

xAI sluppet stille ut Grok 4.1 (17.–18. november 2025) – en fokusert oppgradering til Grok 4 som prioriterer emosjonell intelligens, kreativ uttrykksevne og redusert hallusinasjon samtidig som den sylskarpe resonnementet fra tidligere Grok-utgivelser beholdes. Den kommer i to moduser (Tenkende / Ikke-tenkende), ble stille rullet ut tidlig i november, viser toppresultater på LMArena og er tilgjengelig via grok.com, Grok-appene og API-et.
Hva er Grok 4.1?
Grok 4.1 er den trinnvise, produksjonsfokuserte etterfølgeren til Grok 4: et familiemedlem bygget på det samme fundamentet for storstilt forsterkningslæring, men finjustert og omtrent med tunge optimaliseringer etter trening rettet mot stil, personlighet, tilpasning og pålitelighet i den virkelige verden. Den posisjoneres som et pragmatisk, «brukbart» skritt fremover: smartere i blinde menneskelige preferansetester, mer emosjonelt intelligent, bedre på kreativ skriving og målbart mindre utsatt for den typen selvsikre, men gale «hallusinasjoner» som har plaget tidligere høypresterende LLM-er.
Grok 4.1 oppnår kvalitative endringer i følgende fire dimensjoner:
- Kreativitet: Demonstrerer sterkere språkstil og fantasi i skriving, historiefortelling og sosiale sammenhenger;
- Emosjonell intelligens: Gjenkjenner tonefall og emosjonelle endringer, reagerer med mer menneskelig emosjonell logikk og genererer trøstende og forståelsesfulle reaksjoner;
- Personlighetskoherens: Opprettholder ensartet tone og personlighet i lange samtaler, og viser ikke lenger den inkonsekvente oppførselen til tidligere modeller;
- Samarbeidende: Opprettholder sammenheng og målbevissthet i dialoger med flere runder eller samarbeid om oppgaver.
xAI oppsummerer dens egenskaper i én setning: «Den er mer oppfattende, mer empatisk og mer som en sammenhengende person.»
Hvordan fungerer Grok 4.1 under panseret?
Grok 4.1 forstås best som den samme forhåndstrente ryggraden som brukes på tvers av Grok 4-familien pluss en lagdelt ettertreningspipeline som fokuserer på belønningsmodellering, stiljustering og agentevaluerere.
Hva er trenings- og tilpasningsfasene?
Grok 4.1 fungerer på en flertrinns rørledning som er typisk for moderne LLM-er i frontier-bransjen, tilpasset med to viktige endringer for 4.1:
- Førtrening + midttrening: Stort forberedende opplæringsgrunnlag for webdata + målrettet mellomopplæring for å styrke domenekunnskap og multimodale ferdigheter.
- Overvåket finjustering (SFT): Menneskelige demonstrasjoner for ønsket atferd (svar, avslagsstrategier).
- Belønningsmodellering (ny anvendelse): xAI-trente belønningsmodeller ikke bare på menneskelige preferanseetiketter, men også brukt Frontier Agent Resonnement Models som belønningsgraderere – som effektivt lar dyktige, modellbaserte evaluatorer vurdere kandidatresultater i stor skala. Dette muliggjorde optimalisering av ikke-verifiserbare attributter som stil, personlig samhold, empati og hjelpsomhet uten å kreve et umulig stort budsjett for menneskelig merking.
- Optimalisering av retningslinjer (RLHF / RL fra modellbelønninger): Standard policyoptimalisering ved bruk av de lærte belønningssignalene for å produsere den distribuerte policyen (modellen forbrukerne samhandler med).
Hva er nytt i belønningsmodelleringsmetoden?
I tradisjonell RLHF samler du inn menneskelige preferanseetiketter (A/B), trener en belønningsmodell for å forutsi disse etikettene, og optimaliserer deretter basismodellen med RL (eller avvisningssampling) mot den lærte belønningen. Men to praktiske innovasjoner fremhever xAI:
- Agentiske belønningsmodeller: I stedet for utelukkende menneskelige dommere, brukte xAI dyktige «agentiske» resonneringsmodeller som poenggivere for å evaluere mer subtile egenskaper (tone, emosjonell nyanse, kreativitet). Vurderingspersonene kan kjøre tusenvis av parvise sammenligninger raskt, slik at ingeniører itererer raskere. Dette er mekanismen for store forbedringer i stil og emosjonell intelligens.
- Justering etter trening for ikke-verifiserbare signaler: For egenskaper du ikke kan måle med en deterministisk målestokk (f.eks. «varme» eller «sammenhengende personlighet») introduserte de spesialiserte belønningsmål og skaleringspensum slik at modellen lærer seg stil av resultater uten at det går på bekostning av sentral faktisk nøyaktighet.
Hvordan fungerer «tenkning» kontra «ikke-tenkning» teknisk sett?
- Grok 4.1 Thinking (kodenavn
quasarflux) — eksponerer eksplisitte resonneringstrinn (tenketokens) før det endelige svaret produseres; optimalisert for komplekse oppgaver og høyere Elo i LMArena. De ekstra tokensene koster inferenstid, men hjelper med flertrinns resonneringsoppgaver, feilsøking og forklaringsevne. - Grok 4.1 Ikke-tenkende (kodenavn
tensor) omgår eksplisitte mellomliggende tokener for en enkelt, umiddelbar endelig respons. Dette reduserer ventetid og tokenkostnader samtidig som den drar nytte av de samme raffinerte policyvektene. Ikke-tenkende modus ble optimalisert for å ha ekstremt lav ventetid og fortsatt svært kapabel.
Optimalisering av justering av sentiment og stil
Utover enkle «sannferdighet»-signaler inkluderer Grok 4.1 målrettet optimalisering av følelser, tonefall og mellommenneskelig stil. Det betyr at treningsprosessen inkluderer belønnings- eller tapskomponenter som eksplisitt straffer uoverensstemmende tonefall (f.eks. å være unødvendig kortfattet når empati er passende) og belønningsresponser som samsvarer med en ønsket stil eller følelsesprofil. I Grok 4.1 introduserte AI først optimaliseringsmålet «Personlighetsjustering».
Den har som mål å hjelpe modellen med å opprettholde en konsistent og stabil følelse av identitet. Sammenlignet med Grok 4, legger 4.1 til følgende til opplæringsmålene:
- Positive belønninger for dimensjonen emosjonelt uttrykk (belønning for emosjonell justering);
- En personlighetskoherensmåling.
Hvordan ble Grok 4.1 evaluert – og hvordan presterte den?
Hva viste blinde menneskelige preferansetester?
Under en stille utrulling ble Grok 4.1 foretrukket 64.78 % av tiden fremfor den forrige produksjonsmodellen i sanntidstrafikk – et sterkt menneskelig preferansesignal som indikerer bedre samtaleresultater i naturen.
Topper Grok 4.1 resultatlistene?
xAI rapporterer at Grok 4.1 tenker modus sitter på #1 på LMArenas tekstarena, med en rapportert Elo av 1483, og dens ikke-resonnerende (raske) modus er rangert som nummer 2 med 1465 Elo – sterke offentlige ledertavleplasseringer for både nøyaktighet og presentasjon (stilkontroll spiller en rolle).
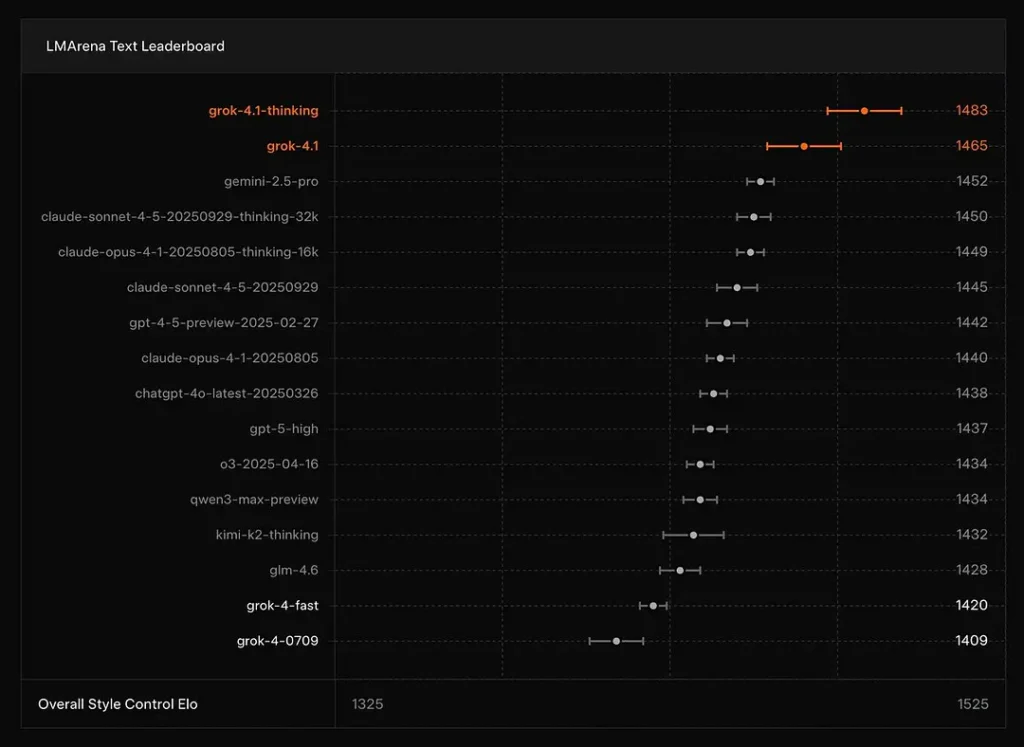
Konklusjon: Grok 4.1 overgår de vanlige GPT-4.5- og Claude-seriene når det gjelder tekstforståelse, generering og generell kvalitet, og er kun overgått av GPT-5 Advanced Preview-versjonen.
Emosjonell intelligens
xAI kjørte EQ-Bench3, en spesialisert test for emosjonell intelligens som dekker 45 utfordrende rollespillscenarioer, og rapporterer at Grok 4.1 viser sterke forbedringer i empati, tempo og mellommenneskelig innsikt. Grok 4.1 scoret høyest på å forstå kontekster av tristhet, empati og trøst.

Kreativ skriving – er det egentlig mer fantasifullt?
Grok 4.1 ble evaluert på Kreativ skriving v3 (32 spørsmål fordelt på 3 iterasjoner med rubrikk + Elo-poengsum). xAI sier at 4.1s skrivestil, stemmekonsistens og narrative kreativitet økte betraktelig, og plasserte den nær toppen av nylige resultatlister for kreative oppgaver (eksempelspørsmål er inkludert i utgivelsen). Uavhengig rapportering speilet disse funnene: anmeldere så betydelig mer "særegen stemme" og bedre sammenheng i lange former. Når det gjelder skrivekvalitet, er Grok 4.1 nest etter GPT-5-serien og overgår hele produktlinjene til Claude, Gemini og Kimi.

Redusert hallusinasjon / ærlighet
xAI hevder en merkbar reduksjon i hallusinasjonsrater: de rapporterte (i kunngjøringen og sosiale innlegg) at Grok 4.1 er ~3 ganger mindre sannsynlighet for å hallusinere Sammenlignet med tidligere Grok-modeller, der man viser til analyser av produksjonstrafikk og evalueringer i FActScore-stil (f.eks. spørsmålssett om biografi/biografi, jo lavere jo bedre). Spesielt i «ikke-resonneringsmodus» der eksterne søkeverktøy er tilgjengelige, er faktaenes konsistens mer stabil.

Hvorfor «knuser» Grok 4.1 andre modeller – er det en overdrivelse?
«Crushes» er markedsføringsaktig, men det ligger objektive påstander bak påstanden:
- Ranglister: Grok 4.1 har topplasseringer på offentlige LMArena-ledertavler for tekstgenerering (1483 Elo for Thinking-modus) og sterke kreative resultater og EQ-bench-resultater per xAI-utgivelsen. Dette er konkurransedyktige målinger som brukes på tvers av fellesskapet.
- Preferanse for reell trafikk vinner: xAI rapporterer at menneskelige preferanser vinner i blinde sammenligninger (~65 % preferanse versus den tidligere produksjonsmodellen) fra en stille utrulling på live-trafikk. Dette gjenspeiler forbedringer fra reelle brukere, ikke bare papirbaserte referansepunkter.
- Praktisk ny funksjon: Kombinasjonen av modellgraderere, RL på ikke-verifiserbare signaler og strengere inputfiltre er et pragmatisk ingeniørtrinn som direkte forbedrer brukeropplevelsen i konversasjons-, empatiske og kreative oppgaver der konkurrenter historisk sett underpresterer.
Så selv om «forelskelser» er en fargerik måte å si «leads» på i flere offentlige og interne evalueringer, bekreftet de underliggende offentlige beregningene som xAI publiserte den konklusjonen.
Slik får du tilgang til Grok 4.1
Forbruker-/apptilgang
xAI har med jevne mellomrom gjort Grok 4.1 tilgjengelig i "Auto"-modus gratis eller som et kampanjevindu, men premiumnivåer (SuperGrok, SuperGrok Heavy) og API-tilgang med høyere kvoter finnes og vedvarer som betalte tilbud.
Grok 4.1 er tilgjengelig for alle brukere on grok.com, X (tidligere Twitter), og iOS- og Android Grok-appene, som rulles ut umiddelbart i Auto-modus, samtidig som de også kan velges eksplisitt som «Grok 4.1» i modellvelgeren.
API-tilgang og utviklerabonnementer
Grok 4.1-endepunkter er tilgjengelige via xAI API. Per publiseringsdatoen for denne artikkelen er det offisielle GPT 4.1 API-et ikke utgitt.
CometAPI lover å holde oversikt over den nyeste modelldynamikken, inkludert Grok 4.1 API, som vil bli utgitt samtidig med den offisielle utgivelsen. Vennligst se frem til den og fortsett å følge med på CometAPI. Mens du venter, kan du følge med på Groks andre modeller, som f.eks. Grok-kode-rask-1 og Grok 4, utforsk mulighetene deres i lekeplassen og se API-veiledningen for detaljerte instruksjoner for å kalle . Før du får tilgang, må du sørge for at du har logget inn på CometAPI og fått API-nøkkelen.
Praktiske tips for bruk av Grok 4.1 i produksjon
Hvordan redusere risikoen for hallusinasjoner
- Aktiver live-søk eller en verifisert verktøykjede for informasjonssøkende spørsmål.
- Oppgi bekreftelsestrinnbe modellen om å returnere kilder og bevis for faktiske påstander; bruk
responsemetadata for å inspisere sitater (hvis tilgjengelig). - Kjør deterministiske kontroller (faktasjekkende LLM-er, strukturerte datavalidatorer) som et etterbehandlingstrinn for resultater med høy innsats.
Hvordan kontrollere tone og stil
- Bruk eksplisitte systemmeldinger for å korrigere stemmen («Du er formell og empatisk.»).
- Bruk overvåkede ledetekster og små lokale maler for konsistent tale på tvers av applikasjoner.
- Der det er tilgjengelig, utnytt xAIs stilkontrollalternativ og belønningsdrevne rattknapper.
Endelig dom: er Grok 4.1 en enorm forandring?
Grok 4.1 er ikke en helt ny arkitektur; snarere er det en sofistikert og gjennomtenkt etter trening / justering utgivelse som fokuserer på hva mennesker faktisk bryr seg om i chatten: personlighet, emosjonell intelligens, kreativitet og færre faktafeilMålbare gevinster på resultattavler, storskala preferanser for reell trafikk og forbedrede sikkerhetsverktøy. For applikasjoner som er avhengige av samtaler av høy kvalitet, kreativt samarbeid eller tonefølsom assistanse, er Grok 4.1 et stort skritt fremover, og i flere fellesskapstester den beste utøveren på utgivelsestidspunktet.
CometAPI er en kommersiell API-aggregeringsplattform som gir utviklere enhetlig REST-tilgang i OpenAI-stil til hundrevis av AI-modeller fra flere leverandører – tekst-LLM-er, bilde-/videogeneratorer, innebygginger og mer – gjennom et enkelt, konsistent grensesnitt. I stedet for å koble separate SDK-er eller skreddersydde endepunkter for OpenAI, Anthropic, Google, Meta eller mindre spesialiserte modellleverandører, lar CometAPI deg kalle forskjellige modeller ved å endre modellstrenger og noen få parametere.
Klar til å prøve? → Registrer deg for CometAPI i dag !
Hvis du vil vite flere tips, guider og nyheter om AI, følg oss på VK, X og Discord!