Tekniske detaljer
- Adaptiv resonnering:
Gemini 2.5 Flash-Litestøtter tenkning ved behov, slik at utviklere kan tildele datakraft bare når dypere resonnering er nødvendig. - Verktøyintegrasjoner: Full kompatibilitet med Gemini 2.5s innebygde verktøy, inkludert Grounding with Google Search, Code Execution, URL Context og Function Calling for sømløse multimodale arbeidsflyter.
- Model Context Protocol (MCP): Utnytter Googles MCP for å hente sanntidsdata fra nettet, og sikrer at svarene er oppdaterte og kontekstuelt relevante.
- Distribusjonsalternativer: Tilgjengelig gjennom CometAPI, Gemini API, Vertex AI og Google AI Studio, med et forhåndsvisningsspor for tidlige brukere som vil eksperimentere og gi tilbakemeldinger.
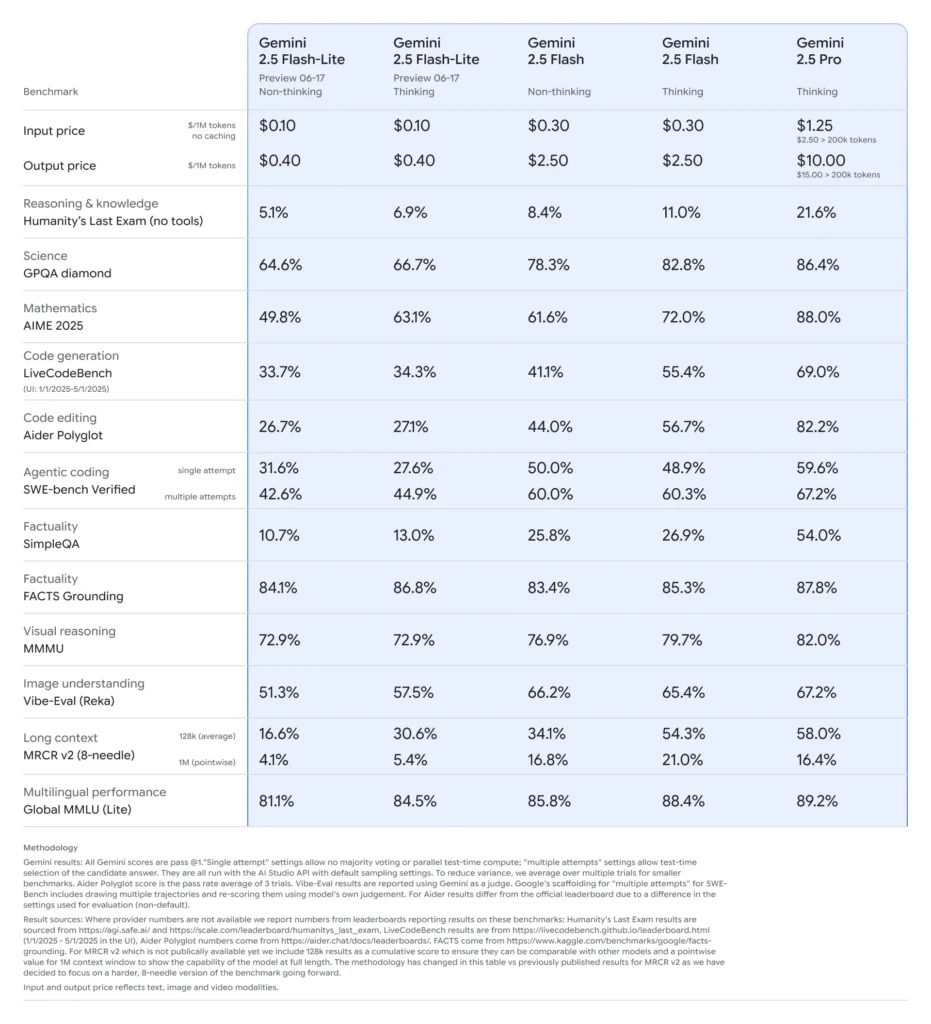
Referanseytelse for Gemini 2.5 Flash-Lite
- Forsinkelse (latency): Oppnår opptil 50% lavere median svartider sammenlignet med Gemini 2.5 Flash, med typisk under 100 ms latens på standard klassifiserings- og oppsummeringsbenchmarker.
- Gjennomstrømning: Optimalisert for høyvolums arbeidsbelastninger, opprettholder titusenvis av forespørsler per minutt uten ytelsesforringelse.
- Pris-ytelse: Viser 25% reduksjon i kostnad per 1,000 tokens sammenlignet med Flash-motstykket, og er dermed det Pareto-optimale valget for kostnadssensitive utrullinger.
- Bransjeadopsjon: Tidlige brukere rapporterer sømløs integrasjon i produksjonspipelines, med ytelsesmetricer som samsvarer med eller overgår de første prognosene.
Ideelle bruksområder
- Høyfrekvente, lavkompleksitetsoppgaver: Automatisk merking, sentimentanalyse og masseoversettelse
- Kostnadssensitive pipeliner: Datauttrekk fra store dokumentkorpora, periodisk batch-oppsummering
- Edge- og mobilsituasjoner: Når latens er kritisk, men ressursbudsjettene er begrenset
Begrensninger ved Gemini 2.5 Flash-Lite
- Forhåndsvisningsstatus: Kan gjennomgå API-endringer før GA; integrasjoner bør ta høyde for mulige versjonsøkninger.
- Ingen finjustering underveis: Kan ikke laste opp egendefinerte vekter; stol på prompt engineering og systemmeldinger.
- Redusert kreativitet: Tunet for deterministiske oppgaver med høy gjennomstrømning; mindre egnet for åpen generering eller «kreativ» skriving.
- Ressurstak: Skalerer lineært bare opp til ~16 vCPUs; utover dette avtar gjennomstrømningsgevinstene.
- Multimodale begrensninger: Støtter bilde-/lydinndata, men med begrenset kvalitet; ikke ideelt for tunge visjons- eller lydtranskripsjonsoppgaver.
- Avveiing for kontekstvindu: Selv om det aksepterer opptil 1 M tokens, kan praktisk inferens i den skalaen gi redusert gjennomstrømning.