
.webp&w=3840&q=75)
GLM-5.1 markeert een kantelpunt in het AI-landschap. Terwijl Chinese AI-bedrijven de commercialisering versnellen en tegelijk frontier-capaciteiten open-sourcen, verkleint dit model de kloof met propriëtaire koplopers zoals OpenAI’s GPT-5.4, Anthropics Claude Opus 4.6 en Google’s Gemini 3.1 Pro—vooral in realistische software-engineering. Getraind op dezelfde MoE-architectuur met 744B parameters als GLM-5 maar sterk geoptimaliseerd voor agentische workflows, blinkt het uit waar de meeste LLM’s struikelen: lange, ambiguë, iteratieve taken die planning, experimentatie, debugging en zelfcorrectie vereisen over duizenden tool-aanroepen.
Nu integreert CometAPI GLM-5.1 en GLM-5, en ontwikkelaars kunnen ook andere toonaangevende westerse modellen bekijken en ze gebruiken tegen een zeer lage API-prijs (wat ook een voordeel is van CometAPI vergeleken met andere concurrenten).
Wat is GLM-5.1?
GLM-5.1 is Z.ai’s nieuwste vlaggenschiptaalmodel en de nieuwste stap van het bedrijf in softwarewerk in agentstijl met lange horizon. In Z.ai’s eigen woorden is het ontworpen voor taken die continue uitvoering vereisen in plaats van one-shot-antwoorden, en het is gepositioneerd als een model dat binnen één lange run kan plannen, uitvoeren, verfijnen en opleveren. Volgens de releasenotes van Z.ai is GLM-5.1 gebouwd met multi-turn supervised fine-tuning, reinforcement learning en een raamwerk voor procesevaluatie van kwaliteit, en verbetert het stabiliteit, consistentie en toolgebruik bij langere taken.
Die positionering is belangrijk, omdat GLM-5.1 niet in de markt wordt gezet als “gewoon nog een chatmodel”. Het richt zich op engineering-workflows waarin modellen een doel voor ogen moeten houden, tussenstappen moeten afhandelen en zich van fouten moeten herstellen zonder de draad kwijt te raken; het wordt neergezet als een model voor autonoom plannen, volgehouden uitvoering, bugfixing en strategie-iteratie—een heel ander productverhaal dan een casual assistant of een coding-copilot met korte context.
Een nuttig praktisch detail: GLM-5.1 is alleen-tekst, het wordt ondersteund in het GLM Coding Plan en kan worden gebruikt in populaire coding-agents zoals Claude Code en OpenClaw, wat het bijzonder relevant maakt voor teams die een model binnen een bestaande ontwikkelaarsworkflow willen inbedden in plaats van deze te vervangen.
Kerntechnische specificaties (geërfd van en verfijnd t.o.v. GLM-5):
- Architectuur: Mixture-of-Experts (MoE) met 744 miljard totale parameters en ongeveer 40 miljard actieve parameters per inferentie.
- Contextvenster: 203K–204.8K tokens (met ondersteuning voor tot 131K uitvoertokens).
- Belangrijkste verbeteringen: DeepSeek Sparse Attention (DSA) voor efficiënte long-contextverwerking en lagere uitrolkosten; geavanceerde asynchrone reinforcement-learninginfrastructuur (via Z.ai’s “slime”-framework) voor effectiever post-trainen.
- Beschikbaarheid: Open-weights (MIT-licentie op Hugging Face via zai-org/GLM-5.1), API-toegang via Z.ai’s platform en aggregators zoals CometAPI, en geïntegreerd in GLM Coding Plan-tools (compatibel met Claude Code / OpenClaw).
In tegenstelling tot eerdere GLM-modellen die focusten op algemene intelligentie of kort “vibe coding”, richt GLM-5.1 zich op productieniveau autonome agents. Het kan zelfstandig plannen, uitvoeren, benchmarken, debuggen en itereren aan complexe engineeringprojecten gedurende uren zonder menselijke tussenkomst—capaciteiten die het positioneren als directe concurrent van gespecialiseerde coding-agents van Anthropic en OpenAI.
De release viel samen met een ~10% API-prijsverhoging (invoertokens ~$0.54/M, uitvoer ~$4.40/M), maar blijft aanzienlijk goedkoper dan equivalenten zoals Anthropics Opus 4.6 (250–470% duurder).
Benchmarkprestaties van GLM-5.1
Z.ai positioneert GLM-5.1 als ’s werelds sterkste open-source model en een wereldwijde top-3 performer in agentisch coderen. Prestatiegegevens komen uit officiële evaluaties op SWE-Bench Pro, NL2Repo, Terminal-Bench 2.0 en aangepaste lange-horizon-scenario’s.
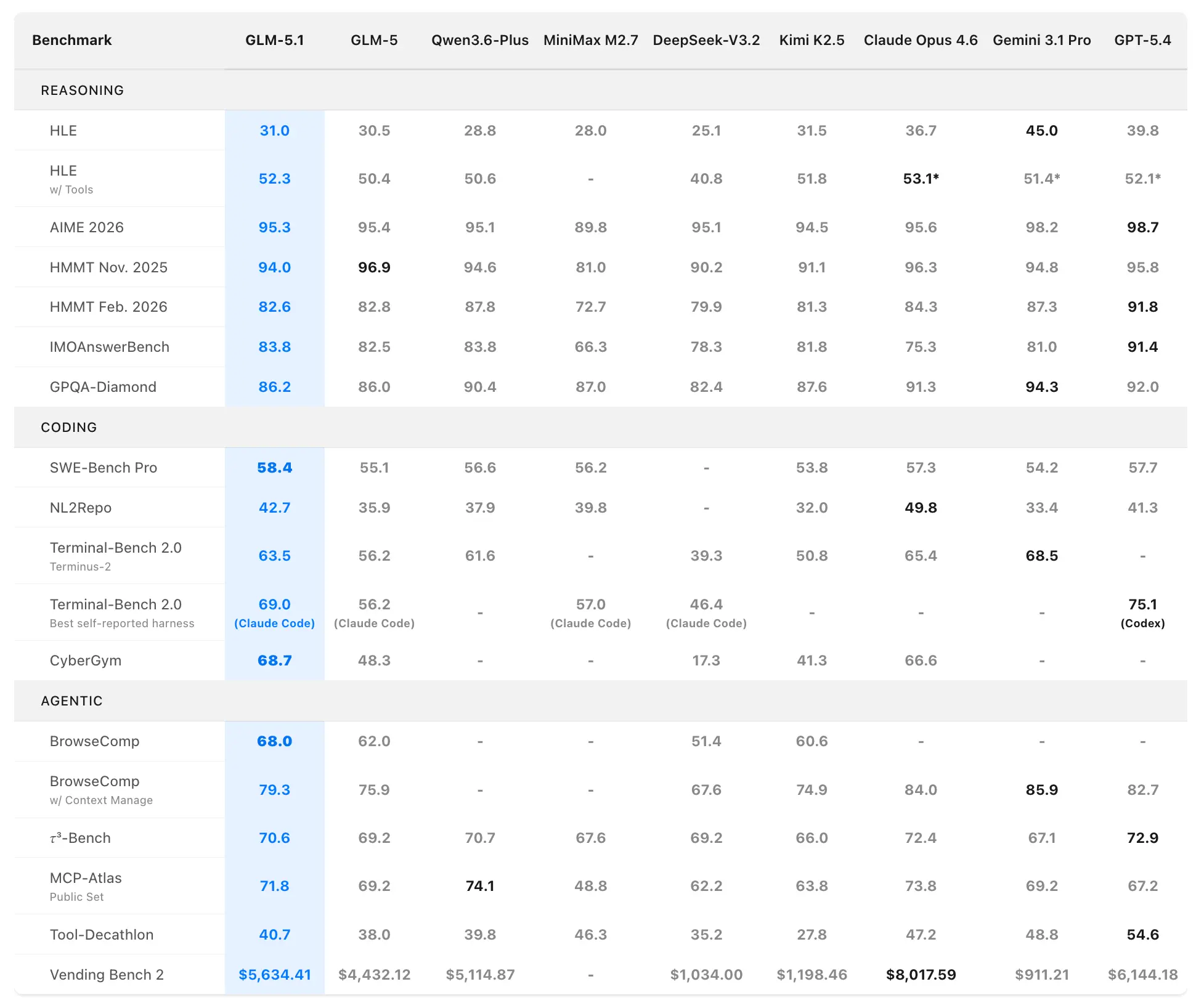
Coding- en agentische benchmarks
SWE-Bench Pro (realistische software-engineeringtaken die repositorynavigatie, codebewerking en functionele verificatie vereisen):
- GLM-5.1: 58.4 (nieuwe state-of-the-art)
- GLM-5: 55.1
- GPT-5.4: 57.7
- Claude Opus 4.6: 57.3
- Gemini 3.1 Pro: 54.2
GLM-5.1 is het eerste binnenlandse (Chinese) en open-source model dat de toppositie claimt op deze strenge benchmark, die nauw aansluit bij professionele ontwikkelaarsworkflows.
NL2Repo (van natuurlijke taal naar volledige repository-generatie):
- GLM-5.1: 42.7 (ruime voorsprong op GLM-5’s 35.9)
- Concurrerende modellen variëren 32.0–49.8 (specifieke koplopers verschillen per harness).
Terminal-Bench 2.0 (reële terminal- en systeemtaken):
- Terminus-2 harness: GLM-5.1 63.5 (vs. GLM-5 56.2)
- Best zelf gerapporteerd (Claude Code): tot 69.0.
In een afzonderlijke coding-harness-evaluatie (Claude Code-stijl) scoorde GLM-5.1 45.3—bereikend 94.6% van Claude Opus 4.6’s 47.9 en een 28% verbetering ten opzichte van GLM-5’s 35.4.
Samengestelde rangschikking: #1 open-source, #1 Chinees model, #3 wereldwijd over SWE-Bench Pro + NL2Repo + Terminal-Bench.
Lange-horizon-taakprestaties: het echte onderscheid
Standaardbenchmarks meten one-shot of kortdurende prestaties. GLM-5.1 blinkt uit in lange, autonome runs:
- VectorDBBench-optimalisatie (600+ iteraties, 6.000+ tool-aanroepen): Vanuit een Rust-skelet herontwierp GLM-5.1 iteratief indexing, compressie, routing en pruning, en behaalde 21,5k QPS (6× het eerdere 50-turn record van 3.547 QPS door Claude Opus 4.6) met behoud van ≥95% recall op SIFT-1M. Het vertoonde “trapsgewijze” progressie met structurele doorbraken elke 100–200 iteraties.
- KernelBench Level 3 (volledige ML-modeloptimalisatie, 1.000+ turns): Geometrisch gemiddelde snelheidswinst van 3.6× over 50 complexe problemen (beter dan torch.compile max-autotune’s 1.49×). GLM-5.1 bleef verbeteren lang nadat GLM-5 plateauerde; alleen Claude Opus 4.6 bleef het nipt voor met 4.2×.
- Linux-desktopwebapp-build (8+ uur, open-end): Met alleen een natuurlijke-taalprompt en geen startcode bouwde GLM-5.1 autonoom een functionele Linux-stijl desktopomgeving—compleet met taakbalk, vensters, interacties en afwerking—waar eerdere modellen slechts basale skeletten produceerden.
Deze resultaten tonen aan dat GLM-5.1 over extreem lange horizonten coherentie kan behouden, zichzelf kan evalueren, strategieën kan herzien en aan lokale optima kan ontsnappen—capaciteiten die Z.ai expliciet heeft ontworpen voor agentische systemen in de echte wereld.
Hoe verschilt GLM-5.1 van GLM-5?
GLM-5 en GLM-5.1 zijn nauw verwant, maar ze zijn niet hetzelfde gepositioneerd. GLM-5 is Z.AI’s eerdere basismodel voor Agentic Engineering. Het is ontworpen voor complexe systeemengineering en langetermijn-agenttaken, met open-weight SOTA coding- en agent-capaciteit, en codeerprestaties die in echte programmeerscenario’s dicht bij Claude Opus 4.5 liggen. Het scoort 77.8 op SWE-bench Verified en 56.2 op Terminal Bench 2.0.
GLM-5.1 daarentegen wordt neergezet als de volgende stap richting lange-horizon-taken en betrouwbaardere volgehouden uitvoering; het verbetert stabiliteit, consistentie en toolgebruik bij langere taken en is algeheel beter afgestemd op Claude Opus 4.6. Met andere woorden: GLM-5 is het eerdere engineering-centrische basismodel, terwijl GLM-5.1 het vlaggenschip is dat gericht is op taak-uithoudingsvermogen.
Er zijn ook architectuur- en trainingsverschillen in de GLM-5-generatie die de sprong helpen verklaren. GLM-5 groeide van 355B parameters (32B geactiveerd) naar 744B parameters (40B geactiveerd), verhoogde pre-trainingsdata van 23T naar 28.5T, voegde een asynchroon reinforcement-learningraamwerk toe en integreerde DeepSeek Sparse Attention om de kwaliteit op lange teksten te behouden en tegelijk de efficiëntie te verbeteren. Die details horen bij GLM-5, maar vormen de basis waarop GLM-5.1 lijkt voort te bouwen.
GLM-5.1 vs andere frontier-modellen
GLM-5.1 springt eruit als de sterkste open-source-kandidaat en biedt een overtuigende prijs/prestatie.
Vergelijkingstabel: belangrijkste coding- en agentische benchmarks (april 2026)
| Model | SWE-Bench Pro | NL2Repo | Terminal-Bench 2.0 (Terminus-2) | Coding-harness-score | Lange-horizon volgehouden? | Open-source? | Geschatte API-prijs (invoer/uitvoer per M tokens) |
|---|---|---|---|---|---|---|---|
| GLM-5.1 | 58.4 (SOTA) | 42.7 | 63.5 | 45.3 (94.6% van Opus) | Ja (600+ iteraties, 8 uur) | Ja | $0.54 / $4.40 |
| GLM-5 | 55.1 | 35.9 | 56.2 | 35.4 | Beperkt | Ja | Lager (vóór verhoging) |
| GPT-5.4 | 57.7 | — | — | — | Sterk | Nee | Hoger |
| Claude Opus 4.6 | 57.3 | — | — | 47.9 | Sterkst | Nee | ~250–470% duurder |
| Gemini 3.1 Pro | 54.2 | — | — | — | Goed | Nee | Hoger |
Oordeel: GLM-5.1 wint op open-source-toegankelijkheid, kosten en specifieke lange-horizon-codingmetrics. Het gaat de strijd aan met gesloten modellen in agentische scenario’s en democratiseert tegelijk frontier-capaciteiten.
Toepassingsscenario’s van GLM-5.1
1) Autonome software-engineering
GLM-5.1 komt het best tot zijn recht wanneer de taak lijkt op een echte engineeringsprint: de codebase lezen, de wijziging plannen, implementeren, testen, regressies fixen en blijven itereren tot het resultaat stabiel is. Z.ai’s releasenotes benadrukken expliciet autonoom plannen, volgehouden uitvoering, bugfixing en strategie-iteratie, wat dit model doelgericht maakt voor coding-agents en softwareleveringspijplijnen.
2) Langlopende agent-workflows
Als je use-case veel tool-aanroepen, lange multi-step-workflows of herhaalde zelfcorrectie omvat, past het ontwerp van GLM-5.1 uitstekend. De documentatie benadrukt tool-invocatie, gestructureerde output, MCP-integratie en tool-streamingondersteuning—allemaal nuttig wanneer een model niet alleen antwoordt, maar opereert binnen een groter systeem.
3) Kenniswerk en rapportage voor ondernemingen
GLM-5.1 is ook gepositioneerd voor kantoorproductiviteitstaken zoals PowerPoint-, Word-, PDF- en Excel-workflows. Z.ai zegt dat het de organisatie van complexe content, lay-outontwerp, gestructureerde output en visuele afwerking verbetert, waardoor het geschikt is voor rapportgeneratie, lesmateriaal, onderzoekssamenvattingen en ander documentintensief werk.
4) Front-end-prototyping en artefacten
Z.ai stelt dat GLM-5.1 goed geschikt is voor websitegeneratie, interactieve pagina’s en front-end-prototyping, met minder gesjabloneerde structuur en betere taakvoltooiingskwaliteit. Dat wijst op een goede match voor productteams die snel van briefing naar prototype willen, zeker wanneer het prototype bruikbaar moet zijn en niet alleen mooi.
5) Complexe conversatie en het opvolgen van instructies
Hoewel de headline draait om coderen, wordt GLM-5.1 ook beschreven als sterker in open Q&A, complexe instructies en multi-turn-interactie. Dat maakt het nuttig voor assistant-achtige workflows waarin het model constraints moet bijhouden, outputs herzien en context bewaren over langere gesprekken.
Conclusie: waarom GLM-5.1 ertoe doet in 2026
GLM-5.1 is niet zomaar een incrementele release—het markeert de komst van echt capabele open-source agentische AI. Door uit te blinken in de moeilijkste engineeringbenchmarks in de echte wereld en tegelijk betaalbaar en open te blijven, heeft Z.ai de lat voor de hele industrie hoger gelegd. Of je nu solo-ontwikkelaar, enterpriseteam of onderzoeker bent, GLM-5.1 biedt ongeëvenaarde autonomie voor lange-horizon-coderingstaken tegen een fractie van de kosten van propriëtaire modellen.
Klaar om het te proberen? Bekijk het CometAPI GLM-5.1-model, de Hugging Face-repo of het GLM Coding Plan voor directe toegang.