

Anthropics nye Claude 4-familie – Claude Opus 4 og Claude Sonnet 4 – ble annonsert i mai 2025 som neste generasjons AI-assistenter optimalisert for avansert resonnering og koding. Opus 4 beskrives som Anthropics «den kraftigste modellen hittil», og utmerker seg i komplekse kodings- og resonneringsoppgaver med flere trinn. Sonnet 4 er en kraftig oppgradering til den tidligere Sonnet 3.7, og tilbyr sterk generell resonnering, presis instruksjonsfølging og konkurransedyktige kodeferdigheter.
Nedenfor sammenligner vi disse modellene på tvers av viktige tekniske dimensjoner som er viktige for utviklere: resonnement og kodingsytelse, latens og effektivitet, kodegenereringskvalitet, gjennomsiktighet, verktøybruk, integrasjoner, kostnad/ytelse, sikkerhet og brukstilfeller for distribusjon. Analysen bygger på Anthropics kunngjøringer og dokumentasjon, uavhengige benchmarks og bransjerapporter for å gi et omfattende og oppdatert bilde.
Hva er Claude Opus 4 og Claude Sonnet 4?
Claude Opus 4 og Claude Sonnet 4 er de nyeste medlemmene av Anthropics Claude 4-familie, utformet som hybride resonneringsspråkmodeller som blander intern tankekjede med dynamisk verktøybruk. Begge modellene har to viktige innovasjoner:
- TenkesammendragAutomatisk genererte oversikter over modellens resonnementstrinn, som forbedrer åpenheten og hjelper utviklere med å forstå beslutningsveier.
- Utvidet tenkning (beta): En modus som balanserer intern resonnement med eksterne verktøykall – som nettsøk eller kodekjøring – for å optimalisere oppgaveytelsen over lengre, komplekse arbeidsflyter.
Opprinnelse og posisjonering
- Claude Opus 4 er posisjonert som Anthropics flaggskip innen resonneringsmotor. Den opprettholder autonom oppgaveutførelse i opptil syv timer og overgår konkurrerende store modeller – inkludert Googles Gemini 2.5 Pro, OpenAIs o3-resonneringsmodell og GPT-4.1 – på benchmark-koding og verktøybruksoppgaver.
- Claude Sonnet 4 etterfølger Claude Sonnet 3.7 som en kostnadseffektiv arbeidshest optimalisert for generell bruk. Den tilbyr overlegen instruksjonsoppfølging, verktøyvalg og feilretting i forhold til forgjengeren, samtidig som den opprettholder høy gjennomstrømning for kundevendte agenter og AI-arbeidsflyter.
Tilgjengelighet og priser
- API- og skyplattformerBegge modellene er tilgjengelige via Anthropic API samt gjennom store skybaserte markedsplasser – Amazon Bedrock, Google Cloud Vertex AI, Databricks, Snowflake Cortex AI og GitHub Copilot.
- Gratis vs. betalte nivåerGratisbrukere har tilgang til Claude Sonnet 4, mens Claude Opus 4 og utvidede funksjoner krever et betalt abonnement.
Hvordan er kjernefunksjonene til Opus 4 og Sonnet 4 sammenlignet?
Selv om begge modellene deler underliggende arkitektur og sikkerhetsgrunnlag, er justerings- og ytelsesrammene deres skreddersydd for ulike brukstilfeller.
Kodings- og utviklingsarbeidsflyter
Claude Opus 4 setter en ny standard for AI-drevet programvareutvikling, og oppnår toppkarakterer på bransjetester som SWE-bench (72.5 %) og Terminal-bench (43.2 %), og opprettholder autonom kodegenerering for dagelange refaktoreringspipelines. Støtten for 32 K+ token-kontekster og bakgrunnsutførelse av oppgaver («Claude Code») lar utviklere avlaste komplekse redigeringer med flere filer og iterativ feilsøking til modellen. Omvendt er Claude Sonnet 4 – selv om den ikke matcher Opus 4s absolutte toppytelse – fortsatt 20 % mer nøyaktig enn Sonnet 3.7 i gjennomsnitt i utviklerorienterte arbeidsflyter og utmerker seg innen rask prototyping, kodegjennomgang og interaktiv chatbasert assistanse.
Resonnement, hukommelse og planlegging
Begge modellene introduserer utvidede minnevinduer som beholder kontekst over økter på opptil syv timer, et gjennombrudd for applikasjoner som krever vedvarende dialoger eller langvarige agentprosesser. Deres «tenkesammendrag»-funksjoner gir konsise oversikter over interne tankekjeder, noe som øker åpenheten for komplekse beslutningsbaner. Opus 4s sammendrag er spesielt detaljerte – egnet for analyser på forskningsnivå – mens Sonnet 4s mer slanke sammendrag prioriterer klarhet og hastighet for å betjene kundesupportboter og chatgrensesnitt med høyt volum.
Sikkerhet og etiske hensyn
Gitt styrken til Claude Opus 4 – demonstrert av dens evne til å veilede flertrinnsoppgaver som kan utgjøre biosikkerhetsrisikoer – anvendte Anthropic sin Responsible Scaling Policy på AI Safety Level 3 (ASL-3), og håndhevet anti-jailbreak-klassifiseringer, herding av cybersikkerhet og et eksternt bounty-program for oppdagelse av sårbarheter. Sonnet 4, selv om det fortsatt styres av robuste filter- og red-teaming-protokoller, er vurdert til ASL-2, noe som gjenspeiler en lavere risikoprofil i tråd med dens mindre autonome bruksscenarier. Anthropics frivillige selvregulering tar sikte på å demonstrere at streng sikkerhet ikke trenger å hindre kommersiell distribusjon.
Performance Benchmarks
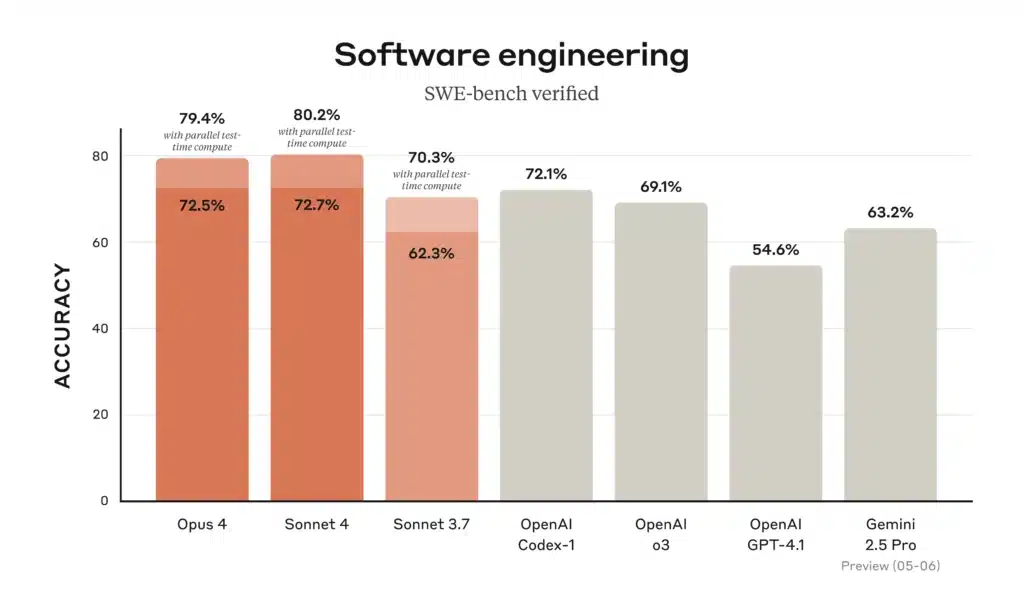
Figur: Programvareutviklingsnøyaktighet (SWE-bench verifisert) for Claude 4-modeller vs. tidligere modeller (jo høyere, jo bedre). Både Opus 4 og Sonnet 4 rangerer øverst på standardreferansene. På Anthropics SWE-benk (programvareutvikling) I testen scorer Opus 4 ~72.5 % og Sonnet 4 ~72.7 % (langt over Claude Sonnet 3.7s ~62 %). Figuren ovenfor (fra Anthropic) illustrerer at begge de nye modellene (oransje søyler) yter bedre enn tidligere Claude-versjoner og til og med GPT-4.1 på reelle kodeoppgaver.
- Koding (SWE-benk): Opus 4 = 72.5 %; Sonett 4 = 72.7 %. Begge overgår eldre modeller langt (Sonett 3.7 = 62.3 %, GPT-4.1 ≈54.6 %). Dette bekrefter Anthropics påstand om at både Claude 4-modellene leder an på kodingsbenchmarks.
- Resonering på høyere nivå (GPQA Diamond): Anthropic rapporterer Opus 4 på 74.9 % mot Sonnet 4 på 70.0 %. Dette er en intern referanse for kompleks vitenskapelig resonnement; Opus har et beskjedent forsprang her.
- Kunnskap (MMLU): Opus 4: 87.4 % vs. Sonett 4: 85.4 % på MMLU. Igjen er Opus litt høyere, men begge scorer sterkt (Anthropic bemerker at Sonett 4 «forbedrer seg betydelig» i forhold til 3.7 på MMLU).
- Uavhengige kodetester: I åpne evalueringer presterer begge modellene utmerket. For eksempel ga en tredjepartstest på en Next.js-kodingsoppgave Opus 4 en 9.5/10 og Sonnet 4 en 9.25/10 (begge lik eller over GPT-4.1 på den utfordringen). Begge modellene produserte konsis og korrekt kode mer pålitelig enn andre LLM-er.
- Andre referansepunkter: På matematikkkonkurransen for videregående skole (AIME) skårer begge lavt (~33 %, en kjent vanskelighetsgrad for alle LLM-er). For verktøybruk og agentoppgaver (TAU-benkvarianter) rapporterer Anthropic sterke resultater (>80 % på noen deloppgaver) for begge modellene. Oppsummert har Opus 4 vanligvis en liten ytelsesfordel på vanskelige benchmarks, men Sonnet 4 er fortsatt ekstremt kapabel; ofte er avveiningen kostnad og hastighet.
Samlet, Claude Opus 4 er toppmodellen (best for svært krevende oppgaver), mens Claude Sonnet 4 leverer nesten like mye kraft med mye høyere effektivitet. Prisene og tilgjengeligheten deres gjenspeiler dette: Sonnet 4 er ideell for skalerte applikasjoner (og gratisbrukere), mens Opus 4 er reservert for team som trenger den minste ytelse.
Pris
Tokenkostnader (API): Opus 4 er priset til 15 dollar per million input-tokens og 75 dollar per million output-tokens, mens Sonnet 4 bare koster 3 dollar/15 dollar (input/output). Disse prisene samsvarer med Anthropics tidligere Claude v4-priser.
rabatter: Anthropic tilbyr store rabatter på Opus 4: rask mellomlagring kan redusere tokenkostnadene med opptil 90 %, og batchbehandling med opptil 50 %. (Sonnet 4s lavere basiskostnad gjør det billigere selv uten disse funksjonene.)
Abonnement inkludert: Sonett 4 er inkludert selv på gratis Claude-abonnementet, mens Opus 4 krever et betalt Claude Pro/Team/Enterprise-abonnement. I praksis betyr dette at all bruk av Sonnet 4 (i Claude Chat eller API) er svært rimelig, men Opus 4 er kun tilgjengelig for betalende kunder.
Hvordan er Sonnet 4 sammenlignet med Claude Opus 4 i brukstilfeller?
Mens Opus 4 er Anthropics flaggskipmodell for topp ytelse, skaper Sonnet 4 sin nisje innen praktisk bruk og tilgjengelighet.
Ytelse vs. praktisk
- Rå kapasitetI sammenlignende testresultater overgår Opus 4 Sonnet 4 i kompleks resonnering, nøyaktighet i kodegenerering og vedvarende arbeidsflyter i flere trinn, noe som gjenspeiler dens status som «best i klassen».
- **Effektivitet:**Sonnet 4 leverer omtrent 80 prosent av Opus 4s ytelse til halvparten av beregningskostnaden, noe som gjør det til et attraktivt alternativ for rutineoppgaver og budsjettsensitive prosjekter.
Bruk saksscenarier
| Bruk sak | Claude Sonnet 4 | Claude Opus 4 |
|---|---|---|
| Daglig koding | ✔️ Balansert hastighet og nøyaktighet | ✔️ Maksimal nøyaktighet |
| Forskning og vitenskapelig AI | ✔️ Bra for sammendrag og prototyping | ✔️ Overlegen dyptgående resonnement |
| Autonome agentarbeidsflyter | ✔️ Agenter på inngangsnivå | ✔️ Høy kompleksitet, langsiktig |
| Kostnadssensitive implementeringer | ✔️ Optimalisert for ressurseffektivitet | ❌ Kun premiumnivå |
Tilgjengelighet og integrasjon med utviklerverktøy
Claude Chat og apper: Begge modellene er tilgjengelige på Anthropics Claude-grensesnitt (nett og apper). Sonnet 4 er tilgjengelig for alle brukere, inkludert gratisversjonen, mens Opus 4 kun kan brukes på betalte abonnementer (Pro/Max/Team/Enterprise).
Antropisk API og skyplattformer: Begge Claude-modellene er tilgjengelige via Anthropics REST API, og er oppført på store skyplattformer. Anthropic sier at dette «gir utviklere umiddelbar tilgang» til modellene og deres resonnement- og agentegenskaper.
IDE-er og redigeringsprogramtillegg: Anthropic har dypt integrert Claude 4 i kodingsarbeidsflyter. Den nye Claude Code Produktet bygger inn Claude direkte i utviklermiljøer. Betautvidelser for VS Code og JetBrains IDE-er lar modellen foreslå kodeendringer innebygd i filene dine. Det finnes også en GitHub Actions-integrasjon: du kan tagge Claude Code på en pull-forespørsel for å automatisk fikse en mislykket CI-test eller svare på kommentarer fra anmeldere. En Claude Code SDK lar deg kjøre Claude som en delprosess på lokale maskiner. Kort sagt kan Sonnet 4 og Opus 4 nå fungere som parprogrammerere i kjente verktøy. Anthropic bemerker at GitHub vil bruke Sonnet 4 som modellen bak sin nye AI-assisterte kodeagent, og det finnes allerede koblinger for VS Code, JetBrains og GitHub. Dette økosystemet betyr at utviklere kan utnytte Claudes funksjoner uten å forlate sitt vanlige miljø.
API-er og automatisering av arbeidsflyt: Begge modellene støtter programmatisk bruk fullt ut. Anthropics API (v1) er oppdatert slik at du kan veksle mellom tenkemoduser, angi sikkerhetsnivåer og koble til verktøykoblinger. I praksis kan et Python-klientkall se identisk ut bortsett fra modellnavnet (claude-opus-4-20250514 vs claude-sonnet-4-20250514). På CometAPI, API-et gir et enhetlig grensesnitt for å kalle begge modellene. Utviklere kan integrere dem i automatiserte arbeidsflyter (CI/CD, overvåking, datapipelines) ved hjelp av sitt foretrukne språk eller REST-klienter.
Sammenligning Chart
| Trekk | Claude Opus 4 | Claude Sonnet 4 |
|---|---|---|
| Modell Type | Største «Opus»-modell – fokusert på maksimal resonneringskraft. | Mellomstor modell – balanse mellom hastighet, kostnad og kapasitet. |
| Kontekstvindu | 200 XNUMX tokens (enorm kontekst); ekstremt lange dokumenter eller kode med flere filer. | 200 XNUMX tokens (samme veldig store kontekst). |
| Utgangslengde | Opptil 32 XNUMX tokens per svar (egnet for komplekse kodeutdata). | Opptil 64 XNUMX tokens per svar (lengre utganger). |
| Ytelse (SWE-benk) | ~72.5–79 % (ledende kodestandard). | ~72.7–80 % (svært lik kodingsscore). |
| Ytelse (generell IQ) | Sterk avansert resonnement (MMLU ~87 %). Overgår Sonnet litt. | Sterk resonnering (MMLU ~85%); litt lavere enn Opus på vanskelige oppgaver. |
| Bruk eksempler på saker | Best for langvarige kodeprosjekter, grundig research og agentplanlegging (f.eks. refaktorering av prosjekter med flere filer, timeslange simuleringer). | Best for oppgaver med høyt volum og interaktive agenter (f.eks. live chatbots, kodegjennomganger, CI-automatisering). |
| Utvidet tenkning | Ja (64K-token-tenkemodus; flott for dyp flertrinnsresonnering). Ideell for oppgaver som drar nytte av lengre «tanker». | Ja (64K-token-tenkemodus). Støtter det også, med brukersynlige resonnementssammendrag. |
| Verktøysstøtte | Full verktøybruk (parallelt nettsøk, kodekjøring, fil-I/O, osv.). | Full verktøybruk (samme kapasitet). |
| Minne og «filer» | Avansert langtidshukommelse via Files API; utmerker seg ved sporing av prosjektstatus. | Samme hukommelsesfunksjoner; kan også lagre og gjenkalle fakta. |
| Multimodal inngang | Sterk kode + tekst; kan behandle bilder via verktøy (visjonsanalyse). Primært tekst-/kodingsoppgaver. | Inkluderer visjon og brukergrensesnittfunksjoner; kan analysere bilder/skjermbilder og til og med «bruke» programvaregrensesnitt. |
| Latens og gjennomstrømning | Høyere latens (tyngre beregningskraft). Best for batch-/automatiserte arbeidsflyter der dybde er viktig. | Lavere latens (raskere respons). Optimalisert for interaktiv bruk og strømming. |
| Tilgjengelighet | Anthropic API (Pro/Enterprise), AWS Bedrock, GCP Vertex. Kun betalt nivå. | Anthropic API (alle nivåer), AWS Bedrock, GCP Vertex. Også gratis på Claude. |
| Priser (tokens) | $15 per M inngang, $75 per M-utgang. | $3 per M inngang, $15 per M-utgang. |
| Sikkerhet/justering | Høyeste sikkerhetsnivå (ASL-3+ tiltak), «minst sannsynlig» snarvei. | Samme robuste sikkerhetstiltak (ASL-3). Litt mer effektiv, samme justering. |
Konklusjon
I 2025 representerer Anthropics Claude Opus 4 og Sonnet 4 et betydelig sprang for utviklerfokusert AI. De introduserer utvidet multimodal resonnering, dypere verktøyintegrasjon og enestående kontekstlengder som direkte adresserer utfordringer i moderne utviklingsarbeidsflyter. Ved å bygge inn disse modellene gjennom API- eller skyplattformer kan team automatisere langt mer av programvarens livssyklus – fra kodedesign til distribusjon – uten å miste nøyaktighet eller justering. Opus 4 bringer grensesprengende AI-resonnering til komplekse, åpne oppgaver, mens Sonnet 4 bringer høyhastighets, budsjettvennlig ytelse til hverdagslige koding- og agentbehov.
Disse forbedringene – utvidet tenkning, minnefiler, parallelle verktøy og strømlinjeformet IDE-integrasjon – er ikke bare inkrementelle. De omformer hvordan utviklere samhandler med AI: de går fra raske engangsfullføringer til vedvarende samarbeid på tvers av arbeidstimer. Resultatet er at rutinemessige utviklingsoppgaver blir raskere og mer pålitelige, slik at ingeniører kan fokusere på kreativitet og oversikt. Som Anthropic sier, med Claude 4 «kan du bruke Opus 4 til å skrive og refaktorere kode på tvers av hele prosjekter» og Sonnet 4 til å drive «daglige utviklingsoppgaver».
Komme i gang
CometAPI tilbyr et enhetlig REST-grensesnitt som samler hundrevis av AI-modeller – inkludert Claude-familien – under et konsistent endepunkt, med innebygd API-nøkkeladministrasjon, brukskvoter og faktureringsdashboards. I stedet for å sjonglere flere leverandør-URL-er og legitimasjonsinformasjon.
Utviklere har tilgang Claude Sonnet 4 API (modell: claude-sonnet-4-20250514 ; claude-sonnet-4-20250514-thinking) Og Claude Opus 4 API (modell: claude-opus-4-20250514; claude-opus-4-20250514-thinking)osv. gjennom CometAPI... For å begynne, utforsk modellens muligheter i lekeplass og konsulter API-veiledning for detaljerte instruksjoner. Før du åpner, må du sørge for at du har logget inn på CometAPI og fått API-nøkkelen. CometAPI har også lagt til cometapi-sonnet-4-20250514ogcometapi-sonnet-4-20250514-thinking spesielt for bruk i markør.
Ny bruker av CometAPI? Start en gratis prøveperiode på 1 dollar og slipp løs Sonnet 4 på de vanskeligste oppgavene dine.
Vi gleder oss til å se hva du lager. Hvis noe føles rart, trykk på tilbakemeldingsknappen – å fortelle oss hva som gikk i stykker er den raskeste måten å gjøre det bedre på.