

Gemini Embedding 2 is Google's eerste natief multimodale embeddingmodel dat tekst, afbeeldingen, audio, video en PDF's projecteert in één semantische vectorruimte met 3.072 dimensies (met configureerbare uitvoergroottes). Het introduceert Matryoshka Representation Learning om geneste/afgekorte embeddings te bieden, verbeterde meertalige prestaties (100+ talen) en geoptimaliseerde regelaars voor taakspecifieke embeddings (bijv. task:search, task:code).
Wat is Gemini Embedding 2?
Gemini Embedding 2 is een uniform embeddingmodel van Google dat meerdere invoermodaliteiten — tekst, afbeeldingen, audio, video en documenten — in één semantische vectorruimte projecteert. Elke embedding is (standaard) een drijvende-komma vector van 3.072 dimensies die de semantische betekenis van de input weergeeft, zodat semantisch vergelijkbare items (ongeacht modaliteit) dicht bij elkaar liggen in de vectorruimte. De belangrijkste mogelijkheden zijn:
- Brede taal- en formaatdekking: één model dat tekst, afbeeldingen, audio, video en documenten accepteert en ze in één semantische vectorruimte plaatst. Volgens de documentatie legt Gemini Embedding 2 semantische intentie vast in 100+ talen en accepteert het gangbare bestandsformaten (PNG's/JPEG's, MP4/MOV, MP3/WAV, PDF), met concrete limieten per aanvraag (bijv. tot een handvol afbeeldingen of tientallen seconden audio/video per aanvraag — zie “How to use” hieronder).
- Echte multimodaliteit: één model dat tekst, afbeeldingen, audio, video en documenten accepteert en ze in één semantische vectorruimte plaatst, zodat je modaliteiten kunt vergelijken of ophalen (bijv. tekst → afbeelding, audio → tekst).
- Grote standaarddimensionaliteit met flexibele truncatie: het model geeft standaard 3072-dimensionale vectoren terug, maar gebruikt Matryoshka Representation Learning (MRL) om de belangrijkste semantische inhoud in de eerste dimensies te concentreren, zodat je kunt afkorten naar 1536, 768 (of lager) met slechts bescheiden kwaliteitsverlies bij retrieval. Dit vermindert de afwegingen tussen opslag en compute-kosten.
Waarom dit ertoe doet. Historisch waren embeddings meestal alleen tekst of vereisten ze afzonderlijke encoders per modaliteit met complexe cross-modale alignementlagen. Gemini Embedding 2 haalt die barrière weg door meerdere formaten natief te ondersteunen — zodat een tekstquery een afbeelding of korte clip kan ophalen op basis van semantische gelijkenis zonder tussentijdse transcriptie of handmatige mapping. Dat vereenvoudigt RAG (retrieval-augmented generation), semantisch zoeken en multimodale retrieval-pipelines.
Belangrijkste functies & mogelijkheden (wat is nieuw)
1. Echte native multimodaliteit (één embeddingruimte)
Eén model dat tekst, afbeeldingen, audio, video en documenten accepteert en ze in één semantische vectorruimte plaatst. Gemini Embedding 2 projecteert tekst, afbeeldingen, audio, video en documenten in dezelfde embeddingruimte, zodat cross-modale retrieval (tekst→afbeelding, audio→tekst) direct werkt zonder cross-model alignement. Dit vermindert de complexiteit van de pipeline en vereenvoudigt RAG-stacks (Retrieval-Augmented Generation).
2. 3.072-dimensionale standaardvectoren met instelbare uitvoer
Gemini Embedding 2 geeft standaard 3072-dimensionale vectoren terug, maar gebruikt Matryoshka Representation Learning (MRL) om de belangrijkste semantische inhoud in de eerste dimensies te concentreren, zodat je kunt afkorten naar 1536, 768 (of lager) met slechts bescheiden kwaliteitsverlies bij retrieval. Dit vermindert afwegingen tussen opslag en compute-kosten.
3. Matryoshka Representation Learning (MRL)
MRL produceert “geneste” embeddings — zoals Russische matroesjkapoppen — zodat lagere-dimensionale slices hogere-orde semantiek behouden. Hierdoor kunnen systemen een werkpunt kiezen (afweging opslag/nauwkeurigheid) zonder meerdere afzonderlijke embeddingmodellen te hoeven onderhouden. Vroege bloganalyses en documentatie beschrijven deze techniek als een kerninnovatie voor flexibiliteit.
4. Taakhints / aangepaste embeddingdoelen
De API accepteert task-hints (bijv. task:search, task:code retrieval, task:semantic-similarity) zodat het model de embedding-geometrie kan optimaliseren voor specifieke downstreamrelaties — vergelijkbaar met taakconditionering in eerdere embeddingsystemen maar uitgebreid naar multimodale input.
5. Taal- en modaliteitsbreedte
Volgens de documentatie legt Gemini Embedding 2 semantische intentie vast in 100+ talen en accepteert het gangbare bestandsformaten (PNG's/JPEG's, MP4/MOV, MP3/WAV, PDF), met concrete limieten per aanvraag (bijv. tot een handvol afbeeldingen of tientallen seconden audio/video per aanvraag — zie “How to use” hieronder).
Prestatiebenchmarks
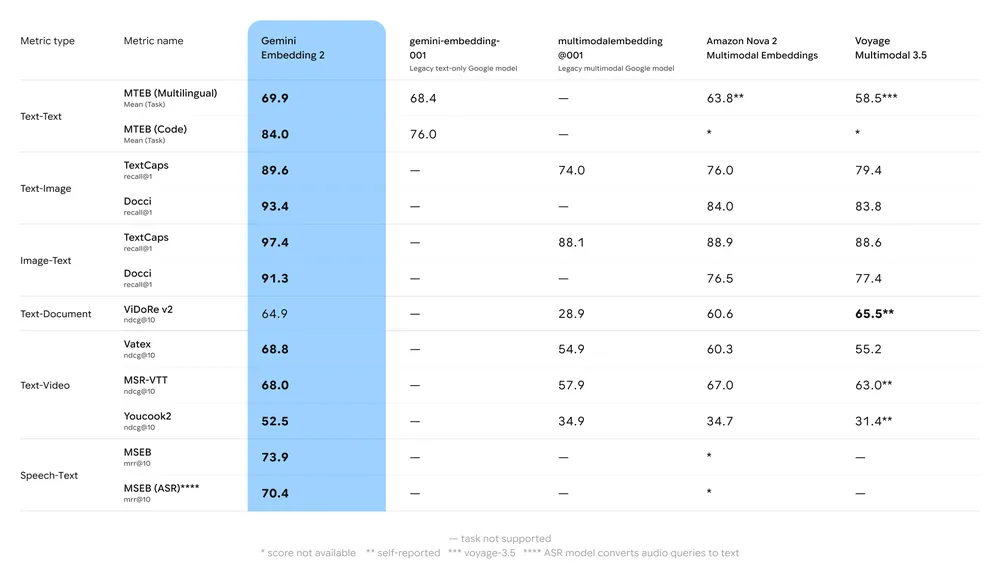
Samenvatting van de belangrijkste benchmarks:
- MTEB (Massive Text Embedding Benchmark): Gerapporteerde sterke positie op meertalige MTEB-leaderboards voor Engelse en meertalige taken; analyses tonen een betekenisvolle verbetering ten opzichte van Gemini's eerdere embeddingmodellen en veel propriëtaire alternatieven.
- Multimodale retrieval: Evenaart of overtreft toonaangevende enkel-modale embeddings bij cross-modale gelijkenis (bijv. tekst→afbeelding-retrieval) dankzij native multimodale training.
- Latentie & doorvoer: Cloud-gehoste embeddinggeneratie, maar latentiegevoelige use-cases geven mogelijk de voorkeur aan afgekorte vectoren of alternatieve lichte embeddingmodellen voor on-edge behoeften.
Gemini Embedding 2 vs gemini-embedding-001 en text-embedding-3-large
| Attribuut | Gemini Embedding 2 (embedding-2) | Gemini Embedding (gemini-embedding-001) | OpenAI text-embedding-3-large |
|---|---|---|---|
| Release / beschikbaarheid | 10 mrt 2026 — publieke preview (Gemini API / Vertex AI). | Eerdere Gemini-embedding (alleen-tekstvarianten) — GA eerder. | Aangekondigd jan 2024 (alleen-tekst GA). |
| Ondersteunde modaliteiten | Tekst, afbeeldingen, audio, video, documenten (PDF) — uniforme vectorruimte. | Tekst (primair). | Alleen tekst (meertalige hoge kwaliteit). |
| Standaard embedding-dim. | 3072 (MRL / truncatie aanbevolen: 1536, 768). | 3072 (voor large) — alleen tekst. | 3072 (text-embedding-3-large). |
| Gerapporteerde MTEB (vb.) | Hoog in de 60; toont 68.17 bij 1536 in vendor-tabel (zie docs). | gemini-embedding-001 gerapporteerd ~68.32 mean in sommige lijsten. | ~64.6 (MTEB-gemiddelde gerapporteerd door OpenAI voor text-embedding-3-large). |
| Native audio/video support | Ja (directe audio-/video-embedding). | Nee (alleen tekst). | Nee (alleen tekst). |
| Typische use-cases | Multimodale retrieval, RAG, semantisch zoeken over bestandstypen, spraakretrieval, videozoek. | Tekstretrieval, meertalige RAG. | Tekstretrieval, semantisch zoeken, RAG — sterke meertalige tekstprestaties. |
Technische specificaties & limieten
Standaard & instelbare embeddinggrootte
- Standaard: 3,072 dimensies.
- Instelbaar: met de parameter
output_dimensionalitykun je lagere dimensionale uitvoer aanvragen om opslag/CPU te besparen. Use-cases met massale vectorstores reduceren dims vaak naar 512–1,024 om kostenredenen, met enige nauwkeurigheidstrade-off.
Ondersteunde modaliteiten en limieten per aanvraag
- Afbeeldingen: PNG, JPEG — tot 6 afbeeldingen per aanvraag (door de leverancier gerapporteerde limieten).
- Video: MP4, MOV — leverancier meldt tot ~128 seconden per video voor embedding in een enkele aanvraag.
- Audio: MP3, WAV — leverancier meldt tot ~80 seconden per audio-invoer.
- Documenten: PDF's — tot 6 pagina's per aanvraag (volgens leverancier).
- Tokenlimiet voor tekstuele content: model ondersteunt grote tokeninvoer; in de praktijk bestaan per-aanvraag tokenlimieten (raadpleeg de API-docs en Vertex AI-quotas).
Beschikbaarheid & toegang
- Publieke preview: Gemini Embedding 2 is uitgebracht als publieke preview en is beschikbaar via de Gemini API en Google Cloud's Vertex AI voor directe experimentele inzet
Veelgestelde vragen (FAQ)
Q1: Welke modaliteiten ondersteunt Gemini Embedding 2?
A: Tekst, afbeeldingen (PNG/JPEG), video (MP4/MOV), audio (MP3/WAV) en PDF-documenten — allemaal geprojecteerd in dezelfde semantische vectorruimte.
Q2: Wat is de standaard vectorgrootte voor Gemini Embedding 2?
A: Standaard 3,072 dimensies. Je kunt via de API een kleinere outputdimensionaliteit aanvragen.
Q3: Is Gemini Embedding 2 nu beschikbaar?
A: Ja — het is aangekondigd als publieke preview en beschikbaar via de Gemini API en Vertex AI (controleer het model-id gemini-embedding-2-preview en de huidige changelog).
Q4: Hoe verhoudt het zich tot embeddings van andere aanbieders?
A: Onafhankelijke leverancierstests rapporteren dat Gemini Embedding 2 tot de top van propriëtaire modellen behoort voor meertalige tekst en state-of-the-art prestaties laat zien voor verschillende multimodale taken. Exacte rankings variëren per taak en dataset; test op je eigen data.
Q5: Moet ik audio transcriberen om Gemini Embedding 2 te gebruiken?
A: Nee — Gemini Embedding 2 kan audio direct accepteren en embeddings produceren zonder eerst naar tekst te transcriberen, wat end-to-end semantische retrieval van audio mogelijk maakt.
Q6: Hoe verlaag ik opslagkosten voor 3,072-dim vectoren?
A: Opties zijn onder meer lagere output_dimensionality aanvragen, float16/quantization/PQ gebruiken, en gecomprimeerde representaties opslaan in je vector-DB. Leveranciersposts bieden workflows en best practices.
Wat komt hierna — moet ik het nu adopteren?
Gemini Embedding 2 is een grote stap in het verenigen van multimodale retrieval en vereenvoudigt architecturen die voorheen afzonderlijke retrievers voor tekst, beeld en spraak vereisten. De belangrijkste beslispunten voor adoptie:
- Adopteer sneller als je product robuuste cross-modale retrieval (tekst↔afbeelding/video/audio) nodig heeft, of als het onderhouden van meerdere enkel-modale retrievers kostbaar en complex is.
- Piloteer nu als je MRL-truncatie wilt evalueren en kosten versus kwaliteit wilt meten (houd een hybride inzet: 1536 als primair, 3072 voor re-ranking).
- Wacht als je workload extreem kostengevoelig is en alleen tekstretrieval vereist — top tekst-only modellen (bijv. OpenAI text-embedding-3-large) blijven concurrerend en soms goedkoper afhankelijk van je pipeline en contract.
Developers kunnen nu toegang krijgen tot de API's van Gemini Embedding 2 en OpenAI text-embedding-3 via CometAPI. Begin met het verkennen van de mogelijkheden van het model in de Playground en raadpleeg de API-gids voor gedetailleerde instructies. Zorg vóór toegang dat je bent ingelogd bij CometAPI en de API-sleutel hebt verkregen. CometAPI biedt een prijs die veel lager ligt dan de officiële prijs om je integratie te ondersteunen.
Klaar om te starten?→ Meld je vandaag aan voor cometapi!
Als je meer tips, gidsen en nieuws over AI wilt weten, volg ons op VK, X en Discord!