

Google en zijn onderzoeksafdeling DeepMind hebben stilletjes (en vervolgens minder stilletjes) een nieuwe grote stap in de Gemini-roadmap gezet: Gemini 3.1 Pro. De release, uitgerold via consumentenkanalen en CometAPI, is gepositioneerd als een upgrade in prestaties en redeneren voor de Gemini 3-familie — met de belofte van aanzienlijk sterkere langvormige redenering, verbeterd multimodaal begrip en betere schaalbaarheid voor toepassingen in de echte wereld.
Google's nieuwste model — wat is Gemini 3.1 Pro?
Gemini 3.1 Pro is de eerste incrementele update in de Gemini 3-familie, gepositioneerd als een “meest capabel” redeneringsmodel, geoptimaliseerd voor meerstaps-, multimodale en agentische taken. In publieke preview uitgebracht medio februari 2026 (preview aangekondigd 19–20 februari 2026), richt het model zich expliciet op scenario’s die langdurige gedachteketens, toolgebruik en begrip van lange context vereisen — bijvoorbeeld: grootschalige onderzoeksynthese, engineering-agents die tools en systemen coördineren, en multimodale analyse van documenten die tekst, afbeeldingen, audio en video combineren.
Op hoofdlijnen wordt Gemini 3.1 Pro door zijn ontwikkelaars beschreven als:
- Van nature multimodaal — in staat tekst, afbeeldingen, audio en video te accepteren en daarover te redeneren.
- Gebouwd voor lange context — ondersteunt zeer grote contextvensters, geschikt voor volledige codebases, multidocumentdossiers of lange transcripties.
- Geoptimaliseerd voor betrouwbare redenering en agentische workflows, wat betekent dat het is afgestemd op plannen, tools aanroepen en outputs verifiëren bij meerstapstaken.
Waarom dit nu belangrijk is: organisaties en ontwikkelaars bewegen van “goede conversatie-assistenten” naar “high-stakes beslissingsondersteuning en onderzoeksagents” (juridische tekstproductie, R&D-synthese, multimodale documentbegrip). Gemini 3.1 Pro is expliciet ontworpen voor die richting — om hallucinaties te verminderen, traceerbare redenering te produceren en te integreren met CometAPI voor zowel prototyping als productie.
Wat zijn de technische hoogtepunten en features van Gemini 3.1 Pro?
Native multimodaliteit en extreme contextvensters
Gemini 3.1 Pro zet de multimodale focus uit de Gemini-lijn voort. Volgens de modelkaart en productnotities accepteert en redeneert het model over tekst, afbeeldingen, audio en video in dezelfde pijplijn — een capaciteit die workflows vereenvoudigt waar datatypen gemengd zijn (bijv. juridische verklaringen met audio + transcript + scans). Opvallend is dat het model een 1,000,000-token contextvenster ondersteunt en lange outputs kan produceren (gepubliceerde notities plaatsen uitvoerlimieten op zeer grote grootte, geschikt voor long-form taken). Deze schaal maakt het geschikt voor use-cases zoals het analyseren van hele coderepositories, meerhoofdstukdocumenten of lange transcripties zonder opdeling.
“Dynamisch denken”: verbeterde redenering & stapsgewijze planning
Google beschrijft 3.1 Pro als voorzien van verbeterd “denken” — d.w.z. betere interne afhandeling van redeneerketens en dynamische selectie van redeneerstrategieën afhankelijk van taakcomplexiteit. Het model is afgestemd om expliciete meerstapsplanning in te zetten wanneer nodig, en daarbij tokenefficiënt te blijven. In de praktijk vertaalt dit zich naar minder hallucinaties bij complexe, stapsgewijze problemen en verbeterde feitelijke consistentie op benchmarks voor meerstapsredenering.
Agentische workflows & toolgebruik
Een belangrijke ontwerpfocus voor 3.1 Pro is agentische performance: tools coördineren, web grounding of search aanroepen, codesnippets schrijven en uitvoeren, en outputs verifiëren via secundaire passes. Google heeft 3.1 Pro geïntegreerd in agent-first producten (bijv. de Antigravity-ontwikkelomgeving) om modellen taken te laten uitvoeren die een editor, terminal en browser omvatten — en artefacten zoals screenshots en browseropnames vast te leggen om voortgang te verifiëren. Deze features zijn bedoeld om de kloof te verkleinen tussen “adviesgevende” modellen en modellen die daadwerkelijk multi-tool-workflows betrouwbaar uitvoeren.
Gespecialiseerde submodes (Deep Research, Deep Think)
Google koppelt 3.1 Pro aan “Deep Research” en verwijst naar een aanstaande “Deep Think”-variant. Deze submodes zijn respectievelijk gericht op taken met hoge recall en maximale redeneerdiepte (tegen extra compute-kosten en latency). Ze zijn bedoeld voor analisten, onderzoekers en ontwikkelaars die meer bedachtzame, hogere-kwaliteit outputs nodig hebben in plaats van de snelste, goedkoopste respons.
Hoe presteert Gemini 3.1 Pro op benchmarks?
Gemini 3.1 Pro boekt sterke winst ten opzichte van eerdere Gemini 3 Pro-resultaten, neemt vaak de leiding op een brede set van meerstapsredenering- en multimodale metingen — maar blijft achter op sommige concurrenten bij specifieke gespecialiseerde taken (met name bepaalde geavanceerde coding- of expert-questionsuites). Kort samengevat: brede verbeteringen met kleine voorsprongen van concurrenten in specialty-benchmarks.
Belangrijke benchmarkclaims en kerncijfers
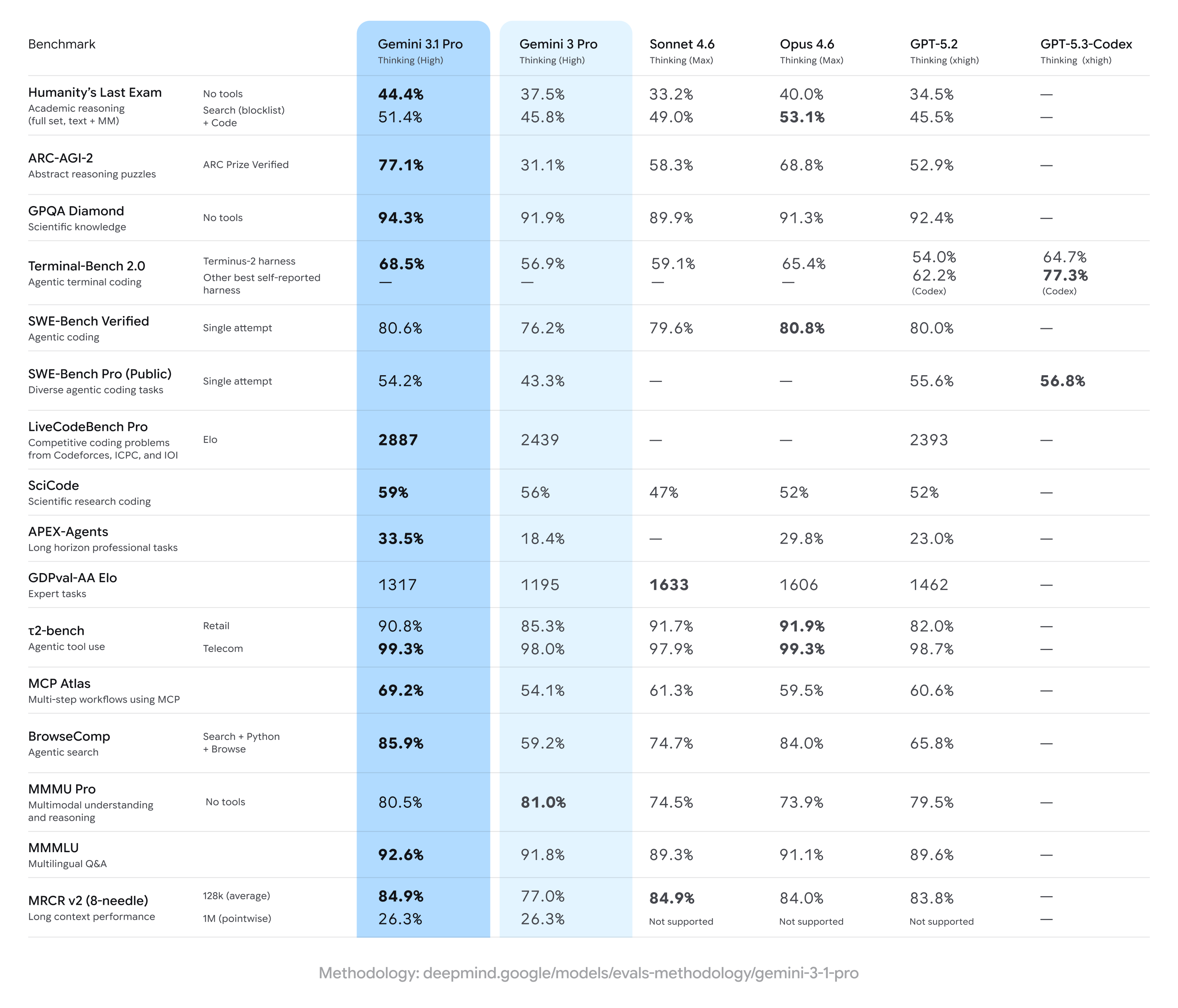
- ARC-AGI-2 (abstract redeneren / meerstaps wetenschappelijke puzzels): Gemelde stijgingen voor Gemini 3.1 Pro laten substantiële verbetering zien ten opzichte van eerdere Gemini 3 Pro-versies; één community-testpakket gaf een meer dan tweevoudige verbetering op ARC-AGI-2 vs de eerdere Gemini 3 Pro-baseline in korte, gerichte tests. Specifieke gerapporteerde scores (communitytests) plaatsen Gemini 3.1 Pro op ~77.1% op enkele ARC-stijlaggregaties (publieke rapportage).
- GPQA Diamond en wetenschapsbenchmarks op graduate-niveau: Gegevensrapporten geven aan dat Gemini 3.1 Pro recordhoogten behaalde op GPQA Diamond (een wetenschapsbenchmark op graduate-niveau), eerdere Gemini-modellen overtrof en een nieuwe mijlpaal zette voor de familie in onafhankelijke runs. Deze winst weerspiegelt de verbeterde redeneerketen en afstemming op stapsgewijze redenering.
- “Humanity’s Last Exam” met tools ingeschakeld (multi-tool, gegrond redeneren): In directe vergelijkingen met Anthropic’s Claude Opus 4.6 behaalde Claude 53.1% op deze complexe tool-enabled benchmark, terwijl Gemini 3.1 Pro 51.4% bereikte in dezelfde testronde — wat laat zien dat Gemini dichtbij zit maar niet helemaal bovenaan staat op dat specifieke multi-tool-examen.
- Coding- & terminalbenchmarks (Terminal-Bench 2.0, SWE-Bench Pro): Gespecialiseerde codingbenchmarks toonden meer divergentie. Op Terminal-Bench 2.0 met specifieke harnassen scoorden GPT-5.3-Codex-varianten rond 77.3% vs Gemini 3.1 Pro’s ~68.5% in dezelfde vergelijkingen. Op SWE-Bench Pro, publiek gerapporteerde resultaten, scoorde Gemini 3.1 Pro ~54.2% vs GPT-5.3-Codex’s 56.8% — dichterbij, maar met OpenAI’s Codex-familie die een voorsprong houdt bij gespecialiseerde programmeertaken in die runs.
- GDPval-AA Elo (rating voor expert-taken): In een Elo-stijl geaggregeerde ranking voor expert-taken scoorden Claude Sonnet/Opus-varianten hoger (bijv. ~1606–1633 punten), terwijl een publiek rapport Gemini 3.1 Pro op ~1317 punten plaatste in diezelfde dataset — wat duidt op ruimte voor verbetering bij bepaalde smalle expert-domeinen.
Resultaten uit praktijkproeven en hands-on tests
Hands-on-analyses laten zien dat Gemini 3.1 Pro bijzonder uitblinkt in:
- Samenvatting met lange context en multidocument-synthese, waar het 1M-tokenvenster artefactgevoelige opdeling vermijdt.
- Multimodale begriptaken waarbij image + text-grounding feitelijke extractie verbetert.
- Agentische automatisering (bijv. eenvoudige toolchains coördineren) — met Antigravity-proeven die aantonen dat multi-agent-tak orkestratie haalbaar is, met artefacten die elke stap vastleggen.
Waar Gemini 3.1 Pro nog achterblijft (wat de cijfers zeggen)
Geen enkel model is overal het beste. Onafhankelijke commentaren en communitytests benadrukken specifieke hiaten:
- Software-engineering- en code-onderhoudsbenchmarks (SWE-Bench Pro en soortgelijke) — Gemini 3.1 Pro blijft achter bij een concurrent (Anthropic’s Claude Opus 4.6) op taken die praktische software-engineeringvaardigheden testen: grootschalige refactors, bugtriage in rommelige codebases en sommige typen geautomatiseerde programmacorrecties. Met andere woorden, voor alledaags onderhoudswerk in engineering behouden gespecialiseerde modellen nog steeds een voorsprong in bepaalde testbedden.
- Latentiegevoelige microtaken — omdat Gemini 3.1 Pro is afgestemd op diepgang, kunnen taken die ultra-lage latency en hoge throughput vereisen (bijv. micro-inferentie voor lichte conversatie-UI’s) beter bediend worden door “Flash” of andere geoptimaliseerde varianten in de Gemini-familie.
Wat is de prijs voor Gemini 3.1 Pro?
U kunt Gemini 3.1 Pro op twee manieren gebruiken — consumentenabonnement of de ontwikkelaars-API — en de prijs verschilt per optie.
- Consument (Gemini-app / Google AI Pro): Toegang tot Gemini 3.1 Pro is inbegrepen in het Google AI Pro-abonnement, dat in de VS $19.99 / maand kost (Google biedt ook een lager “AI Plus”-niveau en een hoger “AI Ultra”-niveau). Google.
- Ontwikkelaar / API (token-gebaseerd): Als u de Gemini-modellen aanroept via de Gemini/AI-ontwikkelaars-API, wordt de prijs gemeten aan de hand van tokens. Voor de Gemini 3.x Pro-preview zijn de gepubliceerde ontwikkelaarsprijzen ongeveer: $2.00 per 1M input tokens en $12.00 per 1M output tokens voor de standaardband (≤200k prompts) — met hogere niveaus (bijv. $4/$18 per 1M) voor zeer grote contexten. (Zie de prijstabel voor de Gemini API voor volledige details en batchprijzen.)
- Als u Gemini 3.1 Pro gebruikt via CometAPI:
| Comet-prijs (USD / M tokens) | Officiële prijs (USD / M tokens) |
|---|---|
| Invoer:$1.6/M; Uitvoer:$9.6/M | Invoer:$2/M; Uitvoer:$12/M |
Prijzen voor consumentenabonnementen (Gemini-app)
Voor eindgebruikersplannen in de Gemini-app structureert Google lagen die toegang tot modelvarianten en extra features afbakenen: Google AI Pro en Google AI Ultra. Prijzen variëren per markt en valuta; gepubliceerde voorbeelden tonen Google AI Pro op $19.99/maand (met promotionele proefperiodes beschikbaar) en gelaagde valuta-prijzen worden getoond op de productpagina (inclusief proefaanbiedingen en kortstondig verlaagde tarieven). AI Ultra bundelt hogere toegang (bijv. prioritaire toegang tot nieuwe innovaties, hogere credits voor videogeneratie) tegen een hogere maandprijs. Deze consumentenplannen zijn concurrerend met andere high-end AI-abonnementen voor consumenten en zijn gepositioneerd om individuele power users of kleine teams toegang te geven tot 3.1 Pro-features zonder API-integratie.
Praktische prompt- en gebruikstips (wat ik zou doen)
Gebruik deze om betrouwbare, reproduceerbare resultaten te krijgen:
- Expliciete stappenplanner
Prompt pattern:1) Give a 3-step plan you will follow to complete X. 2) Execute step 1 and show artifact. 3) Confirm step 1 succeeded, then continue to step 2.Dit benut de sterkere stapsgewijze uitvoering van 3.1 Pro en geeft je controlepunten. - Gestructureerde output met schema’s
Vraag om JSON met een schema enstrict: true. Omdat 3.1 Pro langere, schema-conforme outputs betrouwbaarder produceert, krijg je grotere enkele responsen die je downstream kunt parsen. - Tool-check-sandwich
Wanneer je externe tools (API’s, coderunners) aanroept, laat het model produceren: plan → exacte toolaanroep (copy/paste-vriendelijk) → validatiestappen. Verifieer vervolgens de validatiestappen buiten het model voordat je doorgaat. - Pas op voor vertrouwen in één enkele stap
Zelfs als het model perfect ogende code of commando’s schrijft, voer onafhankelijke validatie uit (tests, linters, gesandboxte uitvoering) — vooral voor agentische/autonome handelingen.
Hands-on met Gemini 3.1 Pro
Proefcase 1: Onderzoeksassistent met lange context (NotebookLM / Deep Research)
Doel: Het vermogen van het model evalueren om 10–50 lange documenten (bijv. rapporten, whitepapers) samen te vatten tot een meerpagina’s tellende executive summary met citaties en actiepunten.
Opzet: Voer een corpus van in totaal 200k–800k tokens in; geef het model de taak een 2–4 pagina’s lange samenvatting te produceren met expliciete citaties en “volgende stappen”-aanbevelingen. Gebruik een herhaalbare prompttemplate en meet tijd, tokenverbruik (kosten) en feitelijke nauwkeurigheid.
Resultaten: Snellere end-to-end-samenvatting met minder opdelingsartefacten vergeleken met oudere modellen, hogere citatiefideliteit in de samenvatting en verbeterde coherentie op schaal — tegen de prijs van aanzienlijk tokenverbruik (dus plan het budget). Benchmarks en hands-on tests tonen dat Gemini 3.1 Pro uitblinkt in multidocument-synthese dankzij het 1M-tokenvenster.
Proefcase 2: Agentische programmeerassistent (Antigravity + GitHub Copilot)
Doel: Reductie meten in time-to-complete voor meerstaps ontwikkelaarstaken (bijv. een feature implementeren over meerdere bestanden, tests draaien, falende tests repareren).
Opzet: Gebruik Antigravity of GitHub Copilot in preview met Gemini 3.1 Pro geselecteerd. Definieer reproduceerbare taken (issuecreatie → implementeren → tests draaien), log stappen en agentartefacten, en vergelijk met een mens-only baseline.
Resultaten: Verbeterde orkestratie van meerstapstaken (artefactregistratie, automatische suggestie van patch-kandidaten), betere redenering over meerdere bestanden dan eerdere Gemini 3 Pro, en meetbare tijdswinst op routinematig featurewerk. Gespecialiseerde laag-niveau systeemdebuggingtaken kunnen nog steeds in het voordeel zijn van gespecialiseerde code-first modellen (communityresultaten tonen een kloof vs sommige GPT-Codex-varianten op bepaalde terminalbenchmarks).
Proefcase 3: Multimodale juridische/medische documentbeoordeling
Doel: Het model gebruiken om een gemengd corpus (gescande PDF’s, afbeeldingen, audiotranscripten) te verwerken, kernfeiten te extraheren en een risicomatrix en geprioriteerde acties te produceren.
Opzet: Lever een dataset met gescande afbeeldingen en OCR-tekst, plus ondersteunende audio. Meet precisie in named entity-extractie, false-positiveratio en het vermogen van het model om naar bronartefacten te verwijzen.
results: Sterkere geïntegreerde redenering over modaliteiten en beter traceerbare outputs (vermogen om te verwijzen naar de afbeelding / pagina / audiotijdstempel die een bewering ondersteunt). Het lange contextvenster vermindert de behoefte aan handmatige opdeling en cross-referencing. In gereguleerde domeinen moeten outputs echter worden gevalideerd door domeinexperts en moet een grounding-/verificatiepijplijn worden gebruikt.
Eerste indrukken (wat voelt anders)
- Diepere stapsgewijze redenering. Taken die eerder meerdere heen-en-weer interacties vereisten — bijv. multidocument-synthese, meerstaps wiskunde/logica — worden vaker voltooid in minder rondes en met duidelijkere chain-of-thought-stijl outputs (zonder interne instructietekst bloot te leggen). Dit is de headline die Google benadrukte.
- Langere, hoogwaardige gestructureerde outputs. JSON en long-form automatiseringen zijn consistenter en vaak veel langer (sommige gebruikers meldden outputs die veel groter zijn dan 3.0). Dat maakt het uitstekend voor generatorjobs waarbij je één grote payload wilt. Verwacht grotere outputs en streaming te moeten verwerken.
- Efficiënter token-/contextbeheer. Verbeterde tokenefficiëntie en meer “gegrond, feitelijk consistente” gedragingen voor scenarios met toolgebruik. Dat uit zich in minder hallucinaties bij korte feitelijke opzoekingen.
Eindanalyse: is Gemini 3.1 Pro nu de moeite waard om te adopteren?
Gemini 3.1 Pro vertegenwoordigt een betekenisvolle stap vooruit in de Gemini-familie met aantoonbare verbeteringen op redenerings-, coderings- en agentische benchmarks — ondersteund door Google’s gepubliceerde modelkaart en onafhankelijke trackers die grote sprongen op geselecteerde ranglijsten citeren. Voor teams die geavanceerde redenering, agentische toolcoördinatie of multimodale capaciteiten met lange context nodig hebben, is 3.1 Pro een overtuigende kandidaat.
Ontwikkelaars kunnen Gemini 3.1 Pro nu gebruiken via CometAPI. Om te beginnen, verken de mogelijkheden van het model in de Playground en raadpleeg de API-gids voor gedetailleerde instructies. Voordat u toegang krijgt, zorg ervoor dat u bent ingelogd bij CometAPI en de API-sleutel heeft verkregen. CometAPI biedt een prijs die veel lager ligt dan de officiële prijs om u te helpen integreren.
Ready to Go?→ Meld u vandaag nog aan voor Gemini 3.1 Pro !
Als u meer tips, gidsen en nieuws over AI wilt weten, volg ons op VK, X en Discord!