
.png&w=3840&q=75)
GPT-5.4 Mini og GPT-5.4 Nano er OpenAIs nye kompakte varianter av GPT-5.4-frontier-familien: Mini retter seg mot en ledende ytelse/latens-avveining for koding, multimodale UI-oppgaver og subagent-arbeidslaster; Nano retter seg mot ultralave kostnader og lav latens for klassifisering, ekstraksjon, rangering og massivt parallelle subagenter. Mini tilbyr nær frontier-nøyaktighet på mange utviklerbenchmarks samtidig som den kjører >2× raskere enn tidligere mini-varianter; Nano er betydelig billigere per token og ideell der gjennomstrømning og responsivitet betyr mest. Disse modellene er tilgjengelige i API-et (GPT 5.4 Mini og Nano er tilgjengelige i CometAPI).
Hva er GPT-5.4 Mini og GPT-5.4 Nano?
Kort definisjon: GPT-5.4 Mini og GPT-5.4 Nano er kompakte, konstruerte varianter av GPT-5.4-familien, designet for å bringe kjernestyrkene til den store GPT-5.4 (resonnering, koding, multimodal persepsjon, verktøybruk) inn i raskere modeller med lavere kostnad, rettet mot arbeidslaster med høyt volum og lav latens. Modellene ble annonsert av OpenAI som en del av GPT-5.4-lanseringen.
- GPT-5.4 Mini — En kraftig liten modell som «nærmer seg ytelsen til GPT-5.4 på flere evalueringer», samtidig som den er optimalisert for hastighet og lavere kostnad. Den fremheves spesielt for koding, resonnering, multimodal UI-tolkning (skjermbilder) og som subagent i agentiske systemer. OpenAI rapporterer at den kjører mer enn 2× raskere enn tidligere «mini»-varianter.
- GPT-5.4 Nano — Den minste og billigste GPT-5.4-varianten; anbefales for klassifisering, ekstraksjon, rangering og «støttende» subagenter som håndterer smale, repetitive oppgaver med svært høy gjennomstrømning. Den bytter bort dypere resonnering mot lavere latens og kostnadsbesparelser.
Tilgjengelighet og pris
OpenAI gir to konkrete datapunkter du kan bruke for å sammenligne kostnader:
- GPT-5.4 (fullt flaggskip) API-inngangspris: $2.50 / 1M tokens (og høyere utgangsprising på flaggskipet).
- GPT-5.4 mini API-inngangspris: $0.75 / 1M tokens og utgang $4.50 / 1M tokens.
- GPT-5.4 nano API-inngangspris: $0.20 / 1M og utgang $1.25 / 1M.
Satt side om side: minis inngangspris per token (0.75) er 30% av flaggskipets (2.50), altså omtrent en tredjedel av inngangskostnaden; minis utgangspris (4.50) er rundt 32% av en flaggskip-utgangspris sitert i API-pristabellen, altså omtrent en tredjedel også. Nano er enda billigere: inngangskostnaden er rundt 8% av flaggskipets inngangskostnad, og utgangskostnaden er under 10% av flaggskipets utgangskostnad. Disse proporsjonene er nettopp grunnen til at OpenAI omtaler mini/nano som «omtrent en tredjedel» (mini) og «en brøkdel av» (nano) kostnaden ved å bruke de største modellene til oppgaver med høyt volum. Prisen på nano-tokenet steg fra $0.05 til $0.20, og prisen på mini-tokenet steg fra $0.25 til $0.75 (for inngangstokens).
På OpenAI-plattformen
GPT-5.4 mini er tilgjengelig tre steder: OpenAI API, Codex (OpenAIs utvikler-IDE/app-plattform) og ChatGPT (tilgjengelig for Free- og Go-brukere gjennom alternativet «Thinking» og som reserve ved rate-begrensning for betalte nivåer). I API-et støtter den tekst- og bildeinnganger, verktøybruk (function calling), web-/filsøk, datamaskinbruk og ferdigheter — og den tilbyr et svært stort kontekstvindu (400k tokens) for dokumenttunge og arbeidsflyter med flere skjermbilder. Prisen for API-et er $0.75 per 1M inngangstokens og $4.50 per 1M utgangstokens.
GPT-5.4 nano er kun tilgjengelig gjennom API-et. Listeprisene er $0.20 per 1M inngangstokens og $1.25 per 1M utgangstokens — noe som plasserer den som det rimeligste inngangspunktet i GPT-5.4-familien. Nano-modellen bytter bevisst kapasitet mot kostnad og hastighet.
På tredjepartsplattform
CometAPI er en multimodal aggregeringsplattform for AI-API-er som nå har lansert GPT 5.4 Series API, inkludert GPT 5.4 Mini og GPT 5.4 Nano, med 20 % rabatt i forhold til OpenAI-prisen.
GPT 5.4 Nano:
| Comet-pris (USD / M tokens) | Offisiell pris (USD / M tokens) |
|---|---|
| Input:$0.16/M; Output:$1/M | Input:$0.2/M; Output:$1.25/M |
GPT 5.4 Nano:
| Comet-pris (USD / M tokens) | Offisiell pris (USD / M tokens) |
|---|---|
| Input:$0.6/M; Output:$3.6/M | Input:$0.75/M; Output:$4.5/M |
Nøkkelfunksjoner og hva som er nytt
Nedenfor er hovedkapasitetene — hvorfor ingeniører og produktteam vil bry seg.
Koding og støtte for lang kontekst
Kontekstvindu: GPT-5.4 mini støtter et kontekstvindu på 400k tokens (OpenAI oppgir eksplisitt mini med 400k kontekst). Dette er stort nok for kodebaser med flere filer, utvidede dokumenter eller agentøkter over flere runder der kontekst er viktig. Nanos kontekst er mindre enn full GPT-5.4, men fortsatt betydelig for raske, korte oppgaver.
Resonnering
Resonneringsnivåer: OpenAI eksponerer konfigurerbar reasoning_effort (none → xhigh); mini og nano kan kjøre med ulik innsats, men mini reduserer avstanden til full GPT-5.4 på mange resonneringsbenchmarks ved høyere innsats. På flere intelligensbenchmarks (f.eks. GPQA Diamond) oppnår mini 88.0% mot 93.0% for GPT-5.4, og nano får 82.8%, noe som indikerer respektabel resonnering for en liten modell. Dette er resultatene OpenAI publiserte i lanseringsinnlegget sitt.
Multimodal forståelse (syn og UI)
Visuell persepsjon og UI-oppgaver: GPT-5.4 mini viser svært sterk multimodal ytelse på UI-oppgaver (skjermbilder, tette dokumentbilder). På OSWorld-Verified (en benchmark for datamaskinbruk) scorer mini 72.1%, mye nærmere GPT-5.4s 75.0% og langt over tidligere mini-varianter — dette er grunnen til at mini er posisjonert for automatisering drevet av skjermbilder og responsive multimodale assistenter. Nano presterer svakere på visuelle benchmarks, men er fortsatt nyttig for enklere bildeoppgaver.
Verktøykalling og datamaskinbruk
Innebygde verktøy-/klikkmuligheter: GPT-5.4 introduserer og utvider innebygd verktøystøtte for datamaskinbruk; mini arver evnen til å kalle verktøy, gjøre function calls, tolke skjermbilder og orkestrere subagenter. Benchmarks for verktøykall (Toolathlon, MCP Atlas) viser at mini og nano scorer respektabelt (Toolathlon: mini 42.9%, nano 35.5%) — dette kvantifiserer evnen deres til å kalle og koordinere eksterne verktøy. Disse målene er fra OpenAIs kunngjøring.
Hallusinasjon / faktaetterrettelighet / feilrater
OpenAI rapporterer at GPT-5.4 er den «mest faktaetterrettelige modellen så langt» og viser reduksjoner i hallusinasjoner sammenlignet med GPT-5.2; mini og nano viser lavere absolutt faktaetterrettelighet enn fullmodellen (f.eks. HLE m/verktøy: GPT-5.4 52.1%, mini 41.5%, nano 37.7%), noe som tyder på et større behov for verifisering når mindre modeller brukes til oppgaver med høye krav til korrekthet. Bruk verktøybasert verifisering (verktøykall, gjenhenting av sitater) når korrekthet er viktig.
Hastighet
OpenAI rapporterer at GPT-5.4 mini kjører mer enn 2× raskere enn den tidligere GPT-5 mini på typiske estimater for produksjonslatens (disse er basert på simulert produksjonsatferd som inkluderer varighet på verktøykall og samplede tokens). Denne hastighetsøkningen er en sentral påstand for den nye familien og er det som gjør at mini kan brukes som en responsiv subagent i interaktive apper som kodeassistenter.
Hvordan presterer mini og nano — «nærmer» de seg full GPT-5.4?
OpenAI publiserte et omfattende sett med benchmark-sammenligninger på tvers av koding, verktøybruk, multimodale oppgaver for datamaskinbruk, intelligensprøver og evalueringer med lang kontekst. Hovedtallene (xhigh reasoning effort der det er aktuelt) inkluderer:
| Benchmark | GPT-5.4 | GPT-5.4 Mini | GPT-5.4 Nano | GPT-5 Mini (gammel) | Merknader |
|---|---|---|---|---|---|
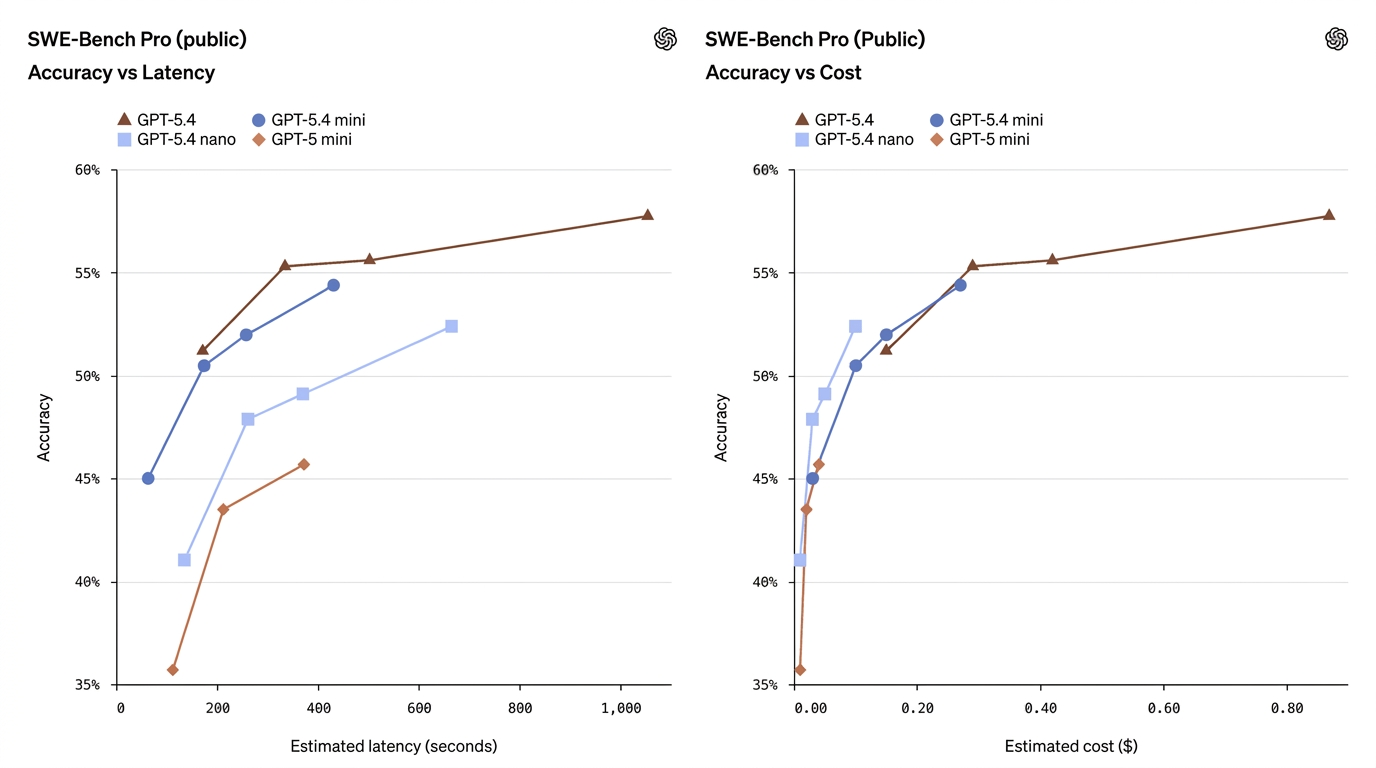
| SWE-Bench Pro (koding) | 57.7% | 54.4% | 52.4% | 45.7% | Mini nærmer seg fullmodellens kodeytelse |
| Terminal-Bench 2.0 (interaktiv koding) | 75.1% | 60.0% | 46.3% | — | Sterk sanntids kodeevne for Mini |
| Toolathlon (verktøybruk) | 54.6% | 42.9% | 35.5% | — | Måler orkestrering og verktøykalling |
| GPQA Diamond (avansert QA) | 93.0% | 88.0% | 82.8% | — | Benchmark for intelligens og resonnering |
| OSWorld-Verified (GUI-oppgaver) | 75.0% | 72.1% | 39.0% | 42.0% | UI-/datamaskinbrukskapasitet |
Disse tallene viser at mini ofte reduserer avstanden betydelig — spesielt på koding og datamaskinbruk — mens nano inntar en nyttig mellomposisjon mellom kapasitet og kostnad.
Hva betyr tallene i klartekst?
- GPT-5.4 Mini ≈ «nesten flaggskip» på mange produksjonsoppgaver. På SWE-Bench Pro (et mål på beståttgrad i koding) scorer mini 54.4% mot flaggskipets 57.7% — et lite relativt gap for mange virkelige kodeoppgaver, spesielt når latens er viktig. På OSWorld (datamaskinbruk) er mini på 72.1% mot flaggskipets 75.0% — igjen svært nær for UI-/skjermbildeoppgaver.
- GPT-5.4 Nano bytter bort mer kapasitet for hastighet/kostnad. Nanos kodingsscore (52.4% på SWE-Bench Pro) er respektabel sammenlignet med eldre mini-varianter, men OSWorld-scoren faller til 39.0%, noe som viser at nano er mindre egnet for oppgaver som krever kompleks, flerstegs UI-forståelse eller agentiske verktøysekvenser. Nano skinner på enkelttur-klassifisering, ekstraksjon og små hjelpeoppgaver.
- Verktøybruk forbedres, men er fortsatt sensitiv. Toolathlon og andre mål på verktøybruk stiger betydelig ved overgang fra GPT-5 mini til GPT-5.4 mini/nano, noe som viser at OpenAIs ingeniørarbeid har forbedret påliteligheten i verktøykalling i de mindre modellene — men fullmodellen leder fortsatt i kompleks verktøyorkestrering.
Hvordan de fungerer i produksjon
Komprimering, destillasjon og ingeniøroptimaliseringer
Kompakte modeller som mini/nano bruker vanligvis en kombinasjon av modell-destillasjon, kvantisering og arkitektonisk pruning for å bevare kapasiteter med høy verdi (kodeheuristikker, visuelle oppfatninger) samtidig som beregningsbehovet ved inferens reduseres. OpenAIs formulering tyder på målrettet ingeniørarbeid for å bevare spesifikke ferdighetssett (koding, multimodal UI-forståelse) i de mindre modellene.
Anbefalte mønstre
- Orkestrator + subagent-mønster: Bruk GPT-5.4 (stor) som planlegger/dommerkraft og send arbeid til GPT-5.4 mini / nano-subagenter for rask utførelse (søk, parsing, redigering). Dette reduserer totale kostnader og senker latensen for brukeren. OpenAI anbefaler eksplisitt dette designmønsteret.
- Fallback og håndtering av rate-begrensning: Eksponer mini som reserve ved rate-begrensning i ChatGPT eller Codex slik at tidssensitive forespørsler fortsatt får et kompetent svar når fullmodellen ikke er tilgjengelig.
- Nivådelt arkitektur for kostnadskontroll: Massepipeliner (indeksering, ekstraksjon) → GPT-5.4 nano; interaktive UI-komponenter → GPT-5.4 mini; endelig redaksjonell vurdering / komplekse kjeder → full GPT-5.4. Denne flernivåtilnærmingen balanserer kostnad og kapasitet.
Latens og parallellisering
Mini og nano er optimalisert for parallelle subagenter, der mange små arbeidere kjører samtidig — f.eks. skanning av tusenvis av PDF-er parallelt. OpenAIs konsept «tool yields» måler hvordan parallelle verktøykall reduserer veggklokkelatens; mini/nano er utviklet for å gjøre slike mønstre kostnadseffektive.
Hvordan ville jeg brukt mini og nano i praksis
Bør jeg erstatte flaggskipkallene mine med mini/nano overalt?
Ikke automatisk. Det riktige mønsteret OpenAI eksplisitt anbefaler, er delegering: bruk en større modell til planlegging, komplekse vurderinger eller endelig verifisering, og send mange støttende, kortere deloppgaver til mini- eller nano-subagenter. Dette mønsteret reduserer kostnad og latens samtidig som den større modellens sikkerhetsmekanismer beholdes der de betyr mest. Bruksområder:
- Interaktive kodeassistenter: flaggskipet planlegger og gjennomgår; mini håndterer raskt kodesøk, redigeringer og korte enhetstester.
- Skjermbildebaserte «computer use»-agenter: mini kan parse tette grensesnitt raskt; flaggskipet løser tvetydig flerstegsplanlegging.
- Pipeliner med høyt volum for ekstraksjon og klassifisering: nano behandler massive batch-inndata (skjemaer, logger) og returnerer strukturerte resultater; flaggskipet håndterer unntak og komplekse kanttilfeller.
Kan mini eller nano brukes til multimodale oppgaver eller bildeoppgaver?
Ja — mini støtter bildeinnganger og presterer godt på multimodale/syndrevne benchmarks (MMMUPro/OmniDocBench), og nærmer seg flaggskipet på enkelte tester. Nanos multimodale styrke er mer begrenset: selv om den forbedrer seg sammenlignet med tidligere nano-varianter, er den ikke det beste valget for dyp multimodal resonnering eller agentiske, bildebaserte oppgaver.
Kappløpet om små modellers kapasiteter har tiltatt
For tre måneder siden ble små modeller ansett som «gode nok». Nå nærmer GPT-5.4 mini seg flaggskipmodeller på benchmarks for programmering og matcher dem nesten i beregningsytelse.
Trenden bak dette er tydelig: kapasitetene til flaggskipmodeller overføres raskt til mindre modeller. OpenAI, Google og Anthropic gjør alle det samme: destillerer kjernekapasitetene til store modeller inn i mindre, raskere og billigere versjoner.
Konklusjon
Lanseringen av disse to modellene markerer et skifte i AI-applikasjoner fra fokus på skala til fokus på praktisk effektivitet. Gjennom raske responsegenskaper gir de mer pålitelig underliggende støtte for sanntids AI-interaksjon og oppdeling av komplekse oppgaveflyter.
For utviklere betyr dette at kostnadsstrukturen til agentsystemer blir redefinert. Når kostnadene faller til dette nivået, blir mange agentscenarier som tidligere var «teoretisk mulige, men økonomisk urealistiske» gjennomførbare.
Utviklere kan få tilgang til GPT 5.4 Mini og GPT-5.4 Nano via CometAPI nå. Før tilgang må du sørge for at du har logget inn på CometAPI og skaffet API-nøkkelen. CometAPI tilbyr en pris som er langt lavere enn den offisielle prisen for å hjelpe deg med integrasjon.
Klar til å sette i gang?