

Op 19–20 november 2025 bracht OpenAI twee verwante maar verschillende upgrades uit: GPT-5.1-Codex-Max, een nieuw agentisch programmeermodel voor Codex dat nadruk legt op langetermijncoderen, token-efficiëntie en “compaction” om multi-venster-sessies vol te houden; en GPT-5.1 Pro, een bijgewerkt ChatGPT-model voor de Pro-laag, afgestemd op duidelijkere, capabelere antwoorden bij complexe, professionele werkzaamheden.
Wat is GPT-5.1-Codex-Max en welk probleem probeert het op te lossen?
GPT-5.1-Codex-Max is een gespecialiseerd Codex-model van OpenAI, afgestemd op programmeerworkflows die volgehouden, lange-horizon redeneren en uitvoering vereisen. Waar gewone modellen kunnen struikelen over extreem lange contexten — bijvoorbeeld multi-bestandsrefactors, complexe agent-lussen of persistente CI/CD-taken — is Codex-Max ontworpen om sessiestatus automatisch te compacten en te beheren over meerdere contextvensters, zodat het coherent kan blijven werken wanneer één project vele duizenden (of meer) tokens beslaat. OpenAI positioneert Codex-Max als de volgende stap om code-capabele agents daadwerkelijk bruikbaar te maken voor langdurig engineeringwerk.
Wat is GPT-5.1-Codex-Max en welk probleem probeert het op te lossen?
GPT-5.1-Codex-Max is een gespecialiseerd Codex-model van OpenAI, afgestemd op programmeerworkflows die volgehouden, lange-horizon redeneren en uitvoering vereisen. Waar gewone modellen kunnen struikelen over extreem lange contexten — bijvoorbeeld multi-bestandsrefactors, complexe agent-lussen of persistente CI/CD-taken — is Codex-Max ontworpen om sessiegeschiedenis automatisch te compacten en te beheren over meerdere contextvensters, zodat het coherent kan blijven werken wanneer één project vele duizenden (of meer) tokens beslaat.
OpenAI omschrijft het als “sneller, intelligenter en token-efficiënter in elke fase van de ontwikkelcyclus” en het is expliciet bedoeld om GPT-5.1-Codex te vervangen als het standaardmodel in Codex-oppervlakken.
Functieoverzicht
- Compaction voor continuïteit over meerdere vensters: snoeit en bewaart kritieke context om coherent te werken over miljoenen tokens en uren. 0
- Verbeterde token-efficiëntie vergeleken met GPT-5.1-Codex: tot circa 30% minder denktokens voor vergelijkbare redeneerinspanning op sommige codebenchmarks.
- Lang-horizon agentische duurzaamheid: intern waargenomen dat multi-uur/multi-dag agent-lussen worden volgehouden (OpenAI documenteerde interne runs van >24 uur).
- Platformintegraties: vandaag beschikbaar in Codex CLI, IDE-extensies, cloud en code-reviewtools; API-toegang volgt.
- Ondersteuning voor Windows-omgevingen: OpenAI vermeldt specifiek dat Windows voor het eerst wordt ondersteund in Codex-workflows, wat het bereik onder ontwikkelaars in de praktijk vergroot.
Hoe verhoudt het zich tot concurrerende producten (bijv. GitHub Copilot, andere coding-AI’s)?
GPT-5.1-Codex-Max wordt gepresenteerd als een autonomere, lange-horizon samenwerkingspartner vergeleken met hulpmiddelen die per verzoek aanvullen. Terwijl Copilot en soortgelijke assistenten uitblinken in kortetermijnaanvullingen binnen de editor, liggen de sterke punten van Codex-Max in het orkestreren van meerstapstaken, het coherent beheren van status over sessies heen, en het afhandelen van workflows die planning, testen en iteratie vereisen. Toch is in de meeste teams een hybride aanpak het beste: gebruik Codex-Max voor complexe automatisering en volgehouden agent-taken en gebruik lichtere assistenten voor aanvullingen op regelniveau.
Hoe werkt GPT-5.1-Codex-Max?
Wat is “compaction” en hoe maakt het langdurig werk mogelijk?
Een centrale technische vooruitgang is compaction—een intern mechanisme dat sessiegeschiedenis snoeit terwijl de essentiële stukken context behouden blijven, zodat het model coherent werk kan voortzetten over meerdere contextvensters. In de praktijk betekent dit dat Codex-sessies die hun contextlimiet naderen, worden gecompact (oudere of minder waardevolle tokens samengevat/bewaard) zodat de agent een nieuw venster heeft en herhaaldelijk kan blijven itereren totdat de taak voltooid is. OpenAI meldt interne runs waarin het model onafgebroken meer dan 24 uur aan taken werkte.
Adaptief redeneren en token-efficiëntie
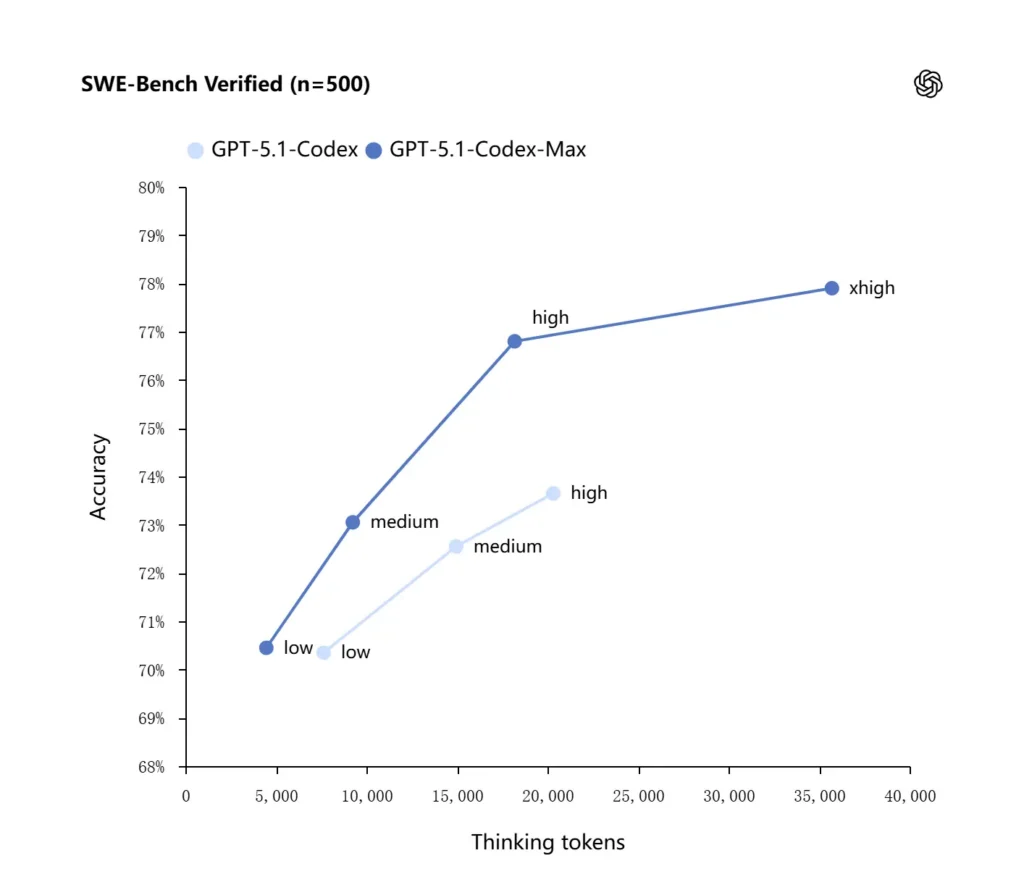
GPT-5.1-Codex-Max past verbeterde redeneerstrategieën toe die het token-efficiënter maken: in de door OpenAI gerapporteerde interne benchmarks haalt het Max-model vergelijkbare of betere prestaties dan GPT-5.1-Codex terwijl het significant minder “denktokens” gebruikt—OpenAI noemt ongeveer 30% minder denktokens op SWE-bench Verified bij gelijke redeneerinspanning. Het model introduceert ook een “Extra High (xhigh)” redeneerinspanningmodus voor taken die niet gevoelig zijn voor latency, waardoor het meer interne redenering kan besteden om tot outputs van hogere kwaliteit te komen.
Systeemintegraties en agentische tooling
Codex-Max wordt verspreid binnen Codex-workflows (CLI, IDE-extensies, cloud en code-review-oppervlakken) zodat het kan interageren met daadwerkelijke developer-toolchains. Vroege integraties omvatten de Codex CLI en IDE-agents (VS Code, JetBrains, enz.), met geplande API-toegang. Het ontwerppdoel is niet alleen slimmere codegeneratie, maar een AI die meerstapsworkflows kan draaien: bestanden openen, tests uitvoeren, fouten herstellen, refactoren en opnieuw draaien.
Hoe presteert GPT-5.1-Codex-Max op benchmarks en in echt werk?
Volgehouden redeneren en lange-horizontaken
Evaluaties wijzen op meetbare verbeteringen in volgehouden redeneren en lange-horizontaken:
- Interne evaluaties van OpenAI: Codex-Max kan in interne experimenten “meer dan 24 uur” aan taken werken en het integreren van Codex met ontwikkeltools verhoogde interne engineeringproductiviteitsstatistieken (bijv. gebruik en PR-doorvoer). Dit zijn interne claims van OpenAI en wijzen op taakniveauverbeteringen in productiviteit in de echte wereld.
- Onafhankelijke evaluaties (METR): METR’s onafhankelijk rapport mat de waargenomen 50%-tijdhorizon (een statistiek die de mediane tijd representeert waarin het model een lange taak coherent kan volhouden) voor GPT-5.1-Codex-Max op ongeveer 2 uur en 40 minuten (met een breed betrouwbaarheidsinterval), tegenover 2 uur en 17 minuten voor GPT-5 in vergelijkbare metingen — een betekenisvolle, trendmatige verbetering in volgehouden coherentie. METR’s methodologie en CI benadrukken variabiliteit, maar het resultaat ondersteunt het verhaal dat Codex-Max de praktische lange-horizonprestaties verbetert.
Codebenchmarks
OpenAI rapporteert verbeterde resultaten op frontier-codingevaluaties, met name SWE-bench Verified waar GPT-5.1-Codex-Max GPT-5.1-Codex overtreft met betere token-efficiëntie. Het bedrijf benadrukt dat bij dezelfde “medium” redeneninspanning het Max-model betere resultaten produceert terwijl het ongeveer 30% minder denktokens gebruikt; voor gebruikers die langere interne redenering toestaan, kan de xhigh-modus antwoorden verder verbeteren ten koste van latency.
| GPT‑5.1-Codex (high) | GPT‑5.1-Codex-Max (xhigh) | |
| SWE-bench Verified (n=500) | 73,7% | 77,9% |
| SWE-Lancer IC SWE | 66,3% | 79,9% |
| Terminal-Bench 2.0 | 52,8% | 58,1% |
Hoe verhoudt GPT-5.1-Codex-Max zich tot GPT-5.1-Codex?
Prestatie- en doelverschillen
- Reikwijdte: GPT-5.1-Codex was een hoogwaardige codevariant van de GPT-5.1-familie; Codex-Max is expliciet een agentische, lange-horizon opvolger die bedoeld is als aanbevolen standaard voor Codex- en Codex-achtige omgevingen.
- Token-efficiëntie: Codex-Max laat materiële efficiëntiewinsten zien (OpenAI’s claim van circa 30% minder denktokens) op SWE-bench en in intern gebruik.
- Contextbeheer: Codex-Max introduceert compaction en native multi-vensterafhandeling om taken vol te houden die één contextvenster te boven gaan; Codex bood deze mogelijkheid niet op dezelfde schaal.
- Tooling-gereedheid: Codex-Max wordt geleverd als het standaard Codex-model in de CLI-, IDE- en code-review-oppervlakken, wat een migratie voor ontwikkelworkflows in productie signaleert.
Wanneer gebruik je welk model?
- Gebruik GPT-5.1-Codex voor interactieve programmeerhulp, snelle edits, kleine refactors en use-cases met lage latency waarin de volledige relevante context eenvoudig in één venster past.
- Gebruik GPT-5.1-Codex-Max voor refactors over meerdere bestanden, geautomatiseerde agentische taken die veel iteratiecycli vereisen, CI/CD-achtige workflows, of wanneer je wilt dat het model een projectperspectief over veel interacties heen vasthoudt.
Praktische promptpatronen en voorbeelden voor de beste resultaten?
Promptpatronen die goed werken
- Wees expliciet over doelen en beperkingen: “Refactor X, behoud de publieke API, behoud functienamen en zorg dat tests A,B,C slagen.”
- Lever minimale reproduceerbare context: link naar de falende test, voeg stacktraces toe en relevante bestandsfragmenten in plaats van hele repositories te dumpen. Codex-Max zal de geschiedenis compacten waar nodig.
- Gebruik stapsgewijze instructies voor complexe taken: breek grote klussen op in een reeks subtaken en laat Codex-Max erdoor itereren (bijv. “1) tests draaien 2) top 3 falende tests fixen 3) linter draaien 4) wijzigingen samenvatten”).
- Vraag om verklaringen en diffs: vraag zowel de patch als een korte onderbouwing, zodat menselijke reviewers snel intentie en veiligheid kunnen beoordelen.
Voorbeeldprompt-sjablonen
Refactortaak
“Refactor de
payment/-module om betalingsverwerking te extraheren naarpayment/processor.py. Houd publieke functiesignaturen stabiel voor bestaande aanroepers. Maak unittests voorprocess_payment()die succes, netwerkfout en ongeldige kaart afdekken. Draai de testsuite en geef falende tests en een patch in unified diff-formaat terug.”
Bugfix + test
“Een test
tests/test_user_auth.py::test_token_refreshfaalt met traceback. Onderzoek de oorzaak, stel een fix voor met minimale wijzigingen, en voeg een unittest toe om regressie te voorkomen. Pas de patch toe en draai tests.”
Iteratieve PR-generatie
“Implementeer feature X: voeg endpoint
POST /api/exporttoe dat exportresultaten streamt en geauthenticeerd is. Maak het endpoint, voeg documentatie toe, maak tests en open een PR met samenvatting en checklist van handmatige items.”
Voor de meeste hiervan start je met medium inspanning; schakel over op xhigh wanneer je het model diep wilt laten redeneren over veel bestanden en meerdere testiteraties.
Hoe krijg je toegang tot GPT-5.1-Codex-Max
Waar het vandaag beschikbaar is
OpenAI heeft GPT-5.1-Codex-Max geïntegreerd in Codex-tooling: de Codex CLI, IDE-extensies, cloud en code-reviewflows gebruiken standaard Codex-Max (je kunt kiezen voor Codex-Mini). API-beschikbaarheid wordt voorbereid; GitHub Copilot heeft openbare previews die GPT-5.1- en Codex-seriemodellen bevatten.
Ontwikkelaars kunnen toegang krijgen tot GPT-5.1-Codex-Max en de GPT-5.1-Codex API via CometAPI. Om te beginnen, verken de modelmogelijkheden van CometAPI in de Playground en raadpleeg de API-gids voor gedetailleerde instructies. Zorg ervoor dat je bent ingelogd bij CometAPI en een API-sleutel hebt verkregen voordat je toegang vraagt. CometAPI biedt een prijs die veel lager ligt dan de officiële prijs om je te helpen integreren.
Klaar om te beginnen?→ Meld je vandaag nog aan voor CometAPI !
Wil je meer tips, gidsen en nieuws over AI, volg ons op VK, X en Discord!
Snelstart (praktische stapsgewijze aanpak)
- Zorg dat je toegang hebt: bevestig dat je ChatGPT/Codex-productplan (Plus, Pro, Business, Edu, Enterprise) of je ontwikkelaars-API-plan de GPT-5.1/Codex-familiemodellen ondersteunt.
- Installeer de Codex CLI of IDE-extensie: als je code-taken lokaal wilt draaien, installeer de Codex CLI of de Codex IDE-extensie voor VS Code / JetBrains / Xcode, indien van toepassing. De tooling gebruikt in ondersteunde setups standaard GPT-5.1-Codex-Max.
- Kies redeneerinspanning: begin met medium inspanning voor de meeste taken. Schakel voor diep debuggen, complexe refactors of wanneer je wilt dat het model langer nadenkt en je niet om responstijd geeft, over op high of xhigh. Voor kleine, snelle fixes is low passend.
- Lever repositorycontext: geef het model een duidelijk startpunt — een repo-URL of een set bestanden en een korte instructie (bijv. “refactor de payment-module naar async I/O en voeg unittests toe, behoud contracten op functieniveau”). Codex-Max zal de geschiedenis compacten naarmate het contextlimieten nadert en de klus voortzetten.
- Itereren met tests: nadat het model patches produceert, draai testsuites en geef falingen terug als onderdeel van de lopende sessie. Compaction en continuïteit over meerdere vensters laten Codex-Max belangrijke context van falende tests behouden en itereren.
Conclusie:
GPT-5.1-Codex-Max vertegenwoordigt een substantiële stap richting agentische programmeerassistenten die complexe, langdurige engineeringtaken met verbeterde efficiëntie en redeneren kunnen volhouden. De technische vooruitgangen (compaction, modi voor redeneerinspanning, training op Windows-omgevingen) maken het bijzonder geschikt voor moderne engineeringorganisaties — mits teams het model combineren met conservatieve operationele controles, duidelijke human-in-the-loop-beleid en robuuste monitoring. Voor teams die het zorgvuldig adopteren, heeft Codex-Max het potentieel om te verschuiven hoe software wordt ontworpen, getest en onderhouden — en om repetitief, arbeidsintensief werk om te vormen tot een waardevollere samenwerking tussen mensen en modellen.