

Op 3 maart 2026 introduceerde Google Gemini 3.1 Flash-Lite, het nieuwste lid van de Gemini 3-familie, specifiek ontworpen als een engine met hoge doorvoer, lage latentie en kostenefficiëntie voor workloads van ontwikkelaars en ondernemingen. Google positioneert Flash-Lite als het “snelste en meest kostenefficiënte” model in de Gemini 3-lijn: een lichtgewicht variant die is gericht op het leveren van streaminginteracties, grootschalige achtergrondverwerking en hoogfrequente productietaken (bijvoorbeeld vertaling, extractie, UI-generatie en grootschalige classificatie) tegen een veel lagere prijs dan de Pro-tegenhangers.
Hieronder leggen we uit wat Flash-Lite is.
Wat is Gemini 3.1 Flash-Lite
Gemini 3.1 Flash-Lite maakt deel uit van Google’s Gemini 3-familie en ruilt bewust een deel van de hoogste redeneerkracht in voor snelheid en kostenefficiëntie. Het is in de Gemini-lijn van nature multimodaal (kan tekst, afbeeldingen en andere modaliteiten als input accepteren), maar is specifiek getuned en uitgerold om maximale doorvoer in tokens per seconde en aanzienlijk lagere kosten per token te leveren voor workloads die snelle, herhaalde inferentie vereisen in plaats van maximale cognitieve diepte. Het model is beschreven als afgeleid van de 3.1 Pro-architectuur, maar geoptimaliseerd voor doorvoer, latentie en kosten.
Belangrijkste ontwerpafwegingen
De term “Lite” duidt op de technische focus van het model:
- Doorvoer boven zwaarwegend redeneren: Flash-Lite verlaagt bewust de compute per token om een snellere Time-to-First-Token (TTFT) en voortdurende uitvoersnelheid te leveren. Dat maakt het ideaal voor pijplijnen waarin elk verzoek snel en op schaal moet worden bediend (bijv. veiligheidsfilters, realtime-assistenten, generatie met hoog volume).
- Kostenefficiëntie voor hoge volumes: Door de compute per token te verlagen, kan het model worden aangeboden tegen lagere prijzen per miljoen tokens, wat de marginale kosten in grootschalige toepassingen reduceert (bijv. miljoenen tot miljarden tokens per maand). Google’s preview-prijzen laten een significant verschil ten opzichte van de Pro-laag zien.
- Kwaliteit afgestemd op pragmatische taken: Volgens vroege scoreoverzichten behoudt Flash-Lite sterke resultaten op standaardclassificatie, meertaligheid en veel multimodale taken, maar het is niet gepositioneerd om Pro te verslaan op de meest complexe meerstapsredenering of codegeneratiebenchmarks waarbij diepte cruciaal is.
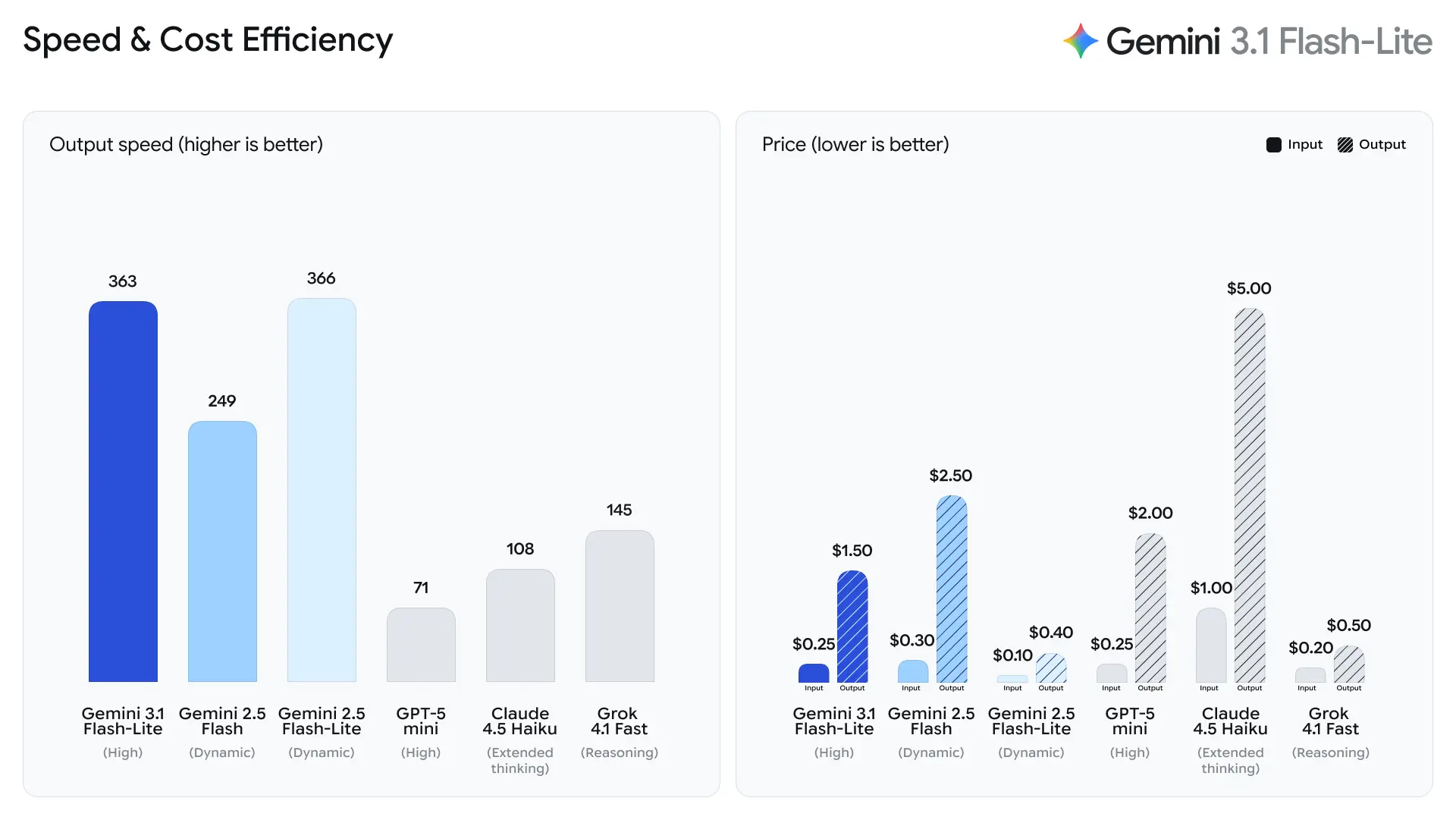
Deze workloads vereisen betrouwbare output en hoge doorvoer, maar ze vereisen niet altijd de complexe meerstapsredeneercapaciteiten van vlaggenschipmodellen.
Belangrijkste functies van Gemini 3.1 Flash-Lite
1. Lage latentie en snelle tijd tot het eerste token
Google benadrukt time-to-first-answer token als een primaire metriek voor Flash-Lite. Het bedrijf rapporteert ~2.5× sneller time-to-first-token vergeleken met Gemini 2.5 Flash en tot 45% sneller outputgeneratie — verbeteringen die direct van invloed zijn op de waargenomen responsiviteit voor eindgebruikers en de doorvoerkosten voor back-endsystemen. Deze winst maakt Flash-Lite zeer geschikt voor interactieve functies (bijv. chatbots ingebed in apps) en high-QPS-pijplijnen waar microseconden ertoe doen.
Deze verbetering komt realtime-toepassingen zoals de volgende significant ten goede:
- conversationele AI
- door AI aangestuurde zoekassistenten
- interactieve chatbots
- livevertaaldiensten
Lagere latentie verbetert de gebruikerservaring door de wachttijd te reduceren en vloeiendere interacties mogelijk te maken.
2. Kostenefficiënte tokenprijzen
De kosten voor AI-inferentie worden vaak per token berekend, waardoor prijsstelling een cruciale factor is voor grootschalige implementaties.
Gemini 3.1 Flash-Lite introduceert een zeer concurrerende prijsstructuur:
| Tokentype | Prijs |
|---|---|
| Invoertokens | $0.25 per 1M tokens |
| Uitvoertokens | $1.50 per 1M tokens |
Dit is een verlaging ten opzichte van eerdere Flash-modellen, waardoor het model aantrekkelijk is voor organisaties die grote workloads draaien.
Ter vergelijking:
| Model | Invoerprijs | Uitvoerprijs |
|---|---|---|
| Gemini 3 Flash | $0.50 / 1M | $3.00 / 1M |
| Gemini 3.1 Flash-Lite | $0.25 / 1M | $1.50 / 1M |
Met deze prijsstrategie kunnen ontwikkelaars AI op schaal draaien zonder de operationele kosten drastisch te verhogen.
Als je op zoek bent naar een nog betere prijs, biedt Gemini Flash-Lite 20% korting op CometAPI.
3. “Thinking levels” (regelbare inferentiediepte)
Gemini 3.1 Flash-Lite bevat de functie “thinking levels” — een door ontwikkelaars instelbare parameter die het model instrueert om sneller, oppervlakkiger te werken voor triviale taken en dieper te redeneren voor moeilijkere taken. Dit is in de praktijk belangrijk omdat het dynamische kosten-/latentieafwegingen per request mogelijk maakt zonder van model te wisselen.
Ontwikkelaars kunnen de redeneerkracht van het model configureren op basis van de complexiteit van de taak. Thinking levels: ondersteunt vier niveaus: Minimal, Low, Medium en High.
Met deze dynamische aanpak kunnen applicaties het middelengebruik optimaliseren en tegelijk de kwaliteit behouden waar het ertoe doet. De praktische strategie is ongeveer als volgt:
- Minimal/Low: Geschikt voor taken met hoge gelijktijdigheid maar logische eenvoud, zoals vertaling, classificatie en sentimentsanalyse, met prioriteit op maximale snelheid en minimale kosten.
- Medium: Geschikt voor de meeste productietaken, met een evenwicht tussen kwaliteit en efficiëntie.
- High: Geschikt voor taken die diepe redenering vereisen, zoals het genereren van gebruikersinterfaces, het creëren van simulaties en het uitvoeren van complexe instructies.
4. Multimodale mogelijkheden met een lichtgewicht footprint
Hoewel Flash-Lite is geoptimaliseerd voor snelheid en kosten, behoudt het de multimodale basis van de Gemini 3-lijn: het kan beeldinput accepteren voor classificatie of lichte multimodale redenering wanneer het gebruiksscenario dat vereist — maar ontwikkelaars moeten verwachten dat het economische ontwerp de voorkeur geeft aan kortere, begrensde multimodale operaties boven zeer grote beeldintensieve workflows. Net als andere Gemini-modellen ondersteunt Gemini 3.1 Flash-Lite multimodale input, waardoor ontwikkelaars verschillende datatypes kunnen verwerken.
Ondersteunde input omvat:
- Tekst
- Afbeeldingen
- Video
- Audio
- PDF's
Het vermogen van het model om meerdere informatietypen te analyseren maakt nieuwe use-cases mogelijk, zoals:
- geautomatiseerde documentverwerking
- visuele data-extractie
- multimedia-samenvatting
Eerdere Gemini-modellen toonden ook sterke multimodale redeneercapaciteiten op visuele en kennisbenchmarks.
Prestatiebenchmarks — echte cijfers en wat ze betekenen
De aankondiging en productdocumentatie van Google presenteren verschillende benchmarkdatapunten die kopers moeten helpen begrijpen waar Flash-Lite binnen het ecosysteem past.
Ontwikkelaarsgerichte snelheidsstatistieken
- 2.5× sneller Time to First Answer Token vs Gemini 2.5 Flash (door Google aangegeven interne vergelijking).
- 45% snellere outputgeneratie vs Gemini 2.5 Flash.
Dit zijn performance-engineeringmetriek in plaats van door mensen beoordeelde kwaliteitsmetriek; ze weerspiegelen verbeteringen in runtime-microarchitectuur, batching en optimalisaties in de inferentiestack die latentie voor korte antwoorden verminderen. Snellere first-token-tijden verminderen de waargenomen vertraging in interactieve applicaties en verhogen de algehele doorvoer per server, wat de totale compute-kosten kan verlagen voor dezelfde QPS.
Tokens per seconde (t/s) en doorvoer
Volgens testgegevens van Artificial Analysis behaalde 3.1 Flash-Lite een uitvoersnelheid van 388.8 tokens per seconde (de mediaan voor modellen in dezelfde prijsklasse is slechts 96.7 tokens/seconde). Deze snelheid is topniveau binnen zijn klasse.
Artificial Analysis wees echter ook op een probleem: de first token latentie (TTFT) van 3.1 Flash-Lite is 5.18 seconden, wat relatief hoog is voor inferentiemodellen in dezelfde prijsklasse (de mediaan is 1.82 seconden). Daarnaast genereerde het model 53 miljoen tokens tijdens het evaluatieproces, wat relatief hoog is vergeleken met het gemiddelde van 20 miljoen. Dit betekent dat als je scenario zeer gevoelig is voor first-token-latentie of strikte eisen stelt aan bondigheid van de output, je mogelijk het denkniveau en de prompts moet optimaliseren.
Benchmarkresultaten voor redeneren en feitelijkheid
Google nam vergelijkingen tussen modellen op waaruit blijkt dat Gemini 3.1 Flash-Lite sterk presteert ten opzichte van tijdgenoten en eerdere Gemini-varianten op geaggregeerde redenerings-/feitelijke taken:
- Arena.ai Elo-score: Gemini 3.1 Flash-Lite behaalde naar verluidt een Elo van 1432 op het Arena-evaluatieklassement — een samengestelde head-to-head-ranking die competitieve relatieve prestaties in directe vergelijkingen toont.
- GPQA Diamond: 86.9% (een maatstaf voor de robuustheid van vraagbeantwoording).
- MMMU Pro: 76.8% (een multimodale/multitask-metriek die intern/extern door sommige labs wordt gebruikt).
- LiveCodeBench (Coding Ability): 72.0%
- CharXiv Reasoning (Graphical Reasoning): 73.2%
- Video-MMMU (Video Comprehension): 84.8%
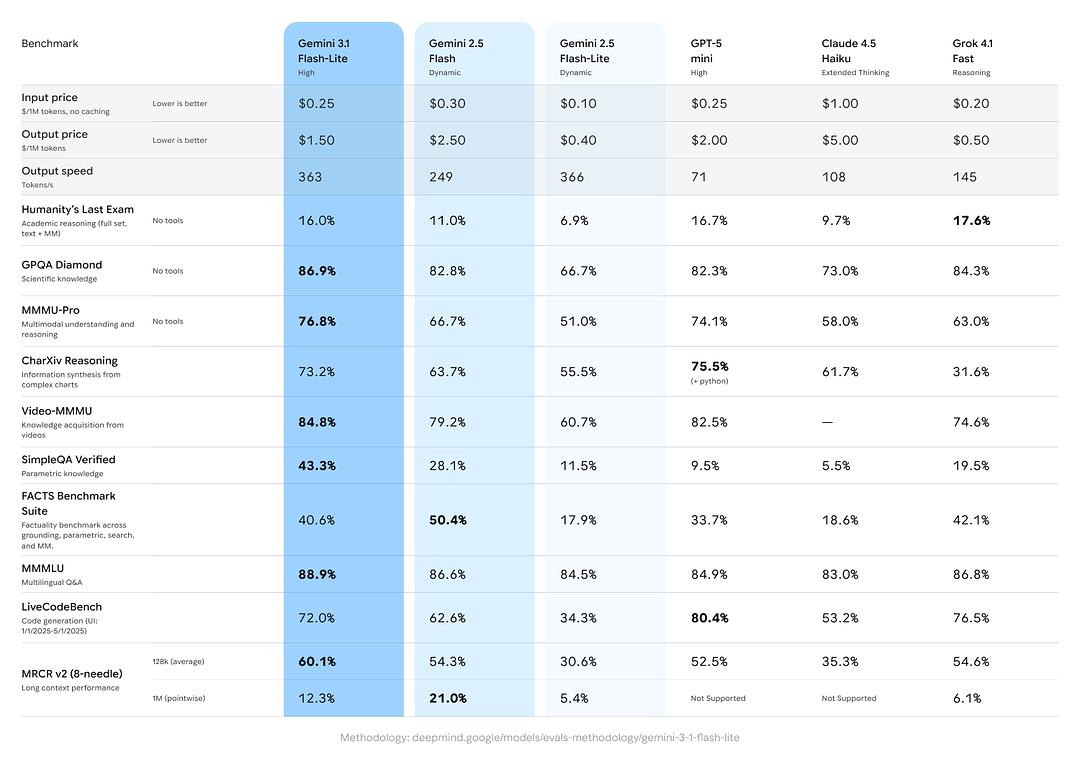
Gemini 3.1 Flash-Lite overtreft oudere Gemini 2.5 Flash op meerdere van deze metriek terwijl het veel betere snelheid/kosten levert.
Gebruiksscenario’s die passen bij Gemini 3.1 Flash-Lite
Gemini 3.1 Flash-Lite is ontworpen rond een duidelijke set praktische workloads waarbij hoge doorvoer en lagere kosten per token doorslaggevend zijn:
Conversatieagents met hoge frequentie en streaming-UI
Realtime chatbots, live transcriptie + vertaalstreams en collaboratieve UI’s die gedeeltelijke antwoorden tonen terwijl het model genereert, profiteren van de streamingtoken-output en de lage time-to-first-token van Flash-Lite.
Verwerking van bulksgewijze data (RAG, transformatiepijplijnen)
Massale documentinname: entiteitsextractie, metadatatagging, classificatie en vertalingen over miljoenen documenten — Gemini 3.1 Flash-Lite verlaagt de inferentiekosten en levert tegelijkertijd acceptabele nauwkeurigheid voor getemplate of regelgestuurde outputs.
Edge-achtige of achtergrondcompute
Workloads die binnenkomende telemetrie of ongestructureerde data continu verwerken (bijv. pijplijnen voor contentmoderatie en classificatie, geautomatiseerde rapportgeneratie) zijn een goede match omdat Gemini 3.1 Flash-Lite de kosten per eenheid minimaliseert.
Ontwikkelaarstools en batch-codeaanvulling
Voor features zoals scaffolding over meerdere bestanden, grootschalige code linting en sjabloongeneratie op schaal verminderen de snelheidsvoordelen van Gemini 3.1 Flash-Lite latentie en kosten voor ontwikkelaarservaringstools waar absolute maximale redeneerkracht niet vereist is.
Vergelijking tussen Gemini 3.1 Flash-Lite en andere Gemini-modellen en concurrenten
Binnen de Gemini-familie
- Gemini 3.1 Pro: hoogste capaciteit op complexe redenering en meerstapsplanning; aanzienlijk duurder en trager per token maar beter voor diepe, genuanceerde taken.
- Gemini 3.1 Flash (niet-Lite): richt zich op een middenweg tussen ruwe doorvoer en capaciteit — Flash-Lite optimaliseert verder omlaag in de computestack voor doorvoer.
Vergeleken met concurrerende “snelle” modellen
Gemini 3.1 Flash-Lite overtreft of evenaart verschillende snelle/mini-modellen op veel doorvoer- en kwaliteitsmetriek — al waarschuwen onafhankelijke analisten dat directe vergelijkingen gevoelig zijn voor evaluatiemethodologie en datasetselectie. Verwacht dat Gemini 3.1 Flash-Lite zeer concurrerend is in doorvoer en kosten, terwijl het in het midden van het veld blijft op de hoogste redeneermetriek.
Conclusie — waar Flash-Lite past in de AI-stack
Gemini 3.1 Flash-Lite is een doelbewust ontworpen aanbod: een efficiënte, doorvoergerichte telg van de Gemini 3-familie waarmee teams een deel van de compute per voorbeeld kunnen inruilen voor drastische verbeteringen in latentie en kosten. Voor bedrijven en ontwikkelaars die hoogvolume-pijplijnen bouwen — vertalingen, batchverwerking, streaming-UI’s en taken met gemiddelde complexiteit — vormt Flash-Lite een verstandig baseline-engine. Voor organisaties die de absoluut hoogste redeneernauwkeurigheid nodig hebben, blijven de Pro-modellen de juiste keuze.
Als je workload wordt gedomineerd door veel korte, herhaalbare inferenties of als je snelle streamingoutput op grote schaal nodig hebt, is Flash-Lite het proberen waard. Als je workload leunt op diepe multi-hop-redenering, plan dan een hybride aanpak: routeer doorvoertraffic naar Flash-Lite en escaleer hoogwaardige, complexe queries naar Pro-modellen.
Ontwikkelaars hebben nu toegang tot Gemini 3.1 Flash Lite via CometAPI. Begin met het verkennen van de mogelijkheden van het model in de Playground en raadpleeg de API guide voor gedetailleerde instructies. Zorg ervoor dat je bent ingelogd bij CometAPI en een API-sleutel hebt verkregen voordat je toegang vraagt. CometAPI biedt een prijs die veel lager is dan de officiële prijs om je te helpen integreren.
Klaar om te beginnen?→ Meld je vandaag aan voor Gemini 3.1 Flash-Lite !
Als je meer tips, gidsen en nieuws over AI wilt, volg ons op VK, X en Discord!