GPT-4o lyd-API: En samlet /chat/completions endepunktutvidelse som godtar Opus-kodet lyd (og tekst) og returnerer syntetisert tale eller transkripsjoner med konfigurerbare parametere (model=gpt-4o-audio-preview-<date>, speed, temperature) for batch- og strømming av stemmeinteraksjoner.
Grunnleggende informasjon om GPT-4o Audio
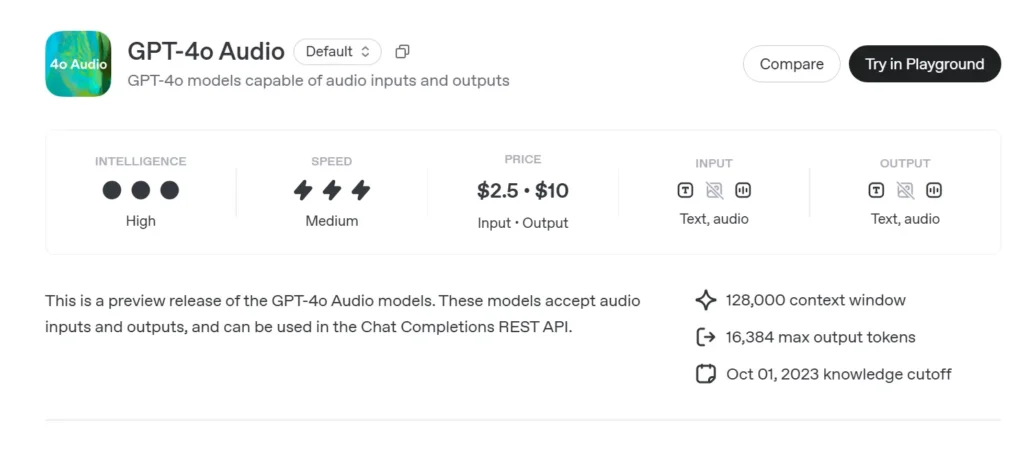
GPT-4o Lydforhåndsvisning (gpt-4o-audio-preview-2025-06-03) er OpenAIs nyeste talesentrisk stor språkmodell gjort tilgjengelig gjennom standarden Chat Completions API snarere enn den ultralave latens-sanntidskanalen. Bygget på samme «omni»-fundament som GPT-4o, spesialiserer denne varianten seg på høykvalitets taleinngang og -utgang for turbaserte samtaler, innholdsproduksjon, tilgjengelighetsverktøy og agentiske arbeidsflyter som ikke krever millisekundtiming. Den arver alle tekstresonnementstyrkene til GPT-4-klassemodeller samtidig som den legger til ende-til-ende tale-til-tale (S2S) rørledninger, deterministiske funksjonsanrop, og den nye speed parameter for kontroll av stemmehastighet.
Kjernefunksjonssettet til GPT-4o Audio
• Enhetlig tale-til-tale-behandling – Lyd transformeres direkte til semantisk rike tokens, resonneres og syntetiseres på nytt uten eksterne STT/TTS-tjenester, noe som gir konsistent stemmeklang, prosodi og kontekstbevaring.
• Forbedret instruksjonsfølging – Levering av tuning i juni 2025 +19 poeng bestått på 1. trinn på talekommandooppgaver kontra GPT-2024o-grunnlinjen fra mai 4, noe som reduserer hallusinasjoner innen domener som kundestøtte og innholdsutkast.
• Stabil verktøyanrop – Modellutgangene strukturert JSON som samsvarer med OpenAI-funksjonskallskjemaet, som gjør det mulig å utløse backend-API-er (søk, bestilling, betalinger) med >95 % argumentnøyaktighet.
• speed Parameter (0.25–4×) – Utviklere kan modulere taleavspilling for langsom læring, normal fortelling eller raske «hørbare skimming»-moduser, uten resyntetisering av tekst eksternt.
• Avbrytelsesbevisst turtaking – Selv om den ikke er like latensdrevet som Realtime-varianten, støtter forhåndsvisningen delvis strømmingTokener sendes ut så snart de er beregnet, slik at brukerne kan avbryte tidlig om nødvendig.
Teknisk arkitektur for GPT-4o
• Enkeltstakktransformator – Som alle GPT-4o-derivater bruker lydforhåndsvisningen en enhetlig koder-dekoder der tekst og akustiske tokener passerer gjennom identiske oppmerksomhetsblokker, noe som fremmer kryssmodal jording.
• Hierarkisk lydtokenisering – Rå 16 kHz PCM → log-mel-patcher → grove akustiske koder → semantiske tokenerDenne flertrinnskompresjonen oppnår 40–50× båndbreddereduksjon samtidig som nyansene bevares, og det muliggjør klipp på flere minutter per kontekstvindu.
• NF4 kvantiserte vekter – Slutningen forkynnes kl. 4-bits normal flyttall presisjon, halverer GPU-minnet sammenlignet med fp16 og opprettholder 70+ strømmings-RTF (sanntidsfaktor) på A100–80 GB-noder.
• Strømmingsoppmerksomhet og KV-hurtigbufring – Roterende innebygde vinduer med skyvevinduer opprettholder kontekst i over ~30 sekunder med tale samtidig som de beholder O(L) minnebruk, ideelt for podkastredigerere eller hjelpemidler for lesing.
Versjonering og navngivning — Forhåndsvisning av spor med datostemplede bygg
| Identifiser | Kanal | Formål | Utgivelsesdato | Stabilitet |
|---|---|---|---|---|
| gpt-4o-lydforhåndsvisning-2025-06-03 | Chat Completions API | Turbaserte lydinteraksjoner, agentoppgaver | 03 juni 2025 | Forhåndsvisning (tilbakemeldinger oppfordres) |
Viktige elementer i navnet:
- gpt-4o – Omni multimodal familie.
- lyd – Optimalisert for bruk i tale.
- forhåndsvisning – API-kontrakten kan utvikle seg; ikke GA ennå.
- 2025-06-03 – Øyeblikksbilde av opplæring og utrulling for reproduserbarhet.
Slik kaller du GPT-4o Audio API API fra CometAPI
GPT-4o Audio API API-priser i CometAPI:
- Input tokens: $2 / M tokens
- Output tokens: $8 / M tokens
Nødvendige trinn
- Logg på cometapi.com. Hvis du ikke er vår bruker ennå, vennligst registrer deg først
- Få tilgangslegitimasjons-API-nøkkelen til grensesnittet. Klikk "Legg til token" ved API-tokenet i det personlige senteret, hent tokennøkkelen: sk-xxxxx og send inn.
- Få url til dette nettstedet: https://api.cometapi.com/
Bruksmetoder
- Velg "
gpt-4o-audio-preview-2025-06-03"endepunkt for å sende forespørselen og angi forespørselsteksten. Forespørselsmetoden og forespørselsteksten er hentet fra nettstedets API-dokumentasjon. Nettstedet vårt tilbyr også Apifox-testing for enkelhets skyld. - Erstatt med din faktiske CometAPI-nøkkel fra kontoen din.
- Sett inn spørsmålet eller forespørselen din i innholdsfeltet – det er dette modellen vil svare på.
- . Behandle API-svaret for å få det genererte svaret.
For informasjon om modelltilgang i Comet API, se API-dok.
For modellprisinformasjon i Comet API, se https://api.cometapi.com/pricing.
API-arbeidsflyt — Chat-fullføringer med lyddeler og funksjonskroker
- Inputformat -
audio/*MIME ellerbase64WAV-biter innebygd imessages[].content. - Utgangsalternativer -
•mode: "text"→ ren tekst for teksting.
•mode: "audio"→ returnerer en streaming Opus- eller µ-lovnyttelast med tidsstempler. - Funksjonspåkall - Legg til
functions:skjema; modellen sender utrole: "function"med JSON-argumenter; utvikleren utfører verktøykallet og sender eventuelt resultatet tilbake. - rate kontroll - Sett
voice.speed=1.25for å akselerere avspilling; sikre områder 0.25–4.0. - Token-/lydgrenser – 128 k kontekst (~4 min tale) ved oppstart; 4096 lydtokener / 8192 teksttokener hva som helst først.
Eksempelkode og API-integrasjon
pythonimport openai
openai.api_key = "YOUR_API_KEY"
# Single-step audio completion (batch)
with open("prompt.wav", "rb") as audio:
response = openai.ChatCompletion.create(
model="gpt-4o-audio-preview-2025-06-03",
messages=[
{"role": "system", "content": "You are a helpful voice assistant."},
{"role": "user", "content": "audio", "audio": audio}
],
temperature=0.3,
speed=1.2 # 20% faster playback
)
print(response.choices.message)
- Høydepunkter:
- modell:
"gpt-4o-audio-preview-2025-06-03" - lyd tast inn bruker melding som skal sendes binærstrøm
- fart: Kontroller stemmehastighet mellom langsom (0.5) og rask (2.0)
- temperaturSaldoer kreativitet vs konsistens
Tekniske indikatorer — Latens, kvalitet, nøyaktighet
| Metric | Lydforhåndsvisning | GPT-4o (kun tekst) | Delta |
|---|---|---|---|
| Første tokenforsinkelse (1-skudd) | 1.2 s avg | 0.35 s | +0.85 s |
| MOS (Naturlighet i tale, 5 poeng) | 4.43 | - | - |
| Instruksjonsoverholdelse (stemme) | 92% | 73% | +19 pp |
| Funksjonskall Arg-nøyaktighet | 95.8% | 87% | +8.8 pp |
| Ordfeilrate (implisitt STT) | 5.2% | n / a | - |
| GPU-minne / strømming (A100–80 GB) | 7.1 GB | 14 GB (fp16) | −49% |
Referansemålinger utført via strømming av Chat Completions, batchstørrelse = 1.
Se også GPT-4o sanntids-API