

Luma AIs Uni-1 er mer enn en ny tekst-til-bilde-modell. I Lumas egen formulering er den en «multimodal resonneringsmodell som kan generere piksler», bygget på «Unified Intelligence» slik at den kan forstå intensjon, respondere på føringer og «tenke sammen med deg». Selskapets tekniske rapport sier at modellen bruker en autoregressiv transformer med kun dekoder der tekst og bilder representeres i en enkelt sammenflettet sekvens, og at Uni-1 kan utføre strukturert intern resonnering før og under bildesyntese. Denne kombinasjonen er det som gjør Uni-1 til en av de mest interessante bilde-modellutgivelsene i 2026.
Hva er bildemodellen UNI-1?
Uni-1 er Luma AIs nye bildemodell for oppgaver som krever både forståelse og generering i ett system. Luma presenterer den som en multimodal resonneringsmodell snarere enn en klassisk, rent diffusjonsbasert bildemotor, noe som er viktig fordi modellen er ment å gjøre mer enn å produsere visuelt tiltalende utdata: den er designet for å tolke instruksjoner, bevare referansebegrensninger og resonnere gjennom scenelogikk som en del av genereringen. Selskapets tekniske rapport beskriver Uni-1 som deres første forenede forståelses- og genereringsmodell på veien mot multimodal generell intelligens.
Hvorfor Uni-1 er annerledes
Den gamle pipelinen har et tak: bildegenerering uten forståelse kan bare komme et stykke. Uni-1 presenteres som et steg mot «unified intelligence», der språk, persepsjon, fantasi, planlegging og utførelse håndteres i én arkitektur. Dette er mer enn merkevareprat. Uni-1 kan bevege seg fra visuell likhet mot intensjonal komposisjon, plausibilitet og scenelogikk.
Den større historien er at bildemodeller blir mer handlekraftige. Googles nyeste bildestack legger nå vekt på konversasjonsredigering, forankring i søk, flerbilde-fusjon og karakterkonsistens; OpenAIs GPT Image-familie fremhever innebygd multimodalitet og instruksjonsfølging. Uni-1 slutter seg til dette skiftet, men går lenger i ideen om at modellen bør «tenke» på bildet før den tegner det. Det gjør Uni-1 spesielt interessant for arbeidsflyter der presisjon og repeterbarhet er like viktige som visuell stil.
Hvordan fungerer Uni-1 egentlig?
🔬 Tokeniseringsprosess
- Tekst → token-sekvens
- Bilde → tokeniserte bildepatcher
- Kombinert til én sammenflettet sekvens
🔁 Generasjonsprosess
- Inndata: prompt + referanser
- Modellen utfører intern resonnering
- Planlegger komposisjon
- Genererer token sekvensielt
Matematisk: P(x1,...,xn)=∏P(xi∣x1,...,xi−1)P(x_1,...,x_n) = \prod P(x_i | x_1,...,x_{i-1})P(x1,...,xn)=∏P(xi∣x1,...,xi−1)
🧠 Intern resonneringslag
Uni-1:
- Dekomponerer instruksjoner
- Avklarer begrensninger
- Planlegger layout før rendering
👉 Dette er et stort sprang sammenlignet med diffusjonsmodeller.
Autoregressiv generering med kun dekoder
Det viktigste tekniske detaljen er at Uni-1 er autoregressiv snarere enn diffusjonsbasert. Lumas tekniske rapport sier at den er en autoregressiv transformer med kun dekoder, og at tekst og bilder kodes i en enkelt sammenflettet sekvens. Enkelt sagt starter ikke modellen bare fra støy og «avstøyer» gradvis mot et bilde. I stedet genererer den token trinn for trinn, noe som lar modellen resonnere gjennom prompten, løse begrensninger og planlegge komposisjon før og under rendering.
🔬 Tokeniseringsprosess
- Tekst → token-sekvens
- Bilde → tokeniserte bildepatcher
- Kombinert til én sammenflettet sekvens
Diffusjon vs. autoregressiv
| Egenskap | Diffusjonsmodeller | Uni-1 (autoregressiv) |
|---|---|---|
| Generering | Støy → bilde | Token for token |
| Resonnering | Begrenset | Sterk |
| Redigering | Svak | Fleromgang |
| Tekstgjengivelse | Svak | Sterk |
| Kontroll | Lav | Høy |
Kjernearkitektur
Uni-1 er:
- en autoregressiv transformer med kun dekoder
- delt token-rom for tekst + bilder
Denne arkitekturen er viktig fordi den gir modellen en sjanse til å opprettholde sammenheng når prompten er komplisert. Luma sier at Uni-1 kan dekomponere instruksjoner, løse motstridende begrensninger og planlegge bildet før renderingen begynner. Det er spesielt nyttig for oppgaver som strukturert sceneutfylling, plassering av flere subjekter, forfining over flere omganger og redigeringer som krever at output forblir tro mot en referanse samtidig som nye instruksjoner etterleves.
Hva modellen ser ut til å være designet for å gjøre bedre
Å lære å generere bilder forbedrer forståelsen. Luma sier at modellens bildegenereringstrening materiell styrker finmasket visuell forståelse, spesielt av regioner, objekter og layouter. Derfor er Uni-1 ikke en enveis generator, men et forent system der generering og forståelse forsterker hverandre. Inferenzmessig betyr dette at Uni-1 forsøker å lukke gapet mellom «å se» og «å skape». Dette er et stort sprang sammenlignet med diffusjonsmodeller.
Generasjonsprosess:
- Inndata: prompt + referanser
- Modellen utfører intern resonnering
- Planlegger komposisjon
- Genererer token sekvensielt
Matematisk: P(x1,...,xn)=∏P(xi∣x1,...,xi−1)P(x_1,...,x_n) = \prod P(x_i | x_1,...,x_{i-1})P(x1,...,xn)=∏P(xi∣x1,...,xi−1)
Hvilke funksjoner og kjernefordeler tilbyr Uni-1?
Sterk instruksjonsfølge og styrbarhet
Uni-1s sterkeste salgsargument er kontroll. Modellen er bygget for presis redigering, strukturert referansebruk og repeterbare arbeidsflyter. For skapere betyr det mindre prompt-gambling og mer repeterbar output.
En av Uni-1s praktiske fordeler er at den er bygget for kontrollert iterasjon. Seed lar brukere reprodusere resultater, mens referanseroller hjelper modellen å vite om et bilde skal styre karakteridentitet, stemning, palett eller komposisjon. Det gjør Uni-1 enklere å styre enn en rent prompt-drevet modell, spesielt for team som produserer annonser, storyboard, produktmockup-er eller merkevareaktiva der konsistens er viktig.
Referansebasert generering som bevarer identitet
En stor fordel er referansehåndtering. Luma sier eksplisitt at Uni-1 bruker kildeforankrede kontroller og kan bevare identitet, komposisjon og nøkkelvisuelle begrensninger fra én eller flere referanser. Det gjør den attraktiv for kommersielle arbeidsflyter som merkevarefigurer, produktmockup-er, kampanjeaktiva og alle prosjekter der et subjekt må forbli gjenkjennelig på tvers av varianter. Dette er en av de tydeligste måtene Uni-1 skiller seg fra mer rent estetiske bildesystemer.
Kulturell flyt og stilbredde
Luma fremhever også kulturbevisst generering. Deres «Cultured»-seksjon peker på memer, manga, filmatiske uttrykk, hverdagsfoto, sport og dyrebilder, og viser at modellen er ment å operere på tvers av visuelle språk fremfor én generisk stil. Det er viktig fordi en god moderne bildemodell ikke bare trenger å gjengi en realistisk scene; den må også forstå de visuelle konvensjonene i nettkultur, redaksjonell design, stilisert illustrasjon og sosialt innhold.
Multimodal tenkning som designvalg
Den virkelige differensiatoren er ikke bare at Uni-1 genererer bilder, men at Luma rammer inn bildegenerering som en resonneringsoppgave. Uni-1 kan utføre strukturert intern resonnering, og det å lære å generere bilder forbedrer finmasket visuell forståelse av regioner, objekter og layouter. Det antyder en modell som er ment å forstå scenen før den renderes, i stedet for å tilnærme prompten statistisk.
Ytelsesbenchmarks
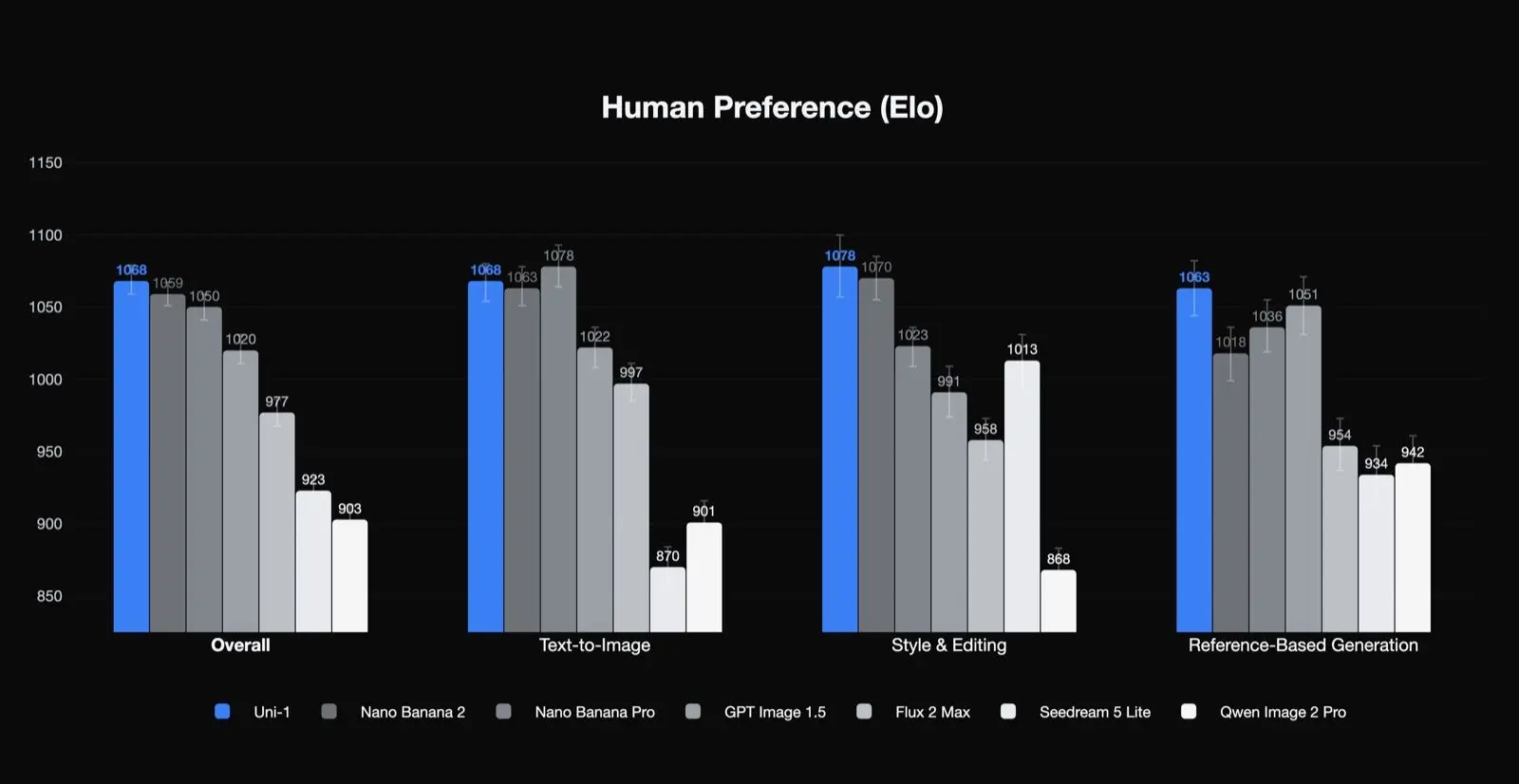
Lumas egne resultater for menneskelig preferanse
Uni-1 rangerer først i menneskelig-preferanse Elo for total kvalitet, stil og redigering og referansebasert generering, og nummer to i tekst-til-bilde. Det er et meningsfullt resultat fordi det antyder at modellen er spesielt sterk i de typene oppgaver som produksjonsteam bryr seg om: redigering, konsistens og styrt transformasjon. Det antyder også at dens beste bruksområder kanskje ikke er ren én-gangs tekst-til-bilde-generering alene.
RISEBench: resonneringsinformert visuell redigering
Den mest oppmerksomhetsvekkende benchmarken er RISEBench, som evaluerer resonneringsinformert visuell redigering på tvers av temporær, kausal, romlig og logisk resonnering. Tredjepartsrapportering om Lumas lansering sier at Uni-1 scorer 0,51 totalt på RISEBench, foran Googles Nano Banana 2 med 0,50, Nano Banana Pro med 0,49 og OpenAIs GPT Image 1,5 med 0,46. På romlig resonnering er Uni-1 rapportert til 0,58 mot Nano Banana 2 på 0,47. På logisk resonnering er Uni-1 rapportert til 0,32, mer enn det dobbelte av GPT Image 1,5s 0,15. Marginene er ikke enorme totalt sett, men de er store i de vanskeligste resonneringskategoriene.

ODinW-13 og påstanden om at «generering forbedrer forståelse»
Uni-1 presterer også sterkt på ODinW-13, en tettdeteksjonsbenchmark med åpent vokabular. Rapportering om Lumas tekniske data sier at fullmodellen scorer 46,2 mAP, nesten på nivå med Googles Gemini 3 Pro på 46,3. Den samme rapporteringen sier at en ren forståelsesvariant scorer 43,9 mAP, noe som impliserer at genereringstrening forbedrer forståelse med 2,3 poeng. Det er et bemerkelsesverdig funn fordi det støtter Lumas kjernepåstand: bildegenerering og bildeforståelse kan være gjensidig forsterkende snarere enn konkurrerende mål.
Pris på Uni-1 API
| Pris for input (tekst) | $0.50 |
|---|---|
| Pris for input (bilder) | $1.20 |
| Pris for output (tekst og tenkning) | $3.00 |
| Pris for output (bilder) | $45.45 |
På forbrukersiden viser Lumas prisside Plus til $30/måned, Pro til $90/måned og Ultra til $300/måned, med gratis prøve-kreditter inkludert i alle planene. Dette betyr at det i praksis er to lag med prising å vurdere: forbrukermedlemskapet for plattformen og modellnivå-API-prisingen for produksjonsbruk.
Foreløpig er CometAPIs Uni-1 API Available Soon, med lovet rabatt ved lansering. For øyeblikket tilbyr CometAPI også utmerkede råbildemodeller, som Midjourney og Nano Banana 2.
Uni-1 vs GPT Image 1.5 vs Nano Banana 2
Uni-1 kontra Googles Nano Banana 2
Nano Banana 2 ser sterkere ut på bredde i referansehåndtering og økosystemintegrasjon. Google vektlegger forankring i bildesøk, konversasjonsbasert iterasjon og referansetunge arbeidsflyter med opptil 14 referanser. Uni-1, derimot, rammes mer eksplisitt inn rundt resonnering, scenepålitelighet og presis redigering i en forent modellarkitektur. I praksis virker Google optimalisert for hastighet, produksjon i mainstream-skala og innebygd Google-forankring; Luma virker optimalisert for strukturert visuell resonnering og styrbar bilderedigering.
I offentlige sammenligninger rundt Uni-1 er avveiingen tydelig: Nano Banana 2 ser ut til å forbli svært sterk for ren tekst-til-bilde-kvalitet og hastighet, mens Uni-1 skyver hardere på resonneringstung redigering, referansekontroll og instruksjonsfidelitet.
Uni-1 kontra OpenAIs GPT Image
I benchmark-rapportering ligger Uni-1 foran GPT Image 1,5 på RISEBench totalt og mer tydelig på logisk resonnering. Sammenlignet med OpenAIs GPT Image-familie er Uni-1 mer snevert og aggressivt posisjonert rundt visuell resonnering og kontrollert redigering. OpenAIs dokumentasjon vektlegger verdenskunskap, multimodal forståelse og kontekstbevissthet; Lumas dokumentasjon vektlegger strukturert intern resonnering, referanseforankret kontroll og benchmarket ferdighet i visuell redigering. Så selv om begge er multimodale, er Uni-1 den mer åpenbare «bilde-spesialistiske resonneringsmodellen», mens GPT Image fremstår mer som et generelt multimodalt system som også genererer bilder svært godt.
Prissammenligning mellom de tre
Når det gjelder prising, avhenger sammenligningen av output-størrelse og produktnivå, så det er ikke helt epler mot epler. Uni-1s publiserte 2048px-ekvivalent er omtrent $0,0909 per bilde. Googles siste prisside for bildemodell oppgir $0,134 per 1K/2K-bilde og $0,24 per 4K-bilde for deres nyeste Gemini image preview, mens OpenAIs GPT Image-priser oppgir per-bilde-priser på $0,011 på lav kvalitet for 1024x1024, $0,042 på medium kvalitet og $0,167 på høy kvalitet, med større utdata av høy kvalitet til $0,25. Med andre ord kan OpenAI være mye billigere i lavenden, Google er aggressiv på hastighet og skala, og Uni-1 lander i midten med en sterk 2K-orientert pris-ytelsesprofil.
Filosofiske forskjeller
| Modell | Tilnærming |
|---|---|
| Uni-1 | Forent multimodal intelligens |
| GPT Image | LLM + bildegenerering |
| Nano Banana 2 | Optimalisert diffusjon for produksjon |
Detaljert sammenligningstabell
| Egenskap | Uni-1 | GPT Image 1.5 | Nano Banana 2 |
|---|---|---|---|
| Arkitektur | Autoregressiv | Hybrid | Diffusjon |
| Multimodal forening | ✅ Innebygd | Delvis | ❌ |
| Resonneringsevne | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ |
| Bildekvalitet | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| Tekstgjengivelse | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐ |
| Redigeringsarbeidsflyter | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ |
| Hastighet | Medium | Rask | Rask |
| Kontroll | Høy | Middels | Middels |
CometAPI tilbyr interaktive råbilder for GPT Image 1.5, Nano Banana 2, og den kommende Uni-1, samt API-programmering. Rabatterte priser og betaling etter forbruk gjør den til et foretrukket valg for utviklere.
Hva Uni-1 egner seg best til
Uni-1 virker spesielt sterk for tilfeller der du trenger repeterbarhet, karakterkonsistens eller kontroll med flere referanser. Det inkluderer merkevarekampanjer, produktmockup-er, redaksjonelle konsepter, storyboard, lokaliseringsvarianter og bilderedigeringer der komposisjonen må forbli intakt, men stil eller miljø bør endres. Lumas egne eksempler lener seg tungt mot disse bruksområdene, og modellens «Create vs Modify»-deling er i praksis et direkte svar på vanlige produksjonssmertepunkter.
Hvis arbeidet ditt stort sett er «lag noe pent fra én enkelt prompt», vil differensieringen kanskje føles mindre dramatisk. Men hvis arbeidsflyten din er «lag fem beslektede versjoner, behold samme karakter, bevar innrammingen, endre lyssettingen, og gjør det reproducerbart neste uke», begynner Uni-1s design å gi mye mening. Det er en slutning, men den følger naturlig av kontrollfunksjonene Luma fremhever.
Beste praksis for å få bedre resultater med Uni-1
Start med å bruke riktig modus. Lumas veiledning er enkel: Create når du vil ha en ny scene, Modify når du vil bevare en eksisterende. Å blande disse intensjonene gjør utdata mer ustødige.
Bruk referanseetiketter som en profesjonell. Luma anbefaler fraser som «Bruk IMAGE1 som en STIL-referanse» eller «Bruk IMAGE2 som LYSSETTING». Modellen gjør det bedre når hver referanse har en oppgave, i stedet for vag «inspirasjon».
Lås seed når du finner noe bra. Luma anbefaler eksplisitt å utforske uten seed først, deretter lagre seed når du har et sterkt resultat. Etter det, endre én variabel om gangen. Det er den enkleste måten å gjøre generering om til et kontrollert produksjonssystem.
Vær spesifikk og konkret. Luma advarer mot vage ord som «vakker» eller «fantastisk», og oppmuntrer i stedet til navngitte estetikk som «italiensk giallo-filmplakat fra 1970-tallet» eller eksakte kamerastil-ledetråder. I praksis slår spesifikke prompt vanligvis poetiske prompt fordi modellen kan forankre seg i reell struktur.
Bruk Create → Modify-kjeden. Luma sier eksplisitt at dette er en av de kraftigste arbeidsflytene deres: utforsk i Create, og raffiner i Modify. Det er sweet spot for seriøst produksjonsarbeid, fordi det reduserer tilbakehopp og bevarer de gode delene av en komposisjon mens detaljene strammes til.
Endelig vurdering
Uni-1 er Lumas tydeligste erklæring til nå om at bildegenerering beveger seg fra «prompt inn, bilde ut» mot resonneringsstyrt visuell skapelse. Dens offentlige styrker er kontroll, referansehåndtering, reproduserbarhet og en modellarkitektur som holder språk og piksler i samme system.
For skapere og team som bryr seg om høyklikk visuelle utdata, konsistente karakterer, presise redigeringer og klar prising for høy oppløsning, er Uni-1 absolutt en modell å følge med på. Hvis API-utrullingen lander godt, kan den bli et av de mest interessante alternativene til Googles Nano Banana 2 og OpenAIs GPT Image 1,5 i 2026.
Planlegger du å begynne å lage råbilder? CometAPI, en alt-i-ett aggregeringsplattform for multimodale modell-API-er, ønsker deg velkommen!