

Å starte med Gemini 2.5 Flash-Lite via CometAPI gir en spennende mulighet til å utnytte en av de mest kostnadseffektive generative AI-modellene med lav latens som er tilgjengelige i dag. Denne veiledningen kombinerer de siste kunngjøringene fra Google DeepMind, detaljerte spesifikasjoner fra Vertex AI-dokumentasjonen og praktiske integrasjonstrinn ved hjelp av CometAPI for å hjelpe deg med å komme i gang raskt og effektivt.
Hva er Gemini 2.5 Flash-Lite, og hvorfor bør du vurdere det?
Oversikt over Gemini 2.5-familien
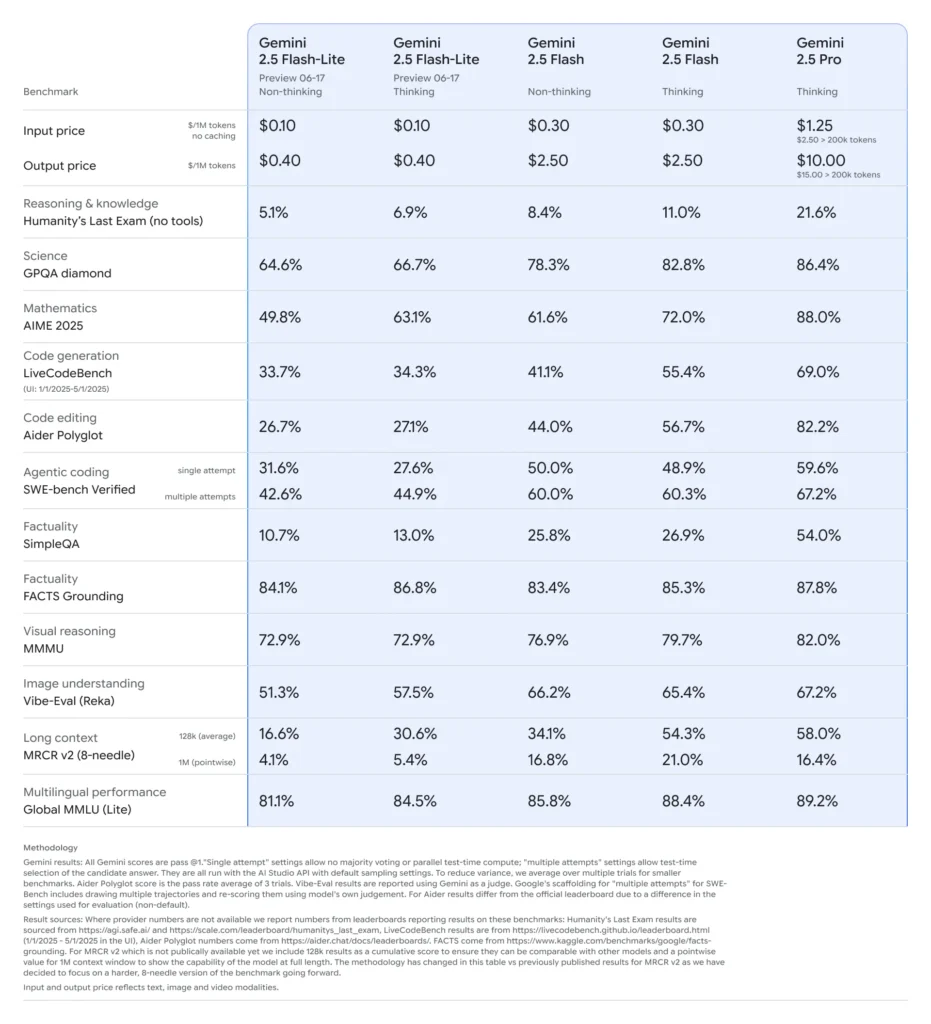
I midten av juni 2025 lanserte Google DeepMind offisielt Gemini 2.5-serien, inkludert stabile GA-versjoner av Gemini 2.5 Pro og Gemini 2.5 Flash, samt forhåndsvisningen av en helt ny, lett modell: Gemini 2.5 Flash-Lite. 2.5-serien er designet for å balansere hastighet, kostnad og ytelse, og representerer Googles satsing på å imøtekomme et bredt spekter av bruksområder – fra tunge forskningsarbeidsmengder til storskala, kostnadssensitive distribusjoner.
Viktige egenskaper ved Flash-Lite
Flash-Lite utmerker seg ved å tilby multimodale funksjoner (tekst, bilder, lyd, video) med ekstremt lav latens, med et kontekstvindu som støtter opptil én million tokens og verktøyintegrasjoner, inkludert Google-søk, kodeutførelse og funksjonskall. Viktigst av alt introduserer Flash-Lite kontroll over «tankebudsjett», som lar utviklere avveie resonnementsdybde mot responstid og kostnad ved å justere en intern parameter for tokenbudsjett.
Posisjonering i modellutvalget
Sammenlignet med sine søsken befinner Flash-Lite seg i Paretos grenseområde når det gjelder kostnadseffektivitet: med en pris på omtrent 0.10 dollar per million input-tokener og 0.40 dollar per million output-tokener under forhåndsvisning, undergraver den både Flash (til 0.30/2.50 dollar) og Pro (til 1.25/10 dollar), samtidig som den beholder mesteparten av deres multimodale ferdigheter og støtte for funksjonskall. Dette gjør Flash-Lite ideell for oppgaver med høyt volum og lav kompleksitet, som oppsummering, klassifisering og lette konversasjonsagenter.
Hvorfor bør utviklere vurdere Gemini 2.5 Flash-Lite?
Ytelsesbenchmarks og tester i den virkelige verden
I direkte sammenligninger demonstrerte Flash-Lite:
- 2 ganger raskere gjennomstrømning enn Gemini 2.5 Flash på klassifiseringsoppgaver.
- 3 ganger kostnadsbesparelser for oppsummeringsrørledninger på bedriftsnivå.
- Konkurransedyktig nøyaktighet på logikk-, matematikk- og kodebenchmarks, som matcher eller overgår tidligere Flash-Lite-forhåndsvisninger.
Ideelle brukstilfeller
- Høyvolum chatboterLever konsistente samtaleopplevelser med lav latens på tvers av millioner av brukere.
- Automatisert innholdsgenereringSkaler dokumentsammendrag, oversettelse og oppretting av mikrokopier.
- Søke- og anbefalingsrørledningerUtnytt rask inferens for personalisering i sanntid.
- Batch-databehandlingAnnotere store datasett med minimale beregningskostnader.
Hvordan får og administrerer man API-tilgang for Gemini 2.5 Flash-Lite via CometAPI?
Hvorfor bruke CometAPI som gateway?
CometAPI samler over 500 AI-modeller – inkludert Googles Gemini-serie – under et enhetlig REST-endepunkt, noe som forenkler autentisering, hastighetsbegrensning og fakturering på tvers av leverandører. I stedet for å sjonglere flere basis-URL-er og API-nøkler, peker du alle forespørsler til https://api.cometapi.com/v1, spesifiser målmodellen i nyttelasten og administrer bruken via ett enkelt dashbord.
Forutsetninger og påmelding
- Logg på cometapi.com. Hvis du ikke er vår bruker ennå, vennligst registrer deg først
- Få tilgangslegitimasjons-API-nøkkelen til grensesnittet. Klikk "Legg til token" ved API-tokenet i det personlige senteret, hent tokennøkkelen: sk-xxxxx og send inn.
- Få url til dette nettstedet: https://api.cometapi.com/
Administrering av tokener og kvoter
CometAPIs dashbord tilbyr enhetlige tokenkvoter som kan deles på tvers av Google, OpenAI, Anthropic og andre modeller. Bruk de innebygde overvåkingsverktøyene til å angi bruksvarsler og hastighetsgrenser, slik at du aldri overskrider budsjetterte tildelinger eller pådrar deg uventede kostnader.
Hvordan konfigurerer du utviklingsmiljøet ditt for CometAPI-integrasjon?
Installere nødvendige avhengigheter
For Python-integrasjon, installer følgende pakker:
pip install openai requests pillow
- openaiKompatibelt SDK for kommunikasjon med CometAPI.
- forespørslerFor HTTP-operasjoner som nedlasting av bilder.
- pute: For bildehåndtering ved sending av multimodale inndata.
Initialiserer CometAPI-klienten
Bruk miljøvariabler for å holde API-nøkkelen din ute av kildekoden:
import os
from openai import OpenAI
client = OpenAI(
base_url="gemini-2.5-flash-lite-preview-06-17",
api_key=os.getenv("COMETAPI_KEY"),
)
Denne klientforekomsten kan nå målrette enhver støttet modell ved å spesifisere ID-en (f.eks. gemini-2.5-flash-lite-preview-06-17) i forespørslene dine.
Konfigurering av tankebudsjett og andre parametere
Når du sender en forespørsel, kan du inkludere valgfrie parametere:
- temperatur/topp_pKontroll over tilfeldighet i generering.
- kandidatantallAntall alternative utganger.
- max_tokens: Utgangstokengrense.
- tankebudsjettTilpasset parameter for Flash-Lite for å avveie dybde mot hastighet og kostnad.
Hvordan ser en grunnleggende forespørsel til Gemini 2.5 Flash-Lite via CometAPI ut?
Eksempel med kun tekst
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=[
{"role": "system", "content": "You are a concise summarizer."},
{"role": "user", "content": "Summarize the latest trends in AI model pricing."}
],
max_tokens=150,
thought_budget=1000,
)
print(response.choices.message.content)
Dette kallet returnerer et kortfattet sammendrag på under 200 ms, ideelt for chatboter eller sanntidsanalysepipeliner.
Eksempel på multimodal input
from PIL import Image
import requests
# Load an image from a URL
img = Image.open(requests.get(
"https://storage.googleapis.com/cloud-samples-data/generative-ai/image/diagram.png",
stream=True
).raw)
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
max_tokens=200,
)
print(response.choices.message.content)
Flash-Lite behandler opptil 7 MB bilder og returnerer kontekstuelle beskrivelser, noe som gjør det egnet for dokumentforståelse, brukergrensesnittanalyse og automatisert rapportering.
Hvordan kan du utnytte avanserte funksjoner som strømming og funksjonskall?
Strømming av svar for sanntidsapplikasjoner
For chatbot-grensesnitt eller direkteteksting, bruk streaming-API-et:
for chunk in client.models.stream_generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
):
print(chunk.choices.delta.content, end="")
Dette leverer delvise utganger etter hvert som de blir tilgjengelige, noe som reduserer opplevd ventetid i interaktive brukergrensesnitt.
Funksjon som kaller for strukturert datautdata
Definer JSON-skjemaer for å håndheve strukturerte svar:
functions = [{
"name": "extract_entities",
"description": "Extract named entities from text.",
"parameters": {
"type": "object",
"properties": {
"entities": {"type": "array", "items": {"type": "string"}},
},
"required":
}
}]
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
functions=functions,
function_call={"name": "extract_entities"},
)
print(response.choices.message.function_call.arguments)
Denne tilnærmingen garanterer JSON-kompatible utdata, noe som forenkler nedstrøms datapipelines og integrasjoner.
Hvordan optimaliserer man ytelse, kostnad og pålitelighet når man bruker Gemini 2.5 Flash-Lite?
Tanke om budsjettjustering
Flash-Lites tankebudsjettparameter lar deg justere mengden «kognitiv innsats» modellen bruker. Et lavt budsjett (f.eks. 0) prioriterer hastighet og kostnad, mens høyere verdier gir dypere resonnering på bekostning av latens og tokens.
Administrering av tokengrenser og gjennomstrømning
- Skriv inn tokensOpptil 1,048,576 XNUMX XNUMX tokens per forespørsel.
- Output tokensStandardgrense på 65,536 XNUMX tokens.
- Multimodale inngangerOpptil 500 MB på tvers av bilde-, lyd- og videoressurser.
Implementer klientsidebatching for arbeidsbelastninger med høyt volum og utnytt CometAPIs automatiske skalering for å håndtere burst-trafikk uten manuell inngripen.
Kostnadseffektivitetsstrategier
- Samle lavkomplekse oppgaver på Flash-Lite, mens du reserverer Pro- eller standard Flash for krevende jobber.
- Bruk prisgrenser og budsjettvarsler i CometAPI-dashbordet for å forhindre uoverkommelige utgifter.
- Overvåk bruken etter modell-ID for å sammenligne kostnader per forespørsel og juster rutingslogikken deretter.
Hva er beste praksis og neste steg etter den første integreringen?
Overvåking, logging og sikkerhet
- LoggingRegistrer metadata for forespørsler/svar (tidsstempler, forsinkelser, tokenbruk) for ytelsesrevisjoner.
- VarslerKonfigurer terskelvarsler for feilrater eller kostnadsoverskridelser i CometAPI.
- TrygghetRoter API-nøkler regelmessig og lagre dem i sikre hvelv eller miljøvariabler.
Vanlige bruksmønstre
- ChatbotsBruk Flash-Lite for raske brukerforespørsler og bruk Pro for komplekse oppfølginger.
- Dokumentbehandling: Lag PDF- eller bildeanalyser i batcher over natten til en lavere budsjettinnstilling.
- Real-time analyticsStrøm økonomiske eller driftsmessige data for umiddelbar innsikt via streaming-API-et.
Utforske videre
- Eksperimenter med hybride prompting-funksjoner: kombiner tekst- og bildeinndata for en rikere kontekst.
- Prototyp RAG (Retrieval-Augmented Generation) ved å integrere vektorsøkeverktøy med Gemini 2.5 Flash-Lite.
- Sammenlign med konkurrenters tilbud (f.eks. GPT-4.1, Claude Sonnet 4) for å validere avveininger mellom kostnad og ytelse.
Skalering i produksjonen
- Utnytt CometAPIs bedriftsnivå for dedikerte kvotepooler og SLA-garantier.
- Implementer blågrønne distribusjonsstrategier for å teste nye ledetekster eller budsjetter uten å forstyrre aktive brukere.
- Gjennomgå regelmessig modellbruksmålinger for å identifisere muligheter for ytterligere kostnadsbesparelser eller kvalitetsforbedringer.
Komme i gang
CometAPI tilbyr et enhetlig REST-grensesnitt som samler hundrevis av AI-modeller – under et konsistent endepunkt, med innebygd API-nøkkeladministrasjon, brukskvoter og faktureringsdashboards. I stedet for å sjonglere flere leverandør-URL-er og legitimasjonsinformasjon.
Utviklere har tilgang Gemini 2.5 Flash-Lite (forhåndsversjon) API(Modell: gemini-2.5-flash-lite-preview-06-17) gjennom CometAPI, de nyeste modellene som er oppført er per artikkelens publiseringsdato. For å begynne, utforsk modellens muligheter i lekeplass og konsulter API-veiledning for detaljerte instruksjoner. Før du får tilgang, må du sørge for at du har logget inn på CometAPI og fått API-nøkkelen. CometAPI tilby en pris som er langt lavere enn den offisielle prisen for å hjelpe deg med å integrere.
Med bare noen få trinn kan du integrere Gemini 2.5 Flash-Lite via CometAPI i applikasjonene dine, og dermed få tilgang til en kraftig kombinasjon av hastighet, overkommelig pris og multimodal intelligens. Ved å følge retningslinjene ovenfor – som dekker oppsett, grunnleggende forespørsler, avanserte funksjoner og optimalisering – vil du være godt posisjonert til å levere neste generasjons AI-opplevelser til brukerne dine. Fremtiden for kostnadseffektiv AI med høy gjennomstrømning er her: kom i gang med Gemini 2.5 Flash-Lite i dag.