
Gemini 2.5 Flash API er Googles nyeste multimodale AI-modell, designet for høyhastighets, kostnadseffektive oppgaver med kontrollerbare resonneringsmuligheter, slik at utviklere kan slå avanserte "tenkefunksjoner" av eller på via Gemini API. De nyeste modellene er gemini-2.5-flash.
Oversikt over Gemini 2.5 Flash
Gemini 2.5 Flash er konstruert for å levere raske svar uten at det går på bekostning av kvaliteten på utskriften. Den støtter multimodale innganger, inkludert tekst, bilder, lyd og video, noe som gjør den egnet for ulike applikasjoner. Modellen er tilgjengelig via plattformer som Google AI Studio og Vertex AI, og gir utviklere de nødvendige verktøyene for sømløs integrasjon i ulike systemer.
Grunnleggende informasjon (funksjoner)
Gemini 2.5 Flash introduserer flere unike funksjoner egenskaper som skiller den innenfor Gemini 2.5-familien:
- Hybrid resonnementUtviklere kan angi en tenkningsbudsjett parameter for å finjustere hvor mange tokens modellen dedikerer til intern resonnering før utdata.
- Pareto-grensen: Plassert ved optimalt kostnads-ytelsespunktFlash tilbyr det beste forholdet mellom pris og intelligens blant 2.5-modellene.
- Multimodal støtte: Prosesser tekst, bilder, videoog lyd innebygd, noe som muliggjør rikere samtale- og analytiske muligheter.
- Kontekst med 1 million tokenerUovertruffen kontekstlengde tillater dyp analyse og forståelse av lange dokumenter i én forespørsel.
Modellversjon
Gemini 2.5 Flash har gått gjennom følgende nøkkel versjoner:
- gemini-2.5-flash-lite-preview-09-2025: Forbedret brukervennlighet for verktøy: Forbedret ytelse på komplekse oppgaver med flere trinn, med en økning på 5 % i SWE-Bench Verified-poengsummer (fra 48.9 % til 54 %). Forbedret effektivitet: Når resonnering aktiveres, oppnås resultater av høyere kvalitet med færre tokens, noe som reduserer ventetid og kostnader.
- Forhåndsvisning 04-17Tidlig tilgang med «tenkefunksjon», tilgjengelig via gemini-2.5-flash-preview-04-17.
- Stabil generell tilgjengelighet (GA): Fra og med 17. juni 2025, det stabile endepunktet gemini-2.5-blits erstatter forhåndsvisningen, og sikrer pålitelighet i produksjonsklasse uten API-endringer fra forhåndsvisningen 20. mai.
- Avskrivning av forhåndsvisningForhåndsvisningsendepunktene skulle etter planen legges ned 15. juli 2025. Brukere må migrere til GA-endepunktet før denne datoen.
Fra juli 2025 er Gemini 2.5 Flash nå offentlig tilgjengelig og stabil (ingen endringer fra gemini-2.5-flash-preview-05-20 Hvis du bruker gemini-2.5-flash-preview-04-17, vil den eksisterende forhåndsvisningsprisen fortsette frem til den planlagte avviklingen av modellendepunktet 15. juli 2025, da det vil bli lagt ned. Du kan migrere til den generelt tilgjengelige modellen «gemini-2.5-flash".
Raskere, billigere, smartere:
- Designmål: lav latens + høy gjennomstrømning + lav kostnad;
- Generell hastighetsøkning i resonnering, multimodal prosessering og oppgaver med lange tekster;
- Bruken av tokener reduseres med 20–30 %, noe som reduserer resonneringskostnadene betydelig.
Tekniske spesifikasjoner
Kontekstvindu for inndata: Opptil 1 million tokens, noe som gir omfattende kontekstlagring.
Utdatatokener: Kan generere opptil 8,192 tokener per svar.
Støttede modaliteter: Tekst, bilder, lyd og video.
Integrasjonsplattformer: Tilgjengelig via Google AI Studio og Vertex AI.
Prissetting: Konkurransedyktig tokenbasert prismodell, som legger til rette for kostnadseffektiv utrulling.
Tekniske detaljer
Under panseret er Gemini 2.5 Flash en transformatorbasert Stor språkmodell trent på en blanding av web-, kode-, bilde- og videodata. Nøkkel teknisk spesifikasjonene inkluderer:
Multimodal opplæringFlash er trent til å justere flere modaliteter, og kan sømløst blande tekst med bilder, videoeller lyd, nyttig for oppgaver som videosammendrag eller lydteksting.
Dynamisk tankeprosessImplementerer en intern resonneringsløkke der modellen planer og bryter ned komplekse spørsmål før endelig utgang.
Konfigurerbare tenkningsbudsjetter: The tenkningsbudsjett kan stilles inn fra 0 (ingen begrunnelse) opp til 24,576-symboler, noe som tillater avveininger mellom latens og svarkvalitet.
Verktøyintegrasjon: Støtter Jording med Google Søk, Kodeutførelse, URL-kontekstog Funksjonsanrop, som muliggjør handlinger i den virkelige verden direkte fra naturlige språkforespørsler.
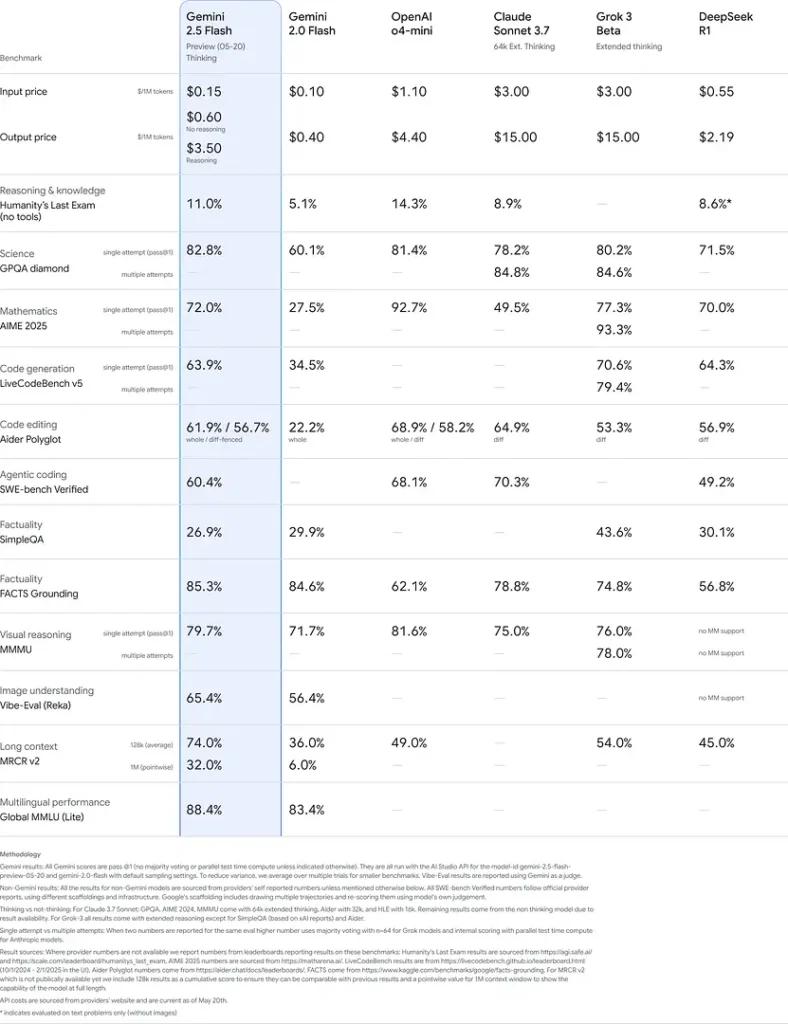
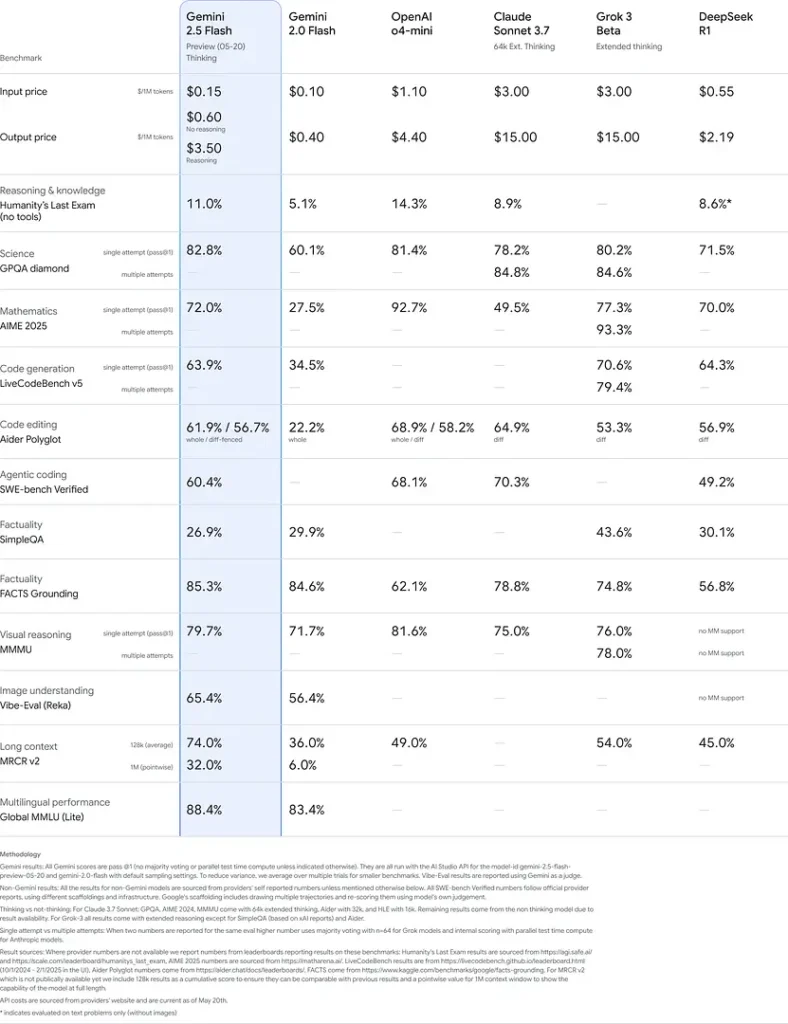
Benchmark ytelse
I grundige evalueringer demonstrerer Gemini 2.5 Flash bransjeledende opptreden:
- LMArena vanskelige ledetekster: Scoret nest etter 2.5 Pro på den utfordrende Hard Prompts-referansemodellen, som viser frem sterke evner til å resonnere i flere trinn.
- MMLU-poengsum på 0.809Overgår gjennomsnittlig modellytelse med en 0.809 MMLU-nøyaktighet, som gjenspeiler dens brede domenekunnskap og resonneringsevne.
- Latens og gjennomstrømning: Oppnår 271.4 tokens/sek dekodingshastighet med en 0.29 s Tid til første token, noe som gjør den ideell for latensfølsomme arbeidsbelastninger.
- Leder innen pris-til-ytelse: På 0.26 dollar/1 million tokensFlash underbyr mange konkurrenter, samtidig som den matcher eller overgår dem på viktige referansepunkter.
Disse resultatene indikerer Gemini 2.5 Flashs konkurransefortrinn innen resonnering, vitenskapelig forståelse, matematisk problemløsning, koding, visuell tolkning og flerspråklige evner:
Begrensninger
Selv om den er kraftig, bærer Gemini 2.5 Flash visse begrensninger:
- SikkerhetsrisikoerModellen kan vise en «predikkende» tone og kan produsere troverdige, men feilaktige eller partiske resultater (hallusinasjoner), spesielt ved spørringer i utkanten av saken. Streng menneskelig tilsyn er fortsatt avgjørende.
- SatsgrenserAPI-bruk er begrenset av hastighetsgrenser (10 RPM, 250,000 250 TPM, XNUMX RPD på standardnivåer), som kan påvirke batchbehandling eller applikasjoner med høyt volum.
- EtterretningsetasjeSelv om den er usedvanlig kapabel til en blitz modell, forblir den mindre nøyaktig enn 2.5 Pro på de mest krevende agentoppgavene som avansert koding eller koordinering mellom flere agenter.
- KostnadsavveiningerSelv om de tilbyr det beste pris-ytelse, utstrakt bruk av tenker Modus øker det totale tokenforbruket, noe som øker kostnadene for dypt resonnerende prompter.
Se også Gemini 2.5 Pro API
Konklusjon
Gemini 2.5 Flash står som et bevis på Googles forpliktelse til å fremme AI-teknologier. Med sin robuste ytelse, multimodale evner og effektive ressursstyring tilbyr den en omfattende løsning for utviklere og organisasjoner som ønsker å utnytte kraften til kunstig intelligens i sine operasjoner.
Hvordan ringe Gemini 2.5 Flash API fra CometAPI
Gemini 2.5 Flash API-priser i CometAPI, 20 % avslag på den offisielle prisen:
- Input tokens: $0.24 / M tokens
- Output tokens: $0.96/M tokens
Nødvendige trinn
- Logg på cometapi.com. Hvis du ikke er vår bruker ennå, vennligst registrer deg først
- Få tilgangslegitimasjons-API-nøkkelen til grensesnittet. Klikk "Legg til token" ved API-tokenet i det personlige senteret, hent tokennøkkelen: sk-xxxxx og send inn.
- Få url til dette nettstedet: https://api.cometapi.com/
Bruksmetoder
- Velg "
gemini-2.5-flash” endepunkt for å sende API-forespørselen og angi forespørselsteksten. Forespørselsmetoden og forespørselsteksten er hentet fra vårt API-dokument for nettstedet vårt. Vårt nettsted gir også Apifox-test for din bekvemmelighet. - Bytt ut med din faktiske CometAPI-nøkkel fra kontoen din.
- Sett inn spørsmålet eller forespørselen din i innholdsfeltet – det er dette modellen vil svare på.
- . Behandle API-svaret for å få det genererte svaret.
For modelllunsjinformasjon i Comet API, se https://api.cometapi.com/new-model.
For modellprisinformasjon i Comet API, se https://api.cometapi.com/pricing.
Eksempel på API-bruk
Utviklere kan samhandle med gemini-2.5-blits gjennom CometAPIs API, som muliggjør integrering i ulike applikasjoner. Nedenfor er et Python-eksempel:
import os
from openai import OpenAI
client = OpenAI(
base_url="
https://api.cometapi.com/v1/chat/completions",
api_key="<YOUR_API_KEY>",
)
response = openai.ChatCompletion.create(
model="gemini-2.5-flash",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain the concept of quantum entanglement."}
]
)
print(response)
Dette skriptet sender en melding til Gemini 2.5 Flash modell og skriver ut den genererte responsen, og demonstrerer hvordan den skal brukes Gemini 2.5 Flash for komplekse forklaringer.