

Qwen2.5-VL-32B API heeft de aandacht getrokken vanwege zijn buitengewone prestatie in verschillende complexe taken, waarbij beide worden gecombineerd beeld- en tekstgegevens voor een verrijkt begrip van de wereld. Ontwikkeld door AlibabaDit model met 32 miljard parameters is een upgrade van het eerdere Qwen2.5-VL serie, die de grenzen van AI-gestuurd redeneren en visueel begrip.

Overzicht van Qwen2.5-VL-32B
Qwen2.5-VL-32B is een geavanceerd, open-source multimodaal model ontworpen om een reeks taken uit te voeren met zowel tekst als afbeeldingen. Met zijn 32 miljard parameters, het biedt een krachtige architectuur besteld, beeldherkenning, wiskundig redeneren, dialoog generatie, en nog veel meer. Het is verbeterd leermogelijkheden, op basis van reinforcement learning, kunnen antwoorden worden gegenereerd die beter aansluiten bij menselijke voorkeuren.
Belangrijkste kenmerken en functies
Qwen2.5-VL-32B toont opmerkelijke mogelijkheden op meerdere domeinen:
Beeldbegrip en beschrijving: Dit model blinkt uit in foto analyse, objecten en scènes nauwkeurig identificeren. Het kan gedetailleerde, natuurlijke taalbeschrijvingen genereren en zelfs gedetailleerde inzichten in objectkenmerken en hun relaties.
Wiskundig redeneren en logica:Het model is uitgerust om complexe wiskundige problemen op te lossen, variërend van geometrie naar algebra- door gebruik te maken van meerstaps redenering met duidelijke logica en gestructureerde uitkomsten.
Tekstgeneratie en dialoog: Met zijn geavanceerde taalmodel genereert Qwen2.5-VL-32B coherente en contextueel relevante antwoorden op basis van invoertekst of afbeeldingen. Het ondersteunt ook dialoog met meerdere beurten, waardoor interacties natuurlijker en doorlopend kunnen plaatsvinden.
Visuele vraag beantwoorden:Het model kan vragen beantwoorden die betrekking hebben op de inhoud van afbeeldingen, zoals Object herkenning en scène beschrijving, die geavanceerde visuele logica en gevolgtrekkingsmogelijkheden biedt.
Technische basisprincipes van Qwen2.5-VL-32B
Om de kracht achter Qwen2.5-VL-32B te begrijpen, is het cruciaal om de technische principes te verkennen. Hieronder staan de belangrijkste aspecten die bijdragen aan de prestaties:
- Multimodale pre-training:Het model is vooraf getraind met behulp van grootschalige datasets bestaande uit beide tekst- en beeldgegevensHierdoor kan het diverse visuele en taalkundige kenmerken leren, wat naadloos cross-modaal begrip mogelijk maakt.
- Transformator-architectuur: Gebouwd op de robuuste Transformer-architectuurhet model maakt gebruik van zowel de encoder en decoder structuren om beeld- en tekstinvoer te verwerken, en zeer nauwkeurige uitvoer te genereren. zelf-aandacht mechanisme stelt het in staat zich te concentreren op kritische componenten binnen de invoergegevens, waardoor de nauwkeurigheid wordt verbeterd.
- Optimalisatie van versterkend leren: Qwen2.5-VL-32B profiteert van reinforcement learning, waarbij het wordt verfijnd op basis van menselijke feedback. Dit proces zorgt ervoor dat de reacties van het model nauwkeuriger zijn afgestemd op menselijke voorkeuren terwijl meerdere doelstellingen worden geoptimaliseerd, zoals nauwkeurigheid, logicaen vlotheid.
- Visuele-taaluitlijning: Door contrastief leren en afstemmingsstrategieën, het model zorgt ervoor dat beide visuele kenmerken en tekstuele informatie zijn goed geïntegreerd in de taalruimtewaardoor het zeer effectief is voor multimodale taken.
Prestaties Highlights
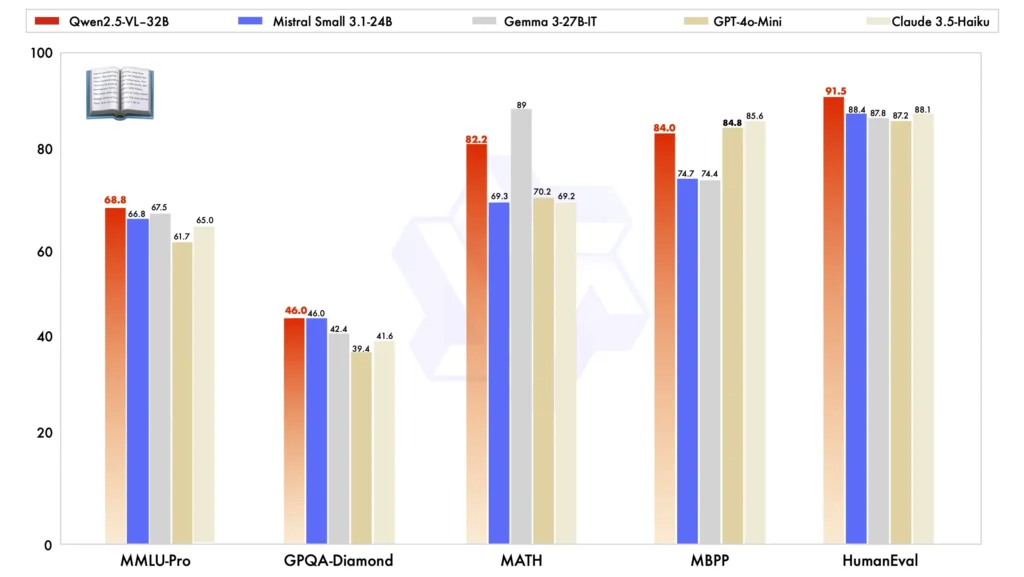
Vergeleken met andere grootschalige modellen onderscheidt de Qwen2.5-VL-32B zich in verschillende belangrijke benchmarks, wat zijn superieure prestaties in beide multimodaal en taken met platte tekst:
Modelvergelijking:: Tegen andere modellen zoals Mistral-Klein-3.1-24B en Gemma-3-27B-IT, Qwen2.5-VL-32B toont aanzienlijk verbeterde mogelijkheden. Opvallend is dat het zelfs presteert beter dan de grotere Qwen2-VL-72B in verschillende taken.
Multimodale taakprestaties: In complexe multimodale taken zoals MMMU, MMMU-Proen MathVistaDe Qwen2.5-VL-32B blinkt uit en levert nauwkeurige resultaten waarmee hij zich onderscheidt van andere modellen van vergelijkbare grootte.
MM-MT-Bench Benchmark: Vergeleken met zijn voorganger, Qwen2-VL-72B-Instruct, laat de nieuwe versie een aanzienlijke verbetering zien, met name op het gebied van logische redenering en multimodaal redeneren mogelijkheden.
Prestaties van platte tekst: Bij taken op basis van platte tekst is Qwen2.5-VL-32B de beste keuze gebleken topartiest in zijn klasse, met verbeterde tekstgeneratie, redeneringen algehele nauwkeurigheid.
Projectbronnen
Voor ontwikkelaars en AI-enthousiastelingen die Qwen2.5-VL-32B verder willen verkennen, zijn er verschillende belangrijke bronnen beschikbaar:
- Officiële website: Qwen2.5-VL-32B-project
- Knuffelend Gezicht Model: Knuffelgezicht Qwen2.5-VL-32B-Instrueren
Toepassingen in de echte wereld
De veelzijdigheid van de Qwen2.5-VL-32B maakt hem geschikt voor een breed scala aan praktische toepassingen in verschillende sectoren:
Intelligente klantenservice:Het model kan worden gebruikt om automatisch klantvragen te verwerken, waarbij gebruik wordt gemaakt van het vermogen om de klantvragen te begrijpen en te genereren. tekst- en beeldgebaseerde reacties.
Educatieve hulp: Door het oplossen wiskundige problemen, tolken afbeelding inhouden concepten uitleggen, kan het het leerproces voor studenten aanzienlijk verbeteren.
Annotatie afbeelding: In contentmanagementsystemen kan Qwen2.5-VL-32B de generatie van afbeeldingsbijschriften en omschrijvingenwaardoor het een onmisbaar hulpmiddel is voor de media- en creatieve industrie.
Autonoom rijden:Door verkeersborden en verkeersomstandigheden te analyseren met behulp van visuele verwerkingsmogelijkheden, kan het model realtime inzichten bieden om de verkeersveiligheid te verbeteren. veilig rijden.
Content Creatie: In de media en reclame kan het model tekst op basis van visuele prikkels, waarmee makers van content aantrekkelijke verhalen voor video's en advertenties kunnen produceren.
Toekomstperspectieven en uitdagingen
Hoewel Qwen2.5-VL-32B een grote stap voorwaarts betekent op het gebied van multimodale AI, liggen er nog steeds uitdagingen en kansen in het verschiet. Scherpstellen het model voor meer specifieke taken, het integreren ervan met realtime-applicaties en het verbeteren ervan schaalbaarheid Om complexere multimodale datasets te kunnen verwerken, is voortdurend onderzoek en ontwikkeling nodig.
Bovendien, naarmate er meer AI-modellen met vergelijkbare mogelijkheden worden uitgebracht, Etnische twijfels omringende door AI gegenereerde content, vooringenomenheiden data Privacy blijven aandacht krijgen. Ervoor zorgen dat Qwen2.5-VL-32B en vergelijkbare modellen op een verantwoorde manier worden getraind en gebruikt, is cruciaal voor hun succes op de lange termijn.
Verwante onderwerpen:De 8 populairste AI-modellen vergelijking van 2025
Conclusie
Qwen2.5-VL-32B is een krachtig hulpmiddel in het arsenaal van AI-modellen die zijn ontworpen om multimodale taken met indrukwekkende nauwkeurigheid en verfijning. Door geavanceerde integratie versterking van leren, transformator architectuuren visuele-taaluitlijninghet is niet alleen overtreft eerdere modellen maar opent ook spannende mogelijkheden voor industrieën variërend van onderwijs naar autonoom rijdenAls open-sourcetechnologie biedt het ontwikkelaars en AI-gebruikers enorme mogelijkheden om te experimenteren, optimaliseren en implementeren in echte toepassingen.
Hoe Qwen2.5-VL-32B API aan te roepen vanuit CometAPI
1.Login naar cometapi.com. Als u nog geen gebruiker van ons bent, registreer u dan eerst
2.Haal de API-sleutel voor toegangsreferenties op van de interface. Klik op "Token toevoegen" bij de API-token in het persoonlijke centrum, haal de tokensleutel op: sk-xxxxx en verstuur.
-
Haal de url van deze site op: https://api.cometapi.com/
-
Selecteer het Qwen2.5-VL-32B-eindpunt om de API-aanvraag te verzenden en stel de aanvraagbody in. De aanvraagmethode en aanvraagbody worden verkregen van onze website API-doc. Onze website biedt ook een Apifox-test voor uw gemak.
-
Verwerk de API-respons om het gegenereerde antwoord te krijgen. Nadat u de API-aanvraag hebt verzonden, ontvangt u een JSON-object met de gegenereerde voltooiing.