menyediakan URL asas dan SDK serasi OpenAI. Gunakan rentetan model yang mereka siarkan (laman mereka menyenaraikan GLM-5-Turbo pada harga serupa). Contoh yang disesuaikan daripada dokumentasi CometAPI:
curl (CometAPI):
curl -X POST "https://api.cometapi.com/v1/chat/completions" \ -H "Authorization: Bearer YOUR_COMETAPI_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "z-glm-5-turbo", // or use the exact model slug shown in CometAPI UI "messages": [{"role":"user","content":"Create a 5-step checklist for onboarding a new hire."}], "max_tokens": 800 }'
Nilai CometAPI ialah kemudahan sebagai agregator (integrasi tunggal untuk banyak model). Sahkan slug model yang tepat dalam papan pemuka CometAPI sebelum membuat panggilan.
Amalan terbaik apabila membina ejen Lobster / OpenClaw dengan GLM-5-Turbo
- Reka untuk kebolehpercayaan, bukan kepantasan mentah: Keuntungan Turbo ialah kadar kegagalan panggilan alat yang lebih rendah dalam rantaian panjang. Strukturkan larian ejen untuk mengutamakan penyempurnaan yang mantap (cuba semula, panggilan alat idempotent) berbanding keuntungan kecil token pertama.
- Guna penstriman & panggilan alat beransur-ansur: Gunakan penstriman/output berketul untuk mengurangkan kerja semula dan membolehkan pemanggilan alat awal apabila sesuai. GLM-5-Turbo menyokong penstriman.
- Output berstruktur untuk penghurai: Utamakan JSON atau hasil yang diformat baik untuk penghuraian alat hiliran yang deterministik. Turbo menyokong output berstruktur.
- Rancang untuk penjadualan / ketekalan: Jika ejen anda perlu memeriksa secara berkala atau menjalankan tugas latar, gunakan semantik masa dan ciri cache Turbo yang lebih baik untuk mengelakkan perancangan semula setiap kitaran.
- Instrumentasi panggilan alat & sandaran: Log panggilan alat dan reka mekanisme sandaran yang baik (contohnya, cuba semula dengan suhu sedikit, atau panggil alat sandaran) kerana aliran kerja ejen mudah rapuh jika satu API luaran gagal. Turbo mengurangkan kadar ralat tetapi tidak menghapuskan kegagalan luaran
Pembangun boleh mengakses API GLM-5 dan GLM-5 turbo melalui CometAPI sekarang. Untuk bermula, rujuk panduan API untuk arahan terperinci. Sebelum mengakses, pastikan anda telah log masuk ke CometAPI dan memperoleh kunci API. CometAPI menawarkan harga yang jauh lebih rendah daripada harga rasmi untuk membantu anda mengintegrasi.
Sedia untuk bermula?→ Daftar untuk GLM-5 dan GLM-5 turbo hari ini !