

DeepSeek heeft DeepSeek V3.2 uitgebracht als de opvolger van de V3.x-lijn en een bijbehorende variant DeepSeek-V3.2-Speciale die het bedrijf positioneert als een high-performance, reasoning-first editie voor agent-/toolgebruik. V3.2 bouwt voort op experimenteel werk (V3.2-Exp) en introduceert hogere redeneercapaciteit, een Speciale-editie geoptimaliseerd voor “goudniveau” wiskunde/competitief programmeren, en wat DeepSeek omschrijft als een dual‑modus “denken + tool”-systeem van een nieuw type dat interne stap‑voor‑stap‑redenering strak integreert met externe toolaanroepen en agent‑workflows.
Wat is DeepSeek V3.2 — en hoe verschilt V3.2‑Speciale?
DeepSeek‑V3.2 is de officiële opvolger van DeepSeek’s experimentele V3.2‑Exp‑tak. Het wordt door DeepSeek beschreven als een “reasoning‑first” modelfamilie gebouwd voor agents, d.w.z. modellen die niet alleen zijn afgestemd op natuurlijke gesprekskwaliteit, maar specifiek op meerstapsinferentie, toolaanroepen en betrouwbare chain‑of‑thought‑stijl redenering in omgevingen met externe tools (API’s, code‑executie, dataconnectoren).
Wat is DeepSeek‑V3.2 (basis)
- Gepositioneerd als de mainstream productiesuccesor van de experimentele V3.2‑Exp‑lijn; bedoeld voor brede beschikbaarheid via de app/web/API van DeepSeek.
- Houdt een balans tussen rekenefficiëntie en robuuste redenering voor agenttaken.
Wat is DeepSeek‑V3.2‑Speciale
DeepSeek‑V3.2‑Speciale is een variant die DeepSeek in de markt zet als een “Special Edition” met hogere capaciteit, afgestemd op redeneren op wedstrijdniveau, geavanceerde wiskunde en agentprestaties. Gepositioneerd als een variant met hogere capaciteit die “de grenzen van de redeneercapaciteiten verlegt.” DeepSeek stelt Speciale momenteel beschikbaar als een API‑only model met tijdelijke toegangsroutering; vroege benchmarks suggereren dat het is gepositioneerd om te concurreren met high‑end gesloten modellen op redeneer‑ en codeerbenchmarks.
Welke herkomst en engineeringkeuzes leidden tot V3.2?
V3.2 erft een lijn van iteratieve engineering die DeepSeek in 2025 publiek maakte: V3 → V3.1 (Terminus) → V3.2‑Exp (een experimentele stap) → V3.2 → V3.2‑Speciale. Het experimentele V3.2‑Exp introduceerde DeepSeek Sparse Attention (DSA) — een fijnmazig sparse‑attention‑mechanisme dat is gericht op het verlagen van geheugen‑ en rekengesprekken voor zeer lange contextlengtes, terwijl de outputkwaliteit behouden blijft. Dat DSA‑onderzoek en het kostenreductiewerk vormden een technische opstap voor de officiële V3.2‑familie.
Wat is er nieuw in de officiële DeepSeek 3.2?
1) Verbeterd redeneervermogen — hoe is het redeneren verbeterd?
DeepSeek positioneert V3.2 als “reasoning‑first.” Dat betekent dat de architectuur en fine‑tuning gericht zijn op het betrouwbaar uitvoeren van meerstapsinferentie, het onderhouden van interne denk‑ketens, en het ondersteunen van de soorten gestructureerde afwegingen die agents nodig hebben om externe tools correct te gebruiken.
Concreet omvatten de verbeteringen:
- Training en RLHF (of vergelijkbare aligneringsprocedures) afgestemd om expliciete stap‑voor‑stap probleemoplossing en stabiele tussenstaten aan te moedigen (nuttig voor wiskundig redeneren, meerstaps codegeneratie en logische taken).
- Architectuur‑ en loss‑function‑keuzes die langere contextvensters behouden en het model in staat stellen eerdere redeneerstappen met hoge betrouwbaarheid te refereren.
- Praktische modi (zie “dual‑modus” hieronder) die hetzelfde model laten werken in een snellere “chat”-modus of in een bedachtzame “denk”-modus waarin het bewust tussenstappen doorloopt voordat het handelt.
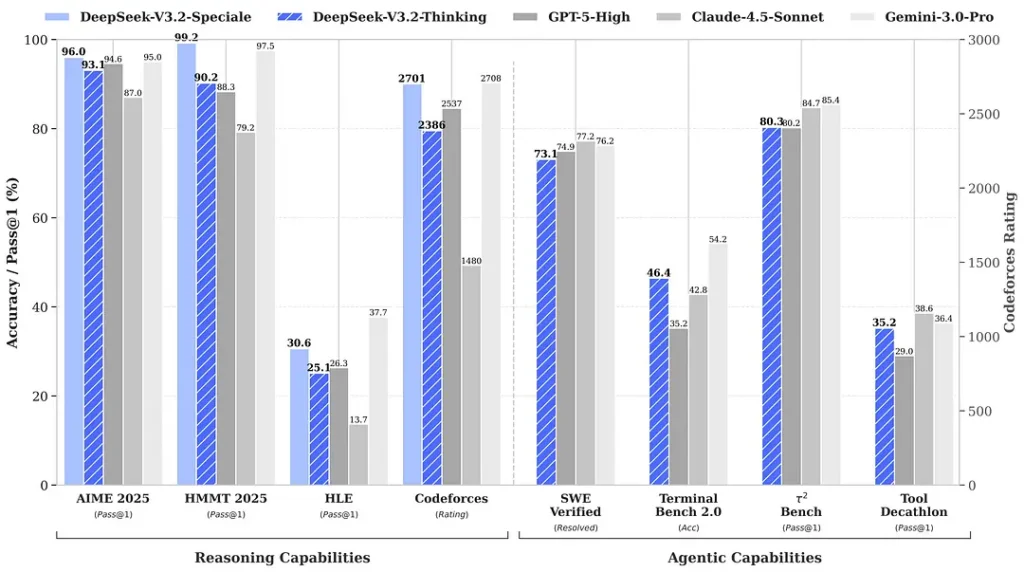
Rond de release aangehaalde benchmarks claimen opmerkelijke winsten in wiskunde‑ en redeneersuites; onafhankelijke vroege communitybenchmarks melden eveneens indrukwekkende scores op competitieve evaluatiesets:
2) Doorbraakprestaties in de Special Edition — hoeveel beter?
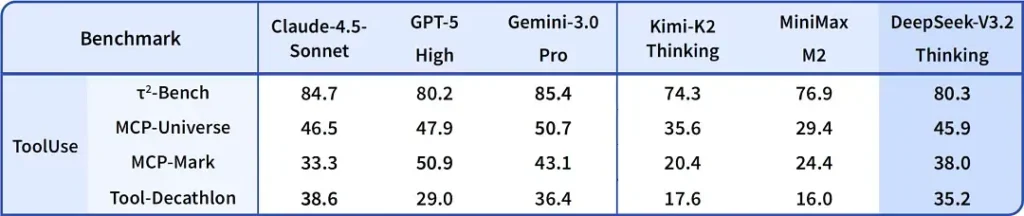
DeepSeek‑V3.2‑Speciale zou een stap vooruit leveren in redeneernauwkeurigheid en agentorkestratie vergeleken met de standaard V3.2. De aanbieder kadert Speciale als een prestatieniveau gericht op zware redeneerworkloads en uitdagende agenttaken; het is momenteel alleen via API beschikbaar en aangeboden als een tijdelijk, endpoint met hogere capaciteit (DeepSeek gaf aan dat de beschikbaarheid van Speciale aanvankelijk beperkt zal zijn). De Speciale‑versie integreert het eerdere wiskundige model DeepSeek‑Math‑V2; het kan wiskundige stellingen bewijzen en logische redenering zelfstandig verifiëren; het heeft opmerkelijke resultaten behaald in meerdere wereldklasse competities:
- 🥇 IMO (International Mathematical Olympiad) Gouden Medaille
- 🥇 CMO (Chinese Mathematical Olympiad) Gouden Medaille
- 🥈 ICPC (International Computer Programming Contest) Tweede Plaats (Menselijke wedstrijd)
- 🥉 IOI (International Olympiad in Informatics) Tiende Plaats (Menselijke wedstrijd)
| Benchmark | GPT-5 High | Gemini-3.0 Pro | Kimi-K2 Thinking | DeepSeek-V3.2 Thinking | DeepSeek-V3.2 Speciale |
|---|---|---|---|---|---|
| AIME 2025 | 94.6 (13k) | 95.0 (15k) | 94.5 (24k) | 93.1 (16k) | 96.0 (23k) |
| HMMT Feb 2025 | 88.3 (16k) | 97.5 (16k) | 89.4 (31k) | 92.5 (19k) | 99.2 (27k) |
| HMMT Nov 2025 | 89.2 (20k) | 93.3 (15k) | 89.2 (29k) | 90.2 (18k) | 94.4 (25k) |
| IMOAnswerBench | 76.0 (31k) | 83.3 (18k) | 78.6 (37k) | 78.3 (27k) | 84.5 (45k) |
| LiveCodeBench | 84.5 (13k) | 90.7 (13k) | 82.6 (29k) | 83.3 (16k) | 88.7 (27k) |
| CodeForces | 2537 (29k) | 2708 (22k) | — | 2386 (42k) | 2701 (77k) |
| GPQA Diamond | 85.7 (8k) | 91.9 (8k) | 84.5 (12k) | 82.4 (7k) | 85.7 (16k) |
| HLE | 26.3 (15k) | 37.7 (15k) | 23.9 (24k) | 25.1 (21k) | 30.6 (35k) |
3) Eerste implementatie ooit van een dual‑modus “denken + tool”-systeem
Een van de meest praktische claims in V3.2 is een dual‑modus workflow die snelle conversatie‑operatie scheidt van (en laat kiezen tussen) een langzamere, bedachtzame “denk”-modus die strak integreert met toolgebruik.
- “Chat / fast”‑modus: Ontworpen voor low‑latency, gebruikersgerichte chat met bondige antwoorden en minder interne redeneertracés — goed voor casual hulp, korte Q&A en snelheidssensitieve toepassingen.
- “Thinking / reasoner”‑modus: Geoptimaliseerd voor rigoureuze chain‑of‑thought, stapsgewijze planning en het orkestreren van externe tools (API’s, databasequeries, code‑executie). In denkmodus produceert het model explicietere tussenstappen, die kunnen worden geïnspecteerd of gebruikt om veilige, correcte toolaanroepen in agentsystemen aan te sturen.
Dit patroon (een twee‑modusontwerp) was aanwezig in eerdere experimentele takken, en DeepSeek heeft het dieper geïntegreerd in V3.2 en Speciale — Speciale ondersteunt momenteel exclusief de denkmodus (vandaar de API‑afscherming). De mogelijkheid om te schakelen tussen snelheid en bedachtzaamheid is waardevol voor engineering, omdat ontwikkelaars daarmee de juiste trade‑off kunnen maken tussen latency en betrouwbaarheid bij het bouwen van agents die met systemen in de echte wereld moeten interacteren.
Waarom het opmerkelijk is: Veel moderne systemen bieden óf een sterk chain‑of‑thought‑model (om redenering toe te lichten) óf een aparte agent/tool‑orkestratielaag. DeepSeek’s framing suggereert een nauwere koppeling — het model kan “denken” en vervolgens deterministisch tools aanroepen, waarbij toolresponsen de volgende denkstappen informeren — wat naadlozer is voor ontwikkelaars die autonome agents bouwen.
Waar DeepSeek v3.2 te krijgen
Kort antwoord — je kunt DeepSeek v3.2 op verschillende manieren verkrijgen, afhankelijk van je behoefte:
- Officiële web/app (online gebruiken) — probeer de webinterface of mobiele app van DeepSeek om V3.2 interactief te gebruiken.
- API‑toegang — DeepSeek stelt V3.2 beschikbaar via hun API (docs bevatten modelnamen / base_url en prijzen). Meld je aan voor een API‑sleutel en roep het v3.2‑endpoint aan.
- Downloadbare/open gewichten (Hugging Face) — het model (V3.2 / V3.2‑Exp varianten) is gepubliceerd op Hugging Face en kan worden gedownload (open‑weight). Gebruik
huggingface-huboftransformersom de bestanden op te halen. - CometAPI — een AI‑API‑aggregatieplatform dat gehoste endpoints voor V3.2‑Exp biedt. De prijs is lager dan de officiële prijs.
Een paar praktische opmerkingen:
- Wil je gewichten lokaal draaien, ga dan naar de Hugging Face‑modelpagina (accepteer daar eventuele licentie-/toegangsvoorwaarden) en gebruik
huggingface-clioftransformersom te downloaden; de GitHub‑repo toont meestal de exacte commando’s. - Wil je productiegebruik via API, volg dan het platform van je keuze, zoals de CometAPI‑API‑documentatie voor endpointnamen en de juiste
base_urlvoor de V3.2‑variant.
DeepSeek-V3.2-Speciale:* Alleen voor onderzoekstoepassing, ondersteunt “Thinking Mode”-dialoog, maar ondersteunt geen toolaanroepen.
- Maximale output kan 128K tokens bereiken (ultralange denk‑keten).
- Momenteel gratis te testen tot en met 15 december 2025.
Tot slot
DeepSeek‑V3.2 vormt een betekenisvolle stap in de volwassenwording van redeneringsgerichte modellen. De combinatie van verbeterde meerstapsredenering, gespecialiseerde high‑performance edities (Speciale), en een geproductiviseerd “denken + tool”-integratiemodel is opmerkelijk voor iedereen die geavanceerde agents, codeerassistenten of onderzoeksworkflows bouwt die afwegingen moeten verweven met externe acties.
Ontwikkelaars kunnen toegang krijgen tot DeepSeek V3.2 via CometAPI. Begin met het verkennen van de modelcapaciteiten van CometAPI in de Playground en raadpleeg de API‑handleiding voor gedetailleerde instructies. Zorg er vóór toegang voor dat je bent aangemeld bij CometAPI en een API‑sleutel hebt verkregen. CometAPI biedt een prijs die veel lager is dan de officiële prijs om je te helpen integreren.
Klaar om te beginnen?→ Meld je vandaag nog aan voor CometAPI!
Wil je meer tips, gidsen en nieuws over AI? Volg ons op VK, X en Discord!