Gemini 2.5 Flash er konstruert for å levere raske svar uten å gå på bekostning av kvaliteten på resultatene. Den støtter multimodale inndata, inkludert tekst, bilder, lyd og video, noe som gjør den egnet for et bredt spekter av bruksområder. Modellen er tilgjengelig via plattformer som Google AI Studio og Vertex AI, og gir utviklere verktøyene som trengs for sømløs integrasjon i ulike systemer.
Grunnleggende informasjon (funksjoner)
Gemini 2.5 Flash introduserer flere fremtredende funksjoner som skiller den fra resten av Gemini 2.5-familien:
- Hybrid resonnering: Utviklere kan angi parameteren thinking_budget for finstyring av hvor mange tokens modellen bruker på intern resonnering før output.
- Pareto-fronten: Plassert på det optimale kost-ytelsespunktet, tilbyr Flash det beste forholdet mellom pris og intelligens blant 2.5-modellene.
- Multimodal støtte: Behandler tekst, bilder, video og lyd nativt, noe som muliggjør rikere samtaler og analytiske evner.
- Kontekst på 1 million tokens: Uovertruffen kontekstlengde gir dyp analyse og forståelse av lange dokumenter i én forespørsel.
Modellversjonering
Gemini 2.5 Flash har gjennomgått følgende viktige versjoner:
- gemini-2.5-flash-lite-preview-09-2025: Forbedret verktøybrukervennlighet: Bedre ytelse på komplekse oppgaver i flere trinn, med en 5% økning i SWE-Bench Verified-score (fra 48.9% til 54%). Forbedret effektivitet: Når resonnering aktiveres, oppnås høyere kvalitet med færre tokens, noe som reduserer ventetid og kostnader.
- Preview 04-17: Tidlig tilgang med “thinking”-kapabilitet, tilgjengelig via gemini-2.5-flash-preview-04-17.
- Stabil generell tilgjengelighet (GA): Fra og med 17. juni 2025 erstatter den stabile endepunkten gemini-2.5-flash forhåndsvisningen og sikrer produksjonsklar pålitelighet uten API-endringer fra forhåndsvisningen 20. mai.
- Avvikling av forhåndsvisning: Forhåndsvisningsendepunkter var planlagt stengt 15. juli 2025; brukere må migrere til GA-endepunktet før denne datoen.
Fra juli 2025 er Gemini 2.5 Flash nå offentlig tilgjengelig og stabil (ingen endringer fra gemini-2.5-flash-preview-05-20). Hvis du bruker gemini-2.5-flash-preview-04-17, vil eksisterende forhåndsvisningspriser fortsette frem til den planlagte avviklingen av modellendepunktet 15. juli 2025, når det blir stengt. Du kan migrere til den generelt tilgjengelige modellen "gemini-2.5-flash".
Raskere, billigere, smartere:
- Designmål: lav ventetid + høy gjennomstrømning + lav kostnad;
- Overordnet hastighetsøkning i resonnering, multimodal behandling og oppgaver med lange tekster;
- Token-bruken reduseres med 20–30%, noe som reduserer resonnementskostnader betydelig.
Tekniske spesifikasjoner
Inndatavindu for kontekst: Opptil 1 million tokens, som muliggjør omfattende kontekstbevaring.
Utgående tokens: Kan generere opptil 8,192 tokens per svar.
Støttede modaliteter: Tekst, bilder, lyd og video.
Integrasjonsplattformer: Tilgjengelig via Google AI Studio og Vertex AI.
Prising: Konkurransedyktig token-basert prismodell som muliggjør kostnadseffektiv utrulling.
Tekniske detaljer
Under panseret er Gemini 2.5 Flash en transformer-basert stor språkmodell trent på en blanding av nett-, kode-, bilde- og videodata. Viktige tekniske spesifikasjoner inkluderer:
Multimodal opplæring: Trenet til å samordne flere modaliteter; Flash kan sømløst blande tekst med bilder, video eller lyd, nyttig for oppgaver som videosammendrag eller lydteksting.
Dynamisk tankeprosess: Implementerer en intern resoneringssløyfe der modellen planlegger og bryter ned komplekse prompter før endelig output.
Konfigurerbare tenkebudsjetter: thinking_budget kan settes fra 0 (ingen resonnering) opp til 24,576 tokens, som muliggjør avveininger mellom ventetid og svarkvalitet.
Verktøyintegrasjon: Støtter Grounding with Google Search, Code Execution, URL Context og Function Calling, som muliggjør reelle handlinger direkte fra naturlige språkforespørsler.
Referanseytelse
I strenge evalueringer demonstrerer Gemini 2.5 Flash bransjeledende ytelse:
- LMArena Hard Prompts: Skåret kun slått av 2.5 Pro på den krevende Hard Prompts-benchmarket, og viser sterk resonnering i flere steg.
- MMLU-score på 0.809: Overgår gjennomsnittlige modeller med 0.809 i MMLU-nøyaktighet, noe som reflekterer bred domeneekspertise og resoneringsstyrke.
- Ventetid og gjennomstrømning: Oppnår 271.4 tokens/sec dekodingshastighet med 0.29 s Time-to-First-Token, ideelt for arbeidslaster som er sensitive for ventetid.
- Leder på pris-til-ytelse: Med $0.26/1 M tokens underbyr Flash mange konkurrenter samtidig som den matcher eller overgår dem på nøkkelbenchmarker.
Disse resultatene indikerer Gemini 2.5 Flashs konkurransefortrinn innen resonnering, vitenskapelig forståelse, matematisk problemløsing, koding, visuell tolkning og flerspråklige evner:
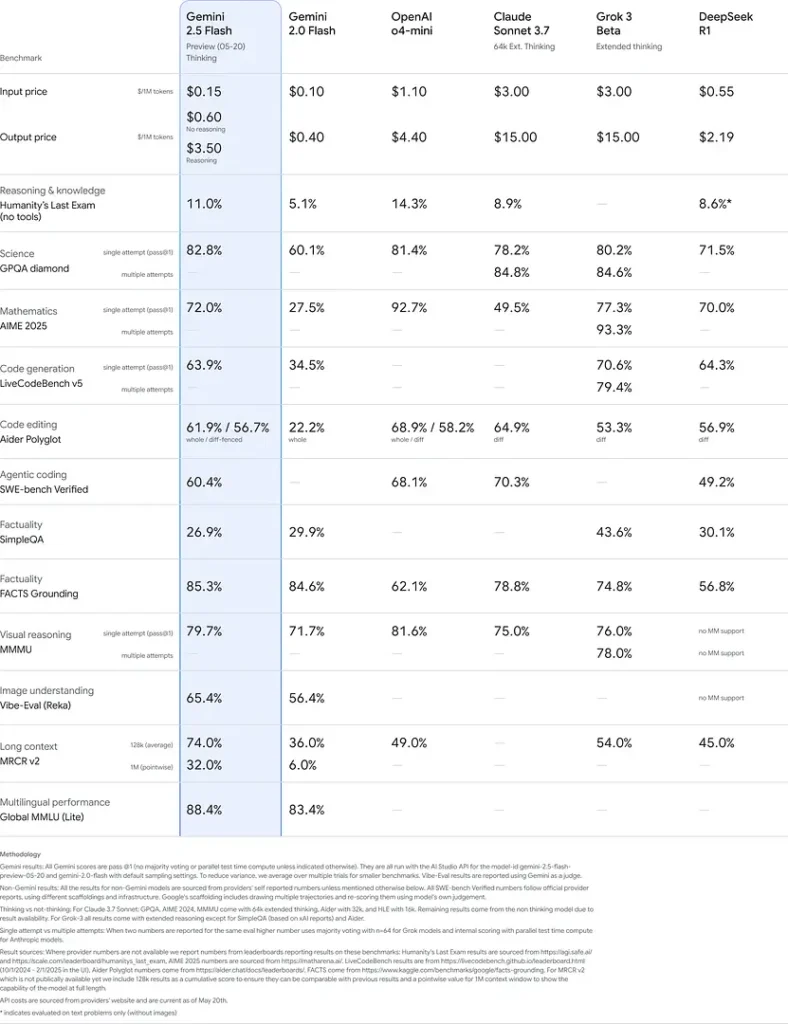
Begrensninger
Selv om den er kraftig, har Gemini 2.5 Flash noen begrensninger:
- Sikkerhetsrisikoer: Modellen kan ha en belærende tone og kan produsere tilforlatelige, men feilaktige eller partiske svar (hallusinasjoner), særlig ved kanttilfeller. Streng menneskelig kontroll er fortsatt avgjørende.
- Rate limits: API-bruk er begrenset av rate limits (10 RPM, 250,000 TPM, 250 RPD) som kan påvirke batch-prosessering eller høye volumer.
- Nedre intelligensgrense: Selv om den er usedvanlig kapabel for en flash-modell, er den mindre nøyaktig enn 2.5 Pro på de mest krevende agentbaserte oppgavene som avansert koding eller multi-agent-koordinering.
- Kostnadsavveininger: Selv om den tilbyr best pris-ytelse, vil utstrakt bruk av thinking-modus øke det totale token-forbruket og dermed kostnadene for forespørsler som krever dypere resonnement.