

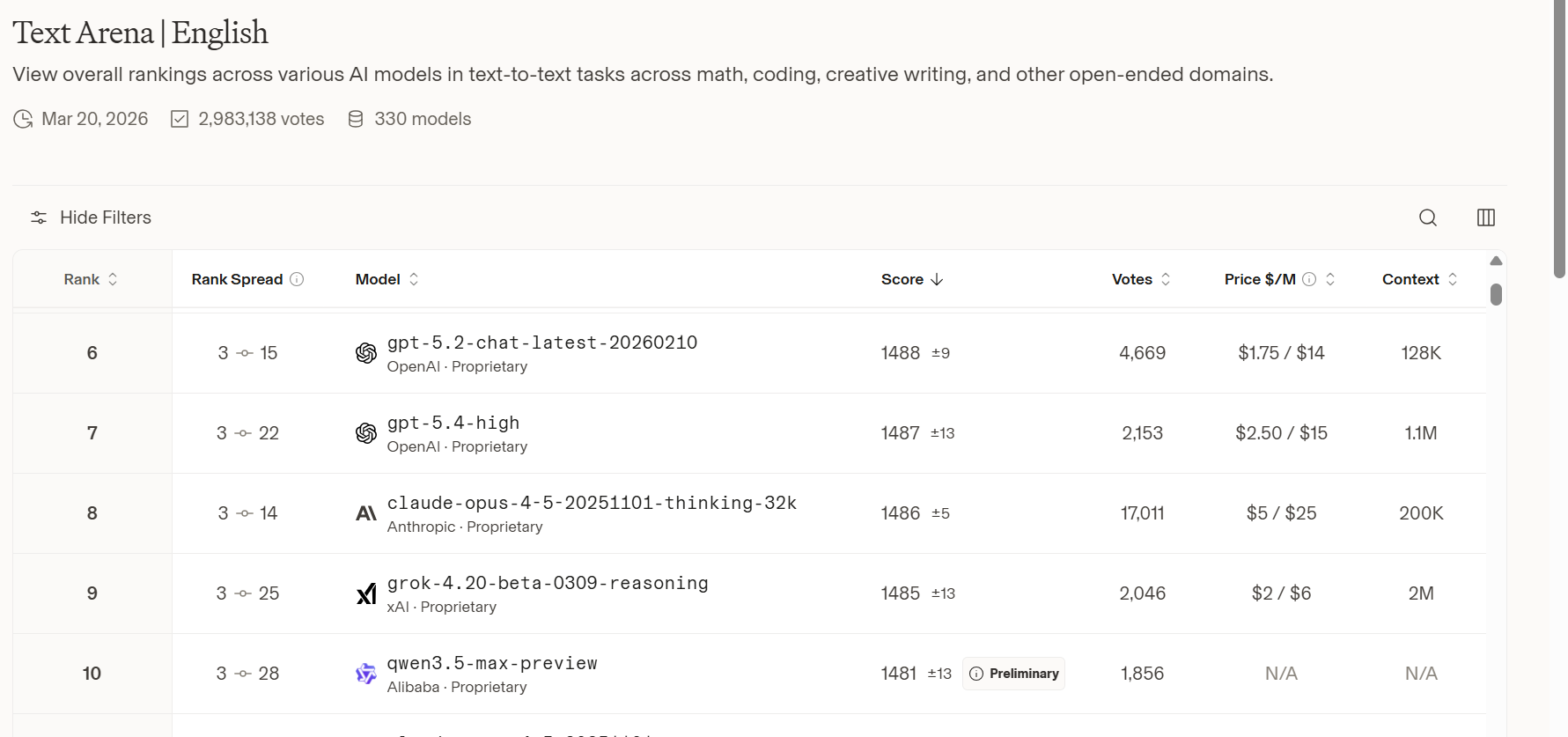
Het Qwen-team van Alibaba heeft zijn modellijn naar een nieuwe fase gebracht met de lancering van Qwen3.5-Max-Preview in februari 2026, een vlaggenschiprelease binnen de Qwen3.5-familie die het team positioneert als een native multimodaal agentmodel. In de laatste openbare snapshot van de ranglijsten werd qwen3.5-max-preview op 19 maart 2026 toegevoegd aan de Text-ranglijst van LMArena, en staat het momenteel op plaats 10 op de Engelse tekstranglijst en op plaats 15 op de algemene tekstranglijst.
Sinds oudejaarsavond van het maannieuwjaar heeft de Qwen 3.5-serie achtereenvolgens acht modellen met verschillende parameterschalen uitgebracht, variërend van 0.8B tot 397B. U kunt toegang krijgen tot Qwen 3.5 Flash, qwen3.5-plus en qwen3.5-397b-a17b.
Wat is Qwen 3.5-Max?
Qwen 3.5-Max vertegenwoordigt de vlaggenschiplaag van Alibaba’s Qwen 3.5 model series, ontworpen om rechtstreeks te concurreren met frontier-AI-modellen van OpenAI, Anthropic en Google.
In de kern is Qwen 3.5-Max:
- Een grootschalig Mixture-of-Experts (MoE)-model
- Gebouwd voor agentische AI-workflows
- Geoptimaliseerd voor geavanceerd redeneren, coderen en multimodale taken
- Ontworpen om kosten te verlagen en prestaties te verhogen
De Qwen 3.5-familie is zelf een evolutie van eerdere Qwen-modellen, maar met een strategische verschuiving naar autonome AI-agenten—systemen die zelfstandig complexe workflows kunnen uitvoeren over tools en omgevingen heen.
Qwen 3.5-Max wordt gepositioneerd als een sleutelconcurrent in het “agentische AI-tijdperk”, waarin modellen niet alleen tekst genereren maar ook acties uitvoeren in applicaties.
Qwen 3.5-Max springt naar de top van de wereldranglijsten
Een verbluffend debuut in 2026
Recente ontwikkelingen laten zien dat Qwen 3.5-Max (en de onderliggende architectuur) snel is gestegen op wereldwijde AI-ranglijsten, met sterke prestaties over meerdere benchmark-suites.
Belangrijkste punten:
qwen3.5-max-preview werd op 19 maart 2026 toegevoegd aan de LMArena-tekstranglijst, volgens het wijzigingslogboek van de ranglijst. In de live snapshot van de ranglijst wordt het model getoond met een voorlopige score van 1481±13 op de Engelse tekstranglijst, en in de bredere tekstranglijst-snapshot verschijnt het met 1464±9, opnieuw als voorlopig gemarkeerd:
- Geklasseerd onder de beste LLM’s wereldwijd (bereik Top 5–Top 6 in sommige ranglijsten)
- Behaalde topscores op benchmarks voor redeneren en coderen
- Presteerde beter dan verschillende Amerikaanse frontier-modellen in meerdere categorieën
Deze snelle opmars weerspiegelt een bredere verschuiving: Chinese AI-modellen concurreren nu aan de absolute top van de wereldranglijsten, niet alleen regionaal.
Benchmarkprestaties
Kernbenchmark-scores
| Benchmark | Qwen 3.5-Max | Positie in de sector |
|---|---|---|
| AIME (wiskunde) | 91.3 | Topniveau |
| GPQA Diamond | 88.4 | Leidend |
| LiveCodeBench v6 | 83.6 | Toonaangevend |
| MMLU-Pro | ~84–86 | Top 20% |
| BrowseComp | 78.6 | Beste in zijn klasse |
Interpretatie van de benchmarks
Sterke punten:
- Wiskundig redeneren → bijna state-of-the-art
- Coderen → topniveau
- Wetenschappelijk redeneren → leidend
Zwakke punten:
- Sommige codebenchmarks blijven nog achter bij de beste propriëtaire modellen
- Consistentie in de praktijk varieert per taak
Voor ontwikkelaars is de praktische conclusie duidelijk: Qwen3.5 wordt gepositioneerd als een model dat kan werken voor chat, coderen, agent-workflows, webonderzoek, multimodale interpretatie en taken met lange context. De officiële ecosysteemondersteuning voor Qwen Chat, Qwen API, Qwen Code en Qwen Agent maakt het voor teams makkelijker om het model in verschillende vormen te adopteren, terwijl de benchmarktabel suggereert dat het niet slechts een lokaal-marktmodel is, maar er één dat betekenisvol kan meedoen in het wereldwijde frontier-debat.
Waarom krijgt Qwen3.5-Max-Preview zoveel aandacht? Is het de moeite waard?
De aandacht komt voort uit een zeldzame combinatie van drie zaken: een vlaggenschipnaam, een sterk Arena-debuut en een bredere Qwen3.5-lanceringsnarratief dat agentische capaciteiten en lagere operationele kosten benadrukt. Alibaba introduceerde Qwen 3.5 als een model gebouwd voor het “agentische AI-tijdperk” en claimt dat het 60% goedkoper is in gebruik en acht keer beter grote werklasten aankan dan zijn voorganger, terwijl het ook visuele agentische capaciteiten toevoegt op mobiele en desktopomgevingen.
Een sterke entree, maar geen definitief oordeel
Qwen3.5-Max-Preview moet worden begrepen als een vlaggenschip-previewmodel dat een grote sparse-architectuur, native multimodaliteit, lange context, meertalige reikwijdte en competitieve benchmarkprestaties combineert. Het debuut op LMArena, de snelle mediareactie en de sterke benchmarktabel wijzen allemaal op een model dat nu al serieuze concurrentie vormt in de frontier-race. Tegelijkertijd moet het “vijfde plaats”-narratief zorgvuldig worden gelezen: de openbare tekstranglijst-snapshot toont een solide maar niet de allerhoogste positie, terwijl berichtgeving op bedrijfsniveau een gunstiger totaalbeeld voor Alibaba schetst.
Waarom deze release opvalt
Wat Qwen3.5-Max opmerkelijk maakt, is niet één getal, maar de combinatie van capaciteitsbreedte, efficiënt ontwerp en flexibiliteit in uitrol. Het is zeldzaam om een model te zien dat tegelijkertijd wordt gepositioneerd voor redeneren met lange context, multimodale interpretatie, toolgebruik, agentplanning en adoptie binnen een open-weights-ecosysteem. Als Alibaba de previewversie blijft verfijnen tot een volledige release, zou Qwen3.5-Max een van de meest bepalende modellen in de volgende golf van wereldwijde AI-concurrentie kunnen worden.
Conclusie
Qwen3.5-Max-Preview moet worden gezien als Alibaba’s nieuwste vlaggenschip-previewmodel in de Qwen3.5-lijn: een multimodaal, agentgericht systeem waarvan het bedrijf zegt dat het complexe taken efficiënter aankan dan voorheen, met nadruk in de officiële communicatie op visuele agentische capaciteiten, lagere kosten en sterkere prestaties bij grote werklasten. Het LMArena-debuut met 1464 punten laat zien dat het model direct kan concurreren met de meest zichtbare systemen in het veld, ook al verschillen de exacte ranglabels tussen live-overzichten en rapportformaten. In een markt waar perceptie, prestaties en prijs allemaal tellen, is dat voldoende om van Qwen3.5-Max een van de meest nauwlettend gevolgde modellanceringen van het seizoen te maken.
Als u als ontwikkelaar op zoek bent naar de API’s van de Qwen 3.5-serie, is CometAPI een goede keuze. De prijsstrategie en de diversiteit aan integratiepartners zorgen ervoor dat u geen enkel AI-model misloopt.