

GLM-5-Turbo er en ny grunnleggende LLM fra Zhipu AI som er spesifikt trent og finjustert for agentlignende arbeidsflyter (selskapet kaller måløkosystemet OpenClaw / «lobster»-scenarier). Den tilbyr en svært lang kontekst (opptil ~200K tokens), strømming og strukturerte utdata, lavere feilrater ved verktøykall (rapportert ~0,67 % i tredjepartstester), og vesentlig lavere pris per token. Modellen har som mål å bytte bort en liten del av maksimal ytelse i enkeltstående forespørsler mot langt bedre stabilitet, verktøypålitelighet, håndtering av planlagte/vedvarende oppgaver og kjøring av lange kjeder — nyttig for autonome agenter, orkestreringssystemer og fler-verktøysrørledninger.
Hva er GLM-5-Turbo?
GLM-5-Turbo presenteres av Zhipu som en grunnmodell bygget spesielt for agentorkestrering og komplekse automatiserte arbeidsflyter snarere enn som en generell chat- eller multimodal modell. Designvalgene vektlegger:
- Innebygd agentvennlig trening (verktøybruk, følge kommandoer, tidsstyrte/vedvarende oppgaver).
- Svært store kontekstvinduer og utdata-kapasitet for å støtte lange økter, minne og planlegging i chain-of-thought.
- Stabil inferens med høy gjennomstrømning for lange forretningsflyter og planlagte oppgaver.
I motsetning til tradisjonelle LLM-er som er optimalisert for chat eller tekstgenerering, er GLM-5-Turbo:
- Agent-først (ikke chat-først)
- Bygget for OpenClaw («lobster»)-miljøer
- Designet for autonome arbeidsflyter i flere trinn
🦞 Hva betyr «Lobster Agent»?
«Lobster»-konseptet viser til OpenClaw, Zhipus AI-agentøkosystem der modeller:
- Bruker verktøy dynamisk
- Utfører lange oppgavekjeder
- Opprettholder vedvarende minne
- Opererer på tvers av terminaler, apper og API-er
GLM-5-Turbo er dypt optimalisert for dette paradigmet, og løser sentrale agentproblemer som:
- Pålitelighet ved verktøykall
- Oppgavedecomponering
- Langsiktig planlegging
- Utførelsesstabilitet
Nøkkelfunksjoner og hvorfor de betyr noe
Lang kontekst + enorm utdata-kapasitet (200K / 128K)
Et kontekstvindu på 200K tokens og en utdata-kapasitet på 128K gjør at GLM-5-Turbo kan:
- Beholde utvidet minne om tidligere kontekst (samtaler, verktøyutdata, mellomresultater).
- Produsere svært lange genererte artefakter (flertrinnsplaner, lange rapporter, kodebaser) uten gjentatt sammenføying av kontekst.
- Drive multi-turn-agenter som må beholde hele utførelseshistorikken for nøyaktig beslutningstaking.
Dette er et bevisst teknisk valg for agenter — i stedet for å dele opp oppgaver i korte forespørsler, kan agenter opprettholde en sammenhengende tilstand gjennom tusenvis av samtaleomganger eller steg.
Agentprimitive bygget inn i treningen
I stedet for å ettermontere en generell modell for agentoppgaver, ble GLM-5-Turbo trent med målsettinger i agentstil (f.eks. verktøykallatferd, kommando-/argumenttolking). Den påståtte effekten er færre hallusinasjoner under verktøykall, mer stabile planer i flere trinn og forbedret latens under lange kjøringer — alt verdifullt der automatisering må kjede sammen mange eksterne API-er eller verktøy pålitelig.
Gjennomstrømning og utførelsesstabilitet
GLM-5-Turbo-varianten forbedrer utførelsesstabilitet og gjennomstrømning for lange forretningsflyter sammenlignet med generaliserte store modeller — markedsføringsspråket fremhever «utførelse med høy gjennomstrømning» og «ledende responsstabilitet» blant lignende modeller. Dette er meningsfullt for bedriftsdistribusjoner av agenter, der ett mislykket steg kan ødelegge en hel rørledning. Uavhengige tredjepartsbenchmarks er fortsatt på vei.
Benchmarkdata for GLM-5-Turbo
Merk: Zhipu har publisert interne evalueringer, og tredjeparts-/akademiske benchmarks for GLM-5 er tilgjengelige. GLM-5-Turbo er nylig lansert; det vil ta tid før uavhengige benchmarkkjøringer i miljøet dukker opp. Nedenfor lister vi de mest forsvarlige, publiserte tallene og konteksten.
GLM-5 (referanse) — representative publiserte måltall
Zhipus GLM-5 (flaggskipforgjengeren til Turbo) rapporterer sterke plasseringer på ledertavler i mange ingeniør-/arbeidsflytoppgaver — for eksempel:
- SWE-bench Verified: 77,8 (rapportert i GLM-5-dokumentasjonen som en ledende score for åpne modeller).
- Terminal Bench 2.0: 56,2 (rapportert som beste åpne modell-ytelse på den gitte distribusjonen).
Disse tallene etablerer GLM-5 som et høyt utgangspunkt i programvareteknikk og utførelsesoppgaver; GLM-5-Turbo er posisjonert for å bytte bort noe rå størrelse-/parameterfokus mot bedre agentpålitelighet og gjennomstrømning. GLM-5-Turbo viste ~0,67 % feil ved verktøykall i deres sammenligningskjøringer, vesentlig lavere enn sammenlignbare GLM-5-leverandørkjøringer som lå mellom ~2,33 % og 6,41 %.
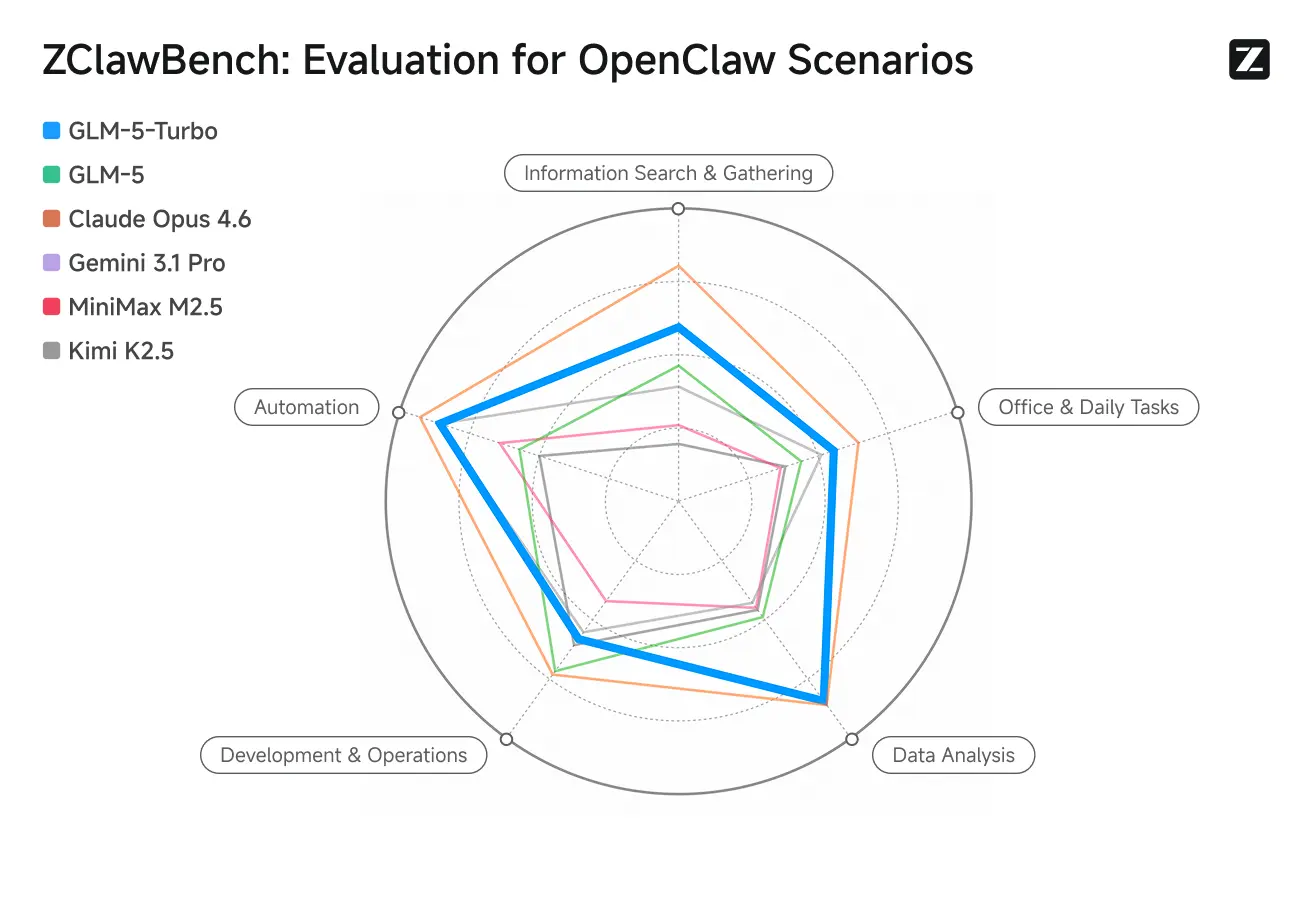
ZClawBench: Benchmarktest for OpenClaw Proxy-scenarier
Zhipu lanserte også benchmarken ZClawBench for å evaluere intelligente agenter. I blindtester som dekket ulike felt som kodeutvikling, dataanalyse og innholdsproduksjon, vant den nye modellen med kodenavn Pony-Alpha-2 gehør hos 90 % av respondentene.
Prising og tilgjengelighet (hvem som selger den og hvor mye)
Zhipu innførte en ~20 % økning i API-pris for GLM-5-Turbo-tilbudet ved lansering og introduserte samtidig «Lobster Package»-abonnementsnivåer ment å jevne ut tokenprisingen for agentdistribusjoner.
Rapporterte abonnementsnivåer (eksempelpakkar)
To illustrative Lobster-pakker (prisene er rapporterte konverteringer og omtrentlige):
- Entry Lobster-plan: ~39 CNY / måned (~US$5,66) for 35 000 000 tokens.
- Mid Lobster-plan: ~99 CNY / måned (~US$14,36) for 100 000 000 tokens.
Med disse publiserte tallene er kostnaden per 1 million tokens omtrent:
- Entry-plan: ~US$0,162 per 1M tokens.
- Mid-plan: ~US$0,144 per 1M tokens.
Disse tallene per 1M er enkle konverteringer av publisert abonnementspris og tokentak, og illustrerer økonomien for agentarbeidsbelastninger med høyt volum. (Beregningene er basert på presserapportert valuta og tokenmengder.)
API-pris
Representativ markedsplassoppføring (CometAPI): $0,96 per 1M inndatatokens og $3,20 per 1M utdatatokens for GLM-5-Turbo.
Zhipus egen utviklerprisside (Z.ai) oppgir en noe høyere direktesats for GLM-5-Turbo: $1,20 per 1M inndatatokens og $4,00 per 1M utdatatokens (satser for bufret input er lavere).
GLM-5-Turbo vs GLM-5 — sammenligning side om side
På et overordnet nivå:
- GLM-5 = flaggskip grunnmodell for generelle formål (sterk resonnering, koding, benchmarks)
- GLM-5-Turbo = agentoptimalisert variant av GLM-5 (fokusert på lange arbeidsflyter, verktøybruk, stabilitet)
GLM-5-Turbo er ikke en helt ny modellarkitektur, men en spesialisert, produksjonsoptimalisert versjon av GLM-5 designet for agentsystemer som OpenClaw.
Kjerneposisjonering
| Modell | Posisjonering |
|---|---|
| GLM-5 | Flaggskip-LLM for generelle formål (resonnering, koding, benchmarks) |
| GLM-5-Turbo | Agent-først-modell (automatisering, orkestrering, verktøybruk) |
👉 Enkelt sagt:
- Bruk GLM-5 → når du vil ha maksimal intelligens
- Bruk GLM-5-Turbo → når du vil ha stabil automatisering / agenter
Sammenligning av agentkapasitet (VIKTIGST)
GLM-5 (agentkapasitet) støtter allerede:
- Verktøybruk
- Resonering i flere trinn
- Kodeagenter
Men begrensninger:
- Kan miste kontekst i lange kjeder
- Verktøykall kan forringes over tid
- Krever mer orkestreringslogikk
GLM-5-Turbo er eksplisitt optimalisert for agenter:
Viktige forbedringer:
- Pålitelighet ved verktøykall ↑
- Oppgavedecomponering (planlegging) ↑
- Konsistens i lange kjeder ↑
- Støtte for vedvarende utførelse ↑
Eksempel på forbedring:
- Stabil utførelse over 10+ steg uten å miste kontekst
👉 Dette er kritisk for:
- Systemer i AutoGPT-stil
- Arbeidsflyter med flere agenter
- SaaS-automatisering
Hastighet og effektivitet
| Aspekt | GLM-5 | GLM-5-Turbo |
|---|---|---|
| Inferenshastighet | Moderat | Raskere |
| Gjennomstrømning | Standard | Høyere |
| Latens for lange oppgaver | Kan forringes | Optimalisert |
GLM-5-Turbo er designet for å løse et reelt bransjeproblem:
Store modeller blir tregere eller bryter sammen under lange arbeidsflyter
Prissammenligning
| Modell | Input ($/1M tokens) | Output ($/1M tokens) |
|---|---|---|
| GLM-5 | ~$1,00 | ~$3,20 |
| GLM-5-Turbo | ~$1,20 | ~$4,00 |
👉 GLM-5-Turbo er dyrere (~20 % høyere)
Hvorfor dyrere?
Fordi den gir:
- Bedre pålitelighet i orkestrering
- Høyere produksjonsstabilitet
- Agentspesifikke optimaliseringer
👉 I bedriftssammenheng:
- Du betaler mer per token
- Men reduserer kostnader ved feil + nye forsøk
| Attributt | GLM-5 | GLM-5-Turbo |
|---|---|---|
| Primært mål | Generell flaggskip-grunnmodell (brede kapabiliteter, sterk koding/benchmarks) | Agent-/«OpenClaw»-/lobster-optimalisert grunnmodell |
| Kontekstvindu | (rapportert høyt; GLM-5 fokuserer på ~200K (GLM-5 støtter også lang kontekst) | 200 000 tokens (eksplisitt dokumentert). |
| Maksimalt antall output-tokens | (stort, modellavhengig) | 128 000 tokens (dokumentert). |
| Viktige benchmarkresultater | SWE-bench: 77,8; Terminal Bench 2.0: 56,2 (GLM-5-rapporterte tall). | Interne evalueringer hevder forbedret stabilitet i lange kjeder og høyere gjennomstrømning for agentarbeidsflyter; uavhengige offentlige benchmarks avventes. |
| Modaliteter | Tekst (primært), GLM-familien har synsvarianter i søskenmodeller | Kun tekst (ifølge dokumentasjon) — optimalisert for verktøybaserte agenter. |
| Anbefalte bruksområder | Bredt: chat, kode, resonnering, innhold | Agentorkestrering, verktøykall, langsiktig automatisering |
| Prising | Eksisterende GLM-5-priser (varierer etter plan) | Ny lansering — rapportert ~20 % API-prisøkning; nye Lobster-abonnementsnivåer introdusert |
Hvordan bruke GLM-5-Turbo
CometAPI — én API-tilgang til mange modeller (OpenAI-kompatibel)
CometAPI oppgir at GLM-5-Turbo er tilgjengelig og tilbyr en OpenAI-kompatibel base-URL og SDK. Bruk modellstrengen de publiserer (nettstedet deres oppgir GLM-5-Turbo til lignende priser). Eksempler tilpasset fra CometAPI-dokumentasjonen:
curl (CometAPI):
curl -X POST "https://api.cometapi.com/v1/chat/completions" \ -H "Authorization: Bearer YOUR_COMETAPI_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "z-glm-5-turbo", // or use the exact model slug shown in CometAPI UI "messages": [{"role":"user","content":"Create a 5-step checklist for onboarding a new hire."}], "max_tokens": 800 }'
CometAPIs verdi ligger i aggregatorbekvemmelighet (én integrasjon for mange modeller). Bekreft nøyaktig modellslug i CometAPI-dashbordet før du gjør kall.
Beste praksis ved bygging av Lobster- / OpenClaw-agenter med GLM-5-Turbo
- Design for pålitelighet, ikke rå latens: Turbos fordel er lavere feil ved verktøykall i lange kjeder. Strukturer agentkjøringer slik at de foretrekker robuste fullføringer (nye forsøk, idempotente verktøykall) fremfor minimale gevinster i tid til første token.
- Bruk strømming og inkrementelle verktøykall: Ta i bruk strømming/oppdelte utdata for å redusere omarbeid og muliggjøre tidlig verktøyaktivering der det passer. GLM-5-Turbo støtter strømming.
- Strukturerte utdata for parsere: Foretrekk JSON eller godt formaterte resultater for deterministisk parsing i nedstrømsverktøy. Turbo støtter strukturerte utdata.
- Planlegg for planlegging / persistens: Hvis agenten din må sjekke periodisk eller kjøre bakgrunnsoppgaver, bruk Turbos bedre tidssemantikk og cachefunksjoner for å unngå ny planlegging i hver syklus.
- Instrumenter verktøykall og reservebaner: Logg verktøykall og utform elegante reservebaner (f.eks. prøv igjen med litt annen temperatur eller kall et reserveverktøy), siden agentiske arbeidsflyter er skjøre hvis ett eksternt API feiler. Turbo reduserer feilrater, men eliminerer ikke eksterne feil
Utviklere kan få tilgang til GLM-5- og GLM-5 turbo-API via CometAPI nå. For å komme i gang, se API-veiledningen for detaljerte instruksjoner. Før tilgang må du sørge for at du har logget inn på CometAPI og hentet API-nøkkelen. CometAPI tilbyr en pris langt lavere enn den offisielle prisen for å hjelpe deg med integrering.
Klar til å komme i gang?→ Registrer deg for GLM-5 og GLM-5 turbo i dag !