

Alibabas Wan2.7-Image, lansert 1. april 2026, markerer et stort sprang innen AI-basert visuell generering. Denne enhetlige modellen integrerer tekst-til-bilde-generering, interaktiv redigering, komposisjon med flere bilder og semantisk forståelse i én arkitektur. I motsetning til tradisjonelle, separate rørledninger for generering og redigering eliminerer den inkonsistenser som «standardiserte AI-ansikter», forvrengt tekst og uforutsigbare farger.
Skapere, designere, markedsførere og virksomheter kan nå oppnå fotorealistiske, instruksjonsnøyaktige resultater med færre iterasjoner. Modellen støtter opptil 12 sekvensielle bilder, 9 referansefusjoner, flerspråklig tekstgjengivelse på 12 språk (opptil 3 000 tokens) og kontroll på pikselnivå.
Hva er Wan2.7-Image?
Wan2.7-Image er Tongyi Lab hos Alibaba sin flaggskipsenhetlige bildemodell i Wan-serien (Tongyi Wanxiang). Den håndterer ende-til-ende visuelle arbeidsflyter: tekst-til-bilde-generering, bilde-til-bilde-transformasjon, kommando-basert redigering og interaktive finjusteringer på pikselnivå—alt i ett delt latent rom.
Lansert 1. april 2026 bygger den på tidligere Wan 2.x-videomodeller (som toppet VBench-benchmarkene) ved å flytte fokuset til bildepresisjon. Den tar direkte tak i «estetisk fatigue» fra repeterte ansikter, ustabile farger og svak oppfyllelse av prompt, som var vanlig i tidligere AI-verktøy. Modellfamilien inkluderer to navn som betyr mest for brukerne: wan2.7-image og wan2.7-image-pro. Standardversjonen er tunet for raskere genereringshastighet, mens Pro-versjonen er rettet mot profesjonell output, med 4K-støtte.
Nøkkelforskjell: enhetlig arkitektur. Tradisjonelle modeller bruker frakoblede stadier (encoder → diffusion → decoder) og krever separat inpainting for redigering. Wan2.7-Image kartlegger semantikk direkte i et delt rom, noe som muliggjør reell forståelse fremfor pikselmønstermatching.
Hvorfor Wan2.7-Image betyr noe (bransjekontekst)
Tradisjonelle AI-bildeverktøy lider av:
| Problem | Forklaring |
|---|---|
| Fragmentert arbeidsflyt | Separate verktøy for generering, redigering, inpainting |
| «AI-ansiktssyndrom» | Repeterte, urealistiske menneskeansikter |
| Svak instruksjonsoppfyllelse | Prompter følges ikke nøyaktig |
| Dårlig tekstgjengivelse | Forvrengt eller uleselig tekst |
| Inkonsistent flerbilde-output | Karakterer endres på tvers av rammer |
Wan2.7-Image adresserer disse begrensningene direkte med en enhetlig arkitektur + semantisk forståelseslag.
5 kjernefunksjoner i Wan2.7-Image
1. Skjelettnivå avatar-tilpasning for virkelig unike ansikter
Wan2.7-Image utmerker seg ved «et unikt ansikt for hver person». Den støtter finmasket kontroll over benstruktur, øyeform (mandelformede, føniksformede, dyptliggende, hovne, smilende), ansiktskonturer og subtile detaljer. Dette eliminerer problemet med «standardiserte AI-ansikter» som plagde tidligere modeller.

Eksempelprompt: «Fotorealistisk portrett av en 28 år gammel østasiatisk kvinne, oval ansiktsform, mandelformede øyne, subtilt smil, detaljert hudtekstur, naturlig lyssetting.» Resultatene viser livaktig variasjon, ideelt for virtuelle influensere, spill-NPC-er eller personlig merkevarebygging.
2. Presis kontroll av fargepalett
En av de mest praktiske funksjonene er den nye kontrollen for fargepalett. Ifølge Alibaba kan brukere angi spesifikke fargekoder og -forhold for å reprodusere kunstneriske stiler eller låse inn merkevarefarger. API-dokumentasjonen formaliserer dette med parameteren color_palette som aksepterer 3 til 10 farger, med 8 anbefalt. For merkevareteam er dette en av de tydeligste virksomhetsrettede funksjonene i lanseringen. Ikke mer tilfeldige fargeskift—perfekt konsistens på tvers av kampanjer.
Offisielt sitat: «Si farvel til tilfeldig fargegenerering. Oppnå presise fargeforhold og realiser din kreative visjon.» — Tongyi Wanxiang.
3. Avansert flerspråklig tekstgjengivelse (12 språk, 3 000 tokens)
Gjengi ultralang tekst, tabeller, formler, diagrammer og infografikk med trykkeklar skarphet (tilsvarende A4). Støtter kinesisk, engelsk, japansk, koreansk og 8 flere språk. Vitenskapelige artikler, plakater, produktetiketter og flerspråklige bannere oppnår tilnærmet perfekt lesbarhet—og adresserer en historisk svakhet i AI.
4. Pikselpresis interaktiv redigering med markeringsverktøy
Bruk avgrensningsbokser (editRegions) eller markeringsverktøy for målrettede endringer. Last opp opptil 9 referanser og gi instruksjoner som «endre bakgrunn til strandsolnedgang mens ansikt, positur og klær bevares». Presisjon på pikselnivå sikrer identitetsbevaring.
5. Komposisjonell generering med flere bilder (opptil 12 sekvensielle bilder)
Modellen er designet for mer enn enkel prompt-generering. Ifølge Alibaba kan brukere arbeide med opptil ni referansebilder og generere opptil 12 bilder samtidig, noe som er ideelt for sammenhengende storyboard, arkitektur og e-handelssserier. «Klikk-for-å-redigere»-flyten lar brukere velge spesifikke områder og gjøre endringer med pikselnivåpresisjon, og API-dokumentasjonen legger til interaktiv presis redigering via en parameter for avgrensningsboks for lokale endringer.
Hvordan fungerer Wan2.7-Image? (teknisk dypdykk)
Alibaba beskriver Wan2.7-Image som et rammeverk som bygger bro mellom språk og visuelle uttrykk ved å trenes på store, mangfoldige datasett. Enkelt sagt lærer ikke modellen bare å «tegne» bilder; den lærer også hvordan prompter kartlegges til visuell struktur, komposisjon, lyssetting og tekstanplassering. Det er det som lar modellen tolke brukerintensjon mer nøyaktig enn et grunnleggende tekst-til-bilde-system.
API-en viser også at modellen er bygget for multimodal input. I praksis sendes forespørsler gjennom en enkeltrunde-meldingsstruktur, og innholdet kan inkludere både tekst- og bildeelementer. For redigering kan brukere sende flere bilder pluss instruksjoner som «move», «replace» eller «blend» for å styre resultatet. Dette er et tydelig tegn på at Wan2.7 er designet som et prompt- og referansesystem snarere enn en enkel one-shot-generator.
Dokumentene eksponerer også en innstilling for tenkemodus. Den er aktivert som standard og kan forbedre outputkvalitet, men Alibaba påpeker at den øker genereringstiden. Det er et nyttig hint om modellens arbeidsflyt: høyere kvalitet kan kreve mer intern inferenstid, spesielt når forespørselen er teksttung eller visuelt kompleks.
Wan2.7-Image benytter et enhetlig genererings- og redigeringsrammeverk i et delt latent rom:
- Inputfase: Tekstprompt (opptil 3 000 tokens) + valgfrie referansebilder (opptil 9).
- Semantisk parsing og tenkemodus (forsterket i Pro): Kjedereasoning analyserer komposisjon, romlige relasjoner, lyssetting og logikk før pikselgenerering.
- Kartlegging til delt latent rom: Semantikk kartlegges direkte til visuelle trekk—ingen frakoblede encoder/decoder-gap.
- Forent inferens: Generering eller redigering skjer i én optimalisert flyt. Redigeringsområder bruker avgrensningsbokser; fargepaletter håndhever forhold.
- Output: Høyoppløselige bilder (768–2048×2048 standard; 4K i Pro), med valg for JPG/PNG/WEBP, seeds for reproduserbarhet og sikkerhetssjekker.
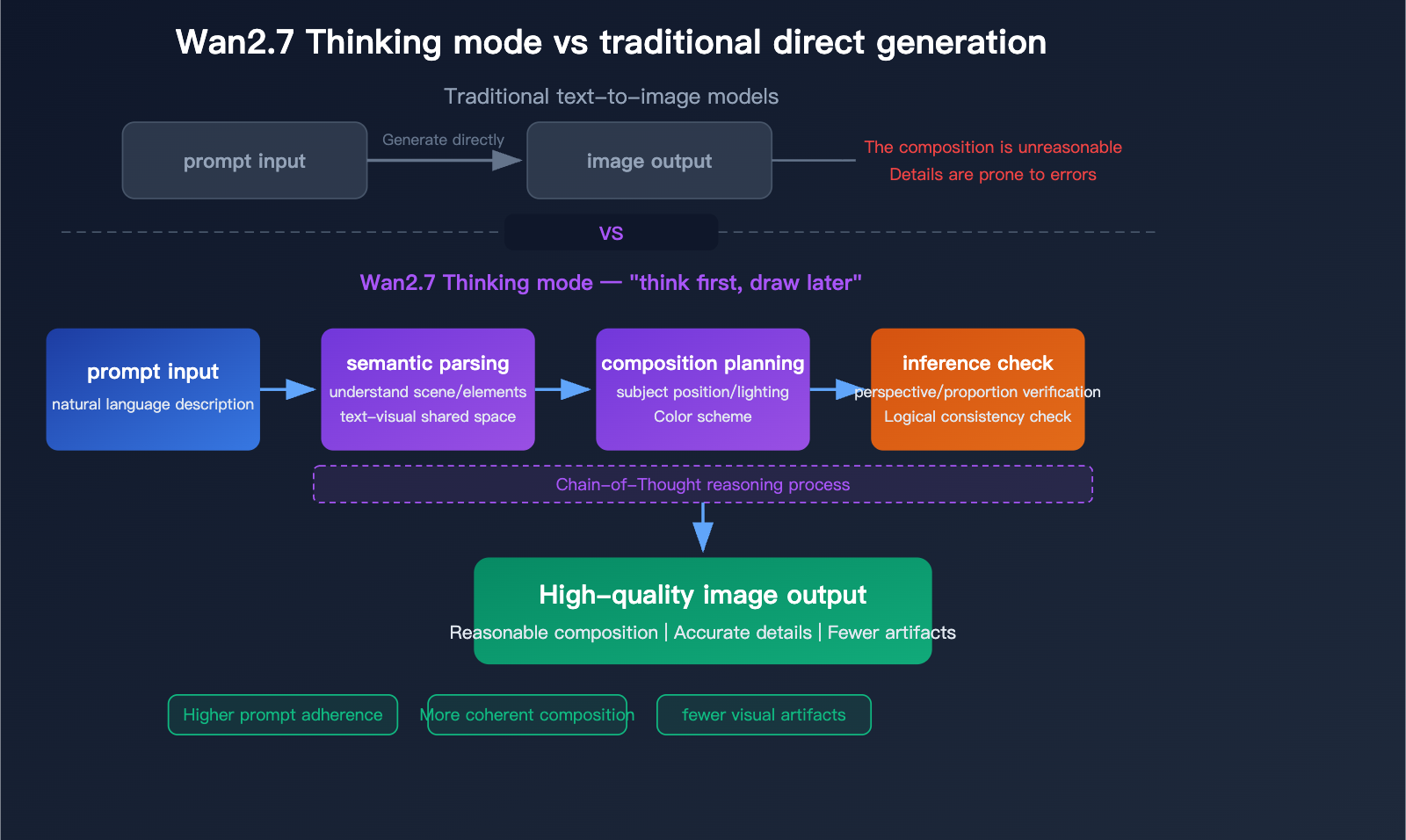
Dybdeanalyse av Wan2.7-Image-Pro: En ny målestokk for AI-bildefremstilling med 4K-kvalitet, resonneringsmodus og 12-språklig tekstgjengivelse - Apiyi.com Blog
Flytskjemaet for tenkemodus (Pro) viser semantisk parsing → komposisjonsplanlegging → inferenssjekk, som gir færre artefakter og høyere etterlevelse av prompt enn direkte generering.
Trening på mangfoldige datasett muliggjør dyp forståelse av intensjon, lyssetting og layout. Langkontekstlæring (referert i arXiv-studier) driver utvidet teksthåndtering.
Wan2.7-Image vs Wan2.7-Image-Pro: viktige forskjeller
Begge versjoner lanseres samtidig, men Pro retter seg mot profesjonelle behov.
| Funksjon | Wan2.7-Image (Standard) | Wan2.7-Image-Pro | Best for |
|---|---|---|---|
| Maks oppløsning | 2048×2048 | 4096×4096 (4K) | Trykk/produksjon (Pro) |
| Tenkemodus | Tilgjengelig (raskere standard) | Forbedret/standard med dypere resonnement | Komplekse scener (Pro) |
| Komposisjonsstabilitet | Sterk | Overlegen semantisk forståelse | Kommersielle prosjekter (Pro) |
| Hastighet vs kvalitet | Raskere iterasjon | Høyere fidelitet, noe lengre tid | Prototyping (Standard) |
| Bruksområde | Generelle skapere, sosiale medier | Enterprise-design, akademia/trykk | Skalerbarhet vs presisjon |
Standard passer for rask prototyping; Pro leverer trykkklar 4K med overlegen konsistens.
Slik bruker du Wan2.7-Image (trinn for trinn)
1. Tilgang til plattform
Tilgjengelig via:
- Alibaba Cloud (BaiLian platform)
- Wanxiang offisielle verktøy
- CometAPI
2. Velg arbeidsflytmodus
Modus A: tekst-til-bilde
Eksempelprompt:
A cinematic portrait of a cyberpunk woman, neon lighting, ultra-detailed, 8K
Modus B: bilderedigering
- Last opp bilde
- Velg område
- Skriv instruksjon
Eksempel:
Replace background with a futuristic city
Modus C: komposisjon med flere bilder
- Last opp flere referanser
- Definer komposisjonsregler
3. Finjuster parametere
- Fargepalett
- Stilkonsistens
- Tekstgjengivelse
4. Eksporter resultat
- Høyoppløselige bilder
- Kommersielt klare ressurser
Ytelsestester og sammenligning med konkurrenter
I blinde menneskelige preferansetester overgår Wan2.7-Image GPT-Image-1.5 i kvalitet for tekst-til-bilde og matcher eller overgår Nano Banana Pro i tekstgjengivelse, fotorealisme og verdensforståelse.
Sammenligningstabell:
| Modell | Tekstgjengivelse | Etterlevelse av instruksjoner | Avatar-tilpasning | Flerbilde-referanser | Forent gen/redigering | Oppløsning | Åpen kildekode/API |
|---|---|---|---|---|---|---|---|
| Wan2.7-Image | Utmerket (12 språk) | Overlegen (tenkemodus) | Skjelettnivå | 9 | Ja | 2K–4K | Ja/API |
| Midjourney V8 | God | Moderat | Sterk kunstnerisk | Begrenset | Nei | Høy | Kun Discord |
| FLUX | God | Sterk (enkle) | God | Begrenset | Nei | Høy | Ja |
| DALL-E 3 | Moderat | God | Moderat | Nei | Nei | 2K | API |
| Nano Banana Pro | Sterk | Sterk redigering | God | Sterk | Delvis | Høy | Lukket |
Wan2.7-Image leder i enhetlig arbeidsflyt, flerspråklig tekst og presis kontroll—særlig verdifullt for ikke-engelske markeder og profesjonelle pipelines.
CometAPI er en alt-i-ett-aggregasjonsplattform for store modell-API-er, som tilbyr sømløs integrasjon og administrasjon av API-tjenester. Den støtter flere bildegenererings-API-er, slik som GPT-image-1.5, Nano Banana series, Midjourney og Qwen Image Series osv., til en lavere pris enn offisielle nettsteder.
Hvem bør bruke Wan2.7-Image
Wan2.7-Image er spesielt relevant for team som trenger hastighet og fleksibilitet fremfor bare enkeltstående kunstgenerering. Det inkluderer performance-markedsførere, produktdesignere, e-handelsstudioer, sosiale innholdsteam og byråer som produserer mange varianter fra samme brief. Modellens støtte for flerbilde-input, generering av flere utganger og instruksjonsbasert redigering gjør den særlig attraktiv for arbeidsflyter der konsistens, hastighet og prompt-kontroll er viktige.
Virkelige bruksområder
- Gaming/underholdning: Generer 100 unike NPC-er på minutter.
- Markedsføring/e-handel: Merkekonsistente karuseller med eksakte fargepaletter.
- Utdanning/akademia: Trykkeklare plakater med formler og tabeller.
- Designbyråer: Storyboards og kunderevisjoner via interaktiv redigering.
Produktivitetsgevinster kommer fra færre iterasjoner og sømløs integrering av referanser.
Konklusjon:
Alibaba Wan2.7-Image redefinerer kreativitet med AI ved å forene generering, redigering og forståelse. Dets 5 kjernefunksjoner, delte latente rom og Pro-forbedringer leverer profesjonelle resultater som konkurrenter fortsatt sliter med å matche. Enten du prototyper innhold for sosiale medier eller produserer trykkeklare akademiske visualer, tilbyr den enestående presisjon og effektivitet.
Start i dag på wan.video eller via API i CometAPI. For utviklere og virksomheter gjør kombinasjonen av kraft, tilgjengelighet og databekreftet overlegenhet Wan2.7-Image til den klare lederen innen enhetlige AI-bildemodeller for 2026 og videre.