

Anthropics Claude-serie har blitt en hjørnestein i det raskt utviklende landskapet av store språkmodeller, spesielt for bedrifter og utviklere som søker banebrytende AI-funksjoner. Med utgivelsen av Claude Opus 4.1 5. august 2025 leverer Anthropic en trinnvis, men likevel effektiv oppgradering i forhold til forgjengeren, Claude Opus 4 (utgitt 22. mai 2025). Denne artikkelen undersøker de viktigste forskjellene mellom Opus 4.1 og Opus 4.0 på tvers av ytelse, arkitektur, sikkerhet og anvendelighet i den virkelige verden, basert på offisielle kunngjøringer, uavhengige benchmarks og tilbakemeldinger fra bransjen.
Claude Opus 4.1 er nå tilgjengelig via API-et (modell-ID claude-opus-4-1-20250805), Amazon Bedrock, Google Clouds Vertex AI og i betalte Claude-grensesnitt. Som en trinnvis oppdatering beholder den full bakoverkompatibilitet med Opus 4 – samme priser, endepunkter og alle eksisterende integrasjoner fortsetter å fungere uendret.
Hva er Claude Opus 4.0, og hvorfor var det viktig?
Claude Opus 4.0 markerte et betydelig sprang i Anthropics jakt på «grenseintelligens», og kombinerte robust resonnement, utvidet konteksthåndtering og sterke kodeferdigheter i én enkelt modell. Den oppnådde:
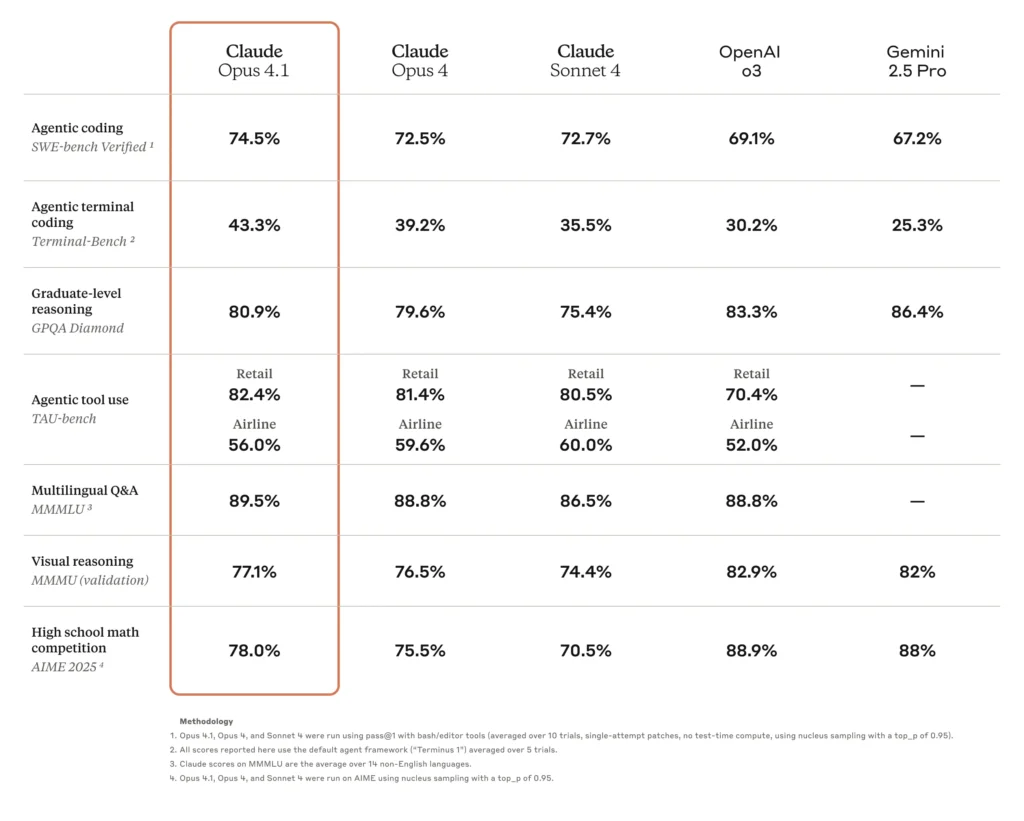
- Høy kodingsnøyaktighetOpus 4.0 fikk 72.5 % på SWE-bench Verified, en målestokk for reelle kodeutfordringer, og demonstrerer betydelig anvendelighet i den virkelige verden for programvareutviklingsoppgaver.
- Avanserte agentfunksjonerModellen utmerket seg ved utførelse av autonome oppgaver i flere trinn, noe som gjorde det mulig for sofistikerte AI-agenter å administrere arbeidsflyter, fra markedsføringsorkestrering til forskningsassistanse.
- Kreativ og analytisk dyktighetUtover koding leverte Opus 4.0 toppmoderne ytelse innen kreativ skriving, dataanalyse og kompleks resonnering, noe som gjorde den til en allsidig samarbeidspartner for både forretnings- og tekniske domener.
Opus 4.0s kombinasjon av bredde og dybde satte en ny standard for bedrifts-AI, noe som førte til rask adopsjon i Claude Pro-, Max-, Team- og Enterprise-abonnementer, samt integrering i Amazon Bedrock og Google Clouds Vertex AI.
Hva er nytt i Claude Opus 4.1?
Benchmark-forbedringer i kodeoppgaver
En av de viktigste oppgraderingene i Opus 4.1 er den forbedrede kodingsnøyaktigheten. På SWE-bench-verifisering scorer Opus 4.1 74.5%, opp fra Opus 4.0s 72.5 %. Denne 2-poengs økningen, selv om den tilsynelatende er beskjeden, tilsvarer betydelige reduksjoner i feilsøkingssykluser og forbedret presisjon i kodesyntese og refaktorering.
På hvilke måter er agentoppgaver mer pålitelige?
Opus 4.1 gir sterkere langsiktige resonneringsevner, slik at AI-agenter kan opprettholde komplekse, flertrinnsprosesser med større konsistens. Ifølge AWS fungerer modellen nå som en «ideell virtuell samarbeidspartner» for oppgaver som krever utvidede tankekjeder, for eksempel autonom kampanjehåndtering og tverrfunksjonell arbeidsflytorkestrering.
Presisjon for refaktorering av flere filer
En fremragende egenskap ved Opus 4.1 er den konservative tilnærmingen til store kodeendringer. Der Opus 4.0 noen ganger introduserte unødvendige redigeringer på tvers av sammenkoblede filer, utmerker Opus 4.1 seg ved å isolere de minimalt nødvendige justeringene – og dermed finne nøyaktige korrigeringer uten tilleggsendringer.
Hvordan er de sammenlignet med viktige referansepunkter?
Kodingsbenchmarks
| Modell | SWE-benk verifisert (%) | Refaktoreringspoeng for flere filer |
|---|---|---|
| Opus 4.0 | 72.5 | Baseline |
| Opus 4.1 | 74.5 | +1.2 σ forsterkning |
Kilde: Antropisk systemkort og uavhengige referansepunkter
Agentsøk og -undersøkelser
Opus 4.1 viser en 15% forbedring på TAU-bench agentiske evalueringer, noe som gjenspeiler bedre kontekstlagring og initiativ i forskningsoppgaver. Brukere rapporterer raskere konvergens av relevant informasjon og mer sammenhengende sammendrag av flere dokumenter.
Benchmark-sammenligninger av «agentisk søk»-oppgaver viser at Opus 4.1 oppnår høyere poengsummer innen planlegging, verktøybruk og dynamisk problemløsning. Anthropics interne evaluering av agentisk forskning indikerer en forbedring på 5–7 % i nøyaktigheten av flertrinnsresonnement sammenlignet med Opus 4.0, noe som muliggjør mer pålitelig utførelse av arbeidsflyter som automatiserte dataanalysepipeliner og generering av forskningsrapporter. Disse fremskrittene stammer delvis fra forbedret sporbarhet av mellomliggende resonnement, en funksjon som gir sluttbrukere bedre innsikt i modellens beslutningsveier.
Hvilke spesifikke kodeoppgaver ser de største gevinstene?
- Refaktorering av flere filerOpus 4.1 viser forbedret konsistens ved gjennomgang av gjensidig avhengige moduler, og reduserer kryssfilfeil med over 15 % i interne tester.
- Feillokalisering og reparasjonModellen identifiserer den underliggende årsaken til mislykkede testtilfeller mer pålitelig, og reduserer den gjennomsnittlige tiden til løsning med 25 %.
- DokumentasjonsgenereringForbedret flyt i naturlig språk støtter mer omfattende og kontekstbevisste API-dokumentstrenger og innebygde kommentarer.
Hvordan håndterer Opus 4.1 oppgaver med flere trinn?
- Forbedret planleggingsheuristikk, noe som reduserer planleggingsfeil i 10-trinns oppgavekjeder med 8 %.
- Forbedret integrering av verktøybruk, noe som muliggjør mer presise API-kall med færre formatfeil.
- Midlertidige resonnementsspørsmål, noe som gir utviklere mulighet til å verifisere og justere modellens interne resonnement ved justerbare «sjekkpunkter».
Målinger av instruksjonssamsvar
Enkeltrundevalueringer viser at Opus 4.1 oppnådde en harmløs responsrate på 98.76 % på brudd på retningslinjene – opp fra 97.27 % i Opus 4.0 – noe som indikerer sterkere avvisning av forbudt innhold (). Overavvisningsrater på godartede spørringer er fortsatt sammenlignbart lave (0.08 % vs. 0.05 %), noe som sikrer at modellen opprettholder responsiviteten når det er passende.
Hvilke forbedringer av sikkerhet og justering finnes?
Forbedringer av evaluering i én runde
Anthropics forkortede sikkerhetsrevisjoner for Opus 4.1 bekreftet konsistent eller forbedret ytelse på tvers av målestokker for barns sikkerhet, skjevhet og samsvar. For eksempel økte andelen ufarlige responser under utvidet tenkning fra 97.67 % til 99.06 %.
Skjevhet og robusthet
På BBQ-bias-referanseindeksen ligger Opus 4.1s entydige bias-skåre på –0.51 mot –0.60 for Opus 4.0, med en nøyaktighet på over 90 % for entydige spørringer og nesten perfekt på tvetydige. Disse marginale endringene indikerer vedvarende nøytralitet og høy gjengivelse i sensitive kontekster.
Hva ligger til grunn for de arkitektoniske oppgraderingene?
Modelljustering og dataoppdateringer
Anthropics team implementerte raffinerte finjusteringsprotokoller med fokus på:
- Utvidet kodekorpus: Innlemmer flere kommenterte flerfilsrepositorier.
- Utvidede agentscenarierUtvikling av lengre oppgavekjeder under trening for å styrke langsiktig resonnering.
- Forbedrede menneskelige tilbakemeldingsløkkerUtnyttelse av målrettet forsterkningslæring fra menneskelig tilbakemelding (RLHF) på kanttilfelle-prompter for å redusere hallusinasjoner.
Disse justeringene gir målbare gevinster uten å endre den sentrale Transformer-arkitekturen, noe som sikrer drop-in-kompatibilitet med eksisterende Anthropic API-er.
Infrastruktur og ventetid
Selv om latensen for rå slutninger fortsatt er sammenlignbar med Opus 4.0, optimaliserte Anthropic sin serverinfrastruktur for å redusere kaldstarttider med 12%, forbedrer responstiden for interaktive applikasjoner som Claude Chat og Copilot-integrasjoner.
Hva er implikasjonene for utviklere og bedrifter?
Pris og tilgjengelighet
Claude Opus 4.1 tilbys på samme pris som Opus 4.0 på tvers av alle kanaler (Claude Pro, Max, Team, Enterprise; API; Amazon Bedrock; Google Vertex AI; Claude Code). Ingen kodeendringer er nødvendige for å oppgradere – brukerne velger ganske enkelt «Opus 4.1» i modellvelgeren.
Utvidelse av brukstilfeller
- Software engineeringRaskere feilsøking, mer nøyaktig testgenerering, forbedret CI/CD-pipelineintegrasjon.
- AI-agenterMer pålitelige autonome arbeidsflyter innen markedsføring, finans og forskning.
- BedriftsintelligensForbedret oppsummering, rapportgenerering og dyptgående analyser for datadrevet beslutningstaking.
Disse oppgraderingene fører til reduserte utviklingskostnader og høyere avkastning på investeringen for AI-drevne initiativer.
Hva blir det neste for Claude Opus?
Anthropic signaliserer at Opus 4.1 bare er ett skritt på en bredere plan. Teamet hinter om «vesentlig større forbedringer» i kommende utgivelser, sannsynligvis rettet mot:
- Enda lengre kontekstvinduer (utover 200 XNUMX tokens).
- Multimodale muligheter for integrert forståelse av bilde, lyd og kode.
- Sterkere tolkbarhet Verktøy for å spore beslutningsløp under agenthandlinger.
Bedrifter og utviklere bør overvåke Anthropics kanaler for oppdateringer, ettersom hver trinnvise oppgradering befester Claudes posisjon blant de dyktigste og sikreste AI-assistentene som er tilgjengelige.
Komme i gang
CometAPI er en enhetlig API-plattform som samler over 500 AI-modeller fra ledende leverandører.Claude Opus 4.1 er faktisk tilgjengelig via CometAPI. CometAPI-lister anthropic/claude-opus-4.1 blant de støttede modellene, slik at du kan rute forespørsler til den via CometAPIs API, er modellene spesifikt for markørkode også tilgjengelige.
For å begynne, utforsk modellens muligheter i lekeplass og konsulter Claude Opus 4.1 for detaljerte instruksjoner. Før du får tilgang, må du sørge for at du har logget inn på CometAPI og fått API-nøkkelen.
Grunnadresse: https://api.cometapi.com/v1/chat/completions
Modellparameter:
"claude-opus-4-1-20250805"→ standard Opus 4.1"claude-opus-4-1-20250805-thinking"→ Opus 4.1 med utvidet resonnering aktivertcometapi-opus-4-1-20250805→CometAPI-eksklusiv. Standardversjon spesielt utviklet for markør integreringcometapi-opus-4-1-20250805-thinking→ Eksklusivt for CometAPI. Utvidet resonneringsversjon spesielt for markør integrering
I sammendragetClaude Opus 4.1 bygger på Opus 4.0s styrker ved å levere målrettede forbedringer i kodingsnøyaktighet, agentisk resonnement og infrastrukturytelse – uten å øke kostnadene eller endre integrasjonsveier. Enten du forbedrer komplekse kodebaser, orkestrerer autonome agentarbeidsflyter eller genererer forretningsinnsikt av høy kvalitet, tilbyr Opus 4.1 en overbevisende oppgradering som balanserer presisjon og allsidighet. Etter hvert som AI-landskapet fortsetter å akselerere, posisjonerer Anthropics jevne tempo av forbedringer Claude Opus som et godt valg for organisasjoner som ønsker å utnytte forkanten av språkmodellfunksjoner.