

Wan2.7-Image firmy Alibaba, wydany 1 kwietnia 2026 r., stanowi znaczący krok naprzód w generowaniu wizualnym AI. Ten ujednolicony model łączy w jednej architekturze generowanie obrazu z tekstu, interaktywną edycję, kompozycję z wielu obrazów oraz rozumienie semantyczne. W przeciwieństwie do tradycyjnych, rozdzielonych potoków dla generowania i edycji eliminuje niespójności, takie jak „zestandaryzowane twarze AI”, zniekształcony tekst i nieprzewidywalne kolory.
Twórcy, projektanci, marketerzy i przedsiębiorstwa uzyskują teraz fotorealistyczne, ściśle zgodne z poleceniami rezultaty przy mniejszej liczbie iteracji. Model obsługuje do 12 sekwencyjnych obrazów, 9 fuzji referencyjnych, renderowanie tekstu w 12 językach (do 3,000 tokenów) oraz kontrolę na poziomie piksela.
Czym jest Wan2.7-Image?
Wan2.7-Image to flagowy, ujednolicony model obrazowy laboratorium Tongyi Lab firmy Alibaba w serii Wan (Tongyi Wanxiang). Obsługuje kompleksowe przepływy pracy wizyjne: generowanie tekst-do-obrazu, przekształcanie obrazu w obraz, edycję opartą na poleceniach oraz interaktywne dopracowania na poziomie piksela — wszystko w jednej, współdzielonej przestrzeni utajonej.
Wydany 1 kwietnia 2026 r., bazuje na wcześniejszych modelach wideo Wan 2.x (które zajmowały czołowe miejsca w benchmarkach VBench), przenosząc nacisk na precyzję obrazu. Bezpośrednio rozprawia się z „zmęczeniem estetyką” wynikającym z powtarzalnych twarzy, niestabilnych kolorów i słabej zgodności z poleceniami, częstych w starszych narzędziach AI. Rodzina modeli obejmuje dwie nazwy najistotniejsze dla użytkowników: wan2.7-image oraz wan2.7-image-pro. Wersja standardowa jest dostrojona pod szybsze generowanie, podczas gdy wersja Pro jest skierowana do zastosowań profesjonalnych, z obsługą 4K w wysokiej rozdzielczości.
Kluczowy wyróżnik: ujednolicona architektura. Tradycyjne modele używają rozłącznych etapów (enkoder → dyfuzja → dekoder), wymagając osobnego inpaintingu do edycji. Wan2.7-Image odwzorowuje semantykę bezpośrednio we współdzielonej przestrzeni, co umożliwia prawdziwe rozumienie zamiast dopasowywania wzorców pikseli.
Dlaczego Wan2.7-Image ma znaczenie (kontekst branżowy)
Tradycyjne narzędzia AI do obrazów cierpią na:
| Problem | Wyjaśnienie |
|---|---|
| Fragmentaryczny przepływ pracy | Oddzielne narzędzia do generowania, edycji, inpaintingu |
| „Syndrom twarzy AI” | Powtarzalne, nierealistyczne twarze |
| Słaba zgodność z poleceniami | Polecenia nie są dokładnie realizowane |
| Słabe renderowanie tekstu | Zniekształcony lub nieczytelny tekst |
| Niespójny wynik w wielu obrazach | Postacie zmieniają się między klatkami |
Wan2.7-Image bezpośrednio rozwiązuje te ograniczenia dzięki ujednoliconej architekturze + warstwie rozumienia semantycznego.
5 kluczowych funkcji Wan2.7-Image
1. Dostosowywanie awatarów na poziomie kośćca dla naprawdę unikalnych twarzy
Wan2.7-Image doskonale radzi sobie z zasadą „unikalna twarz dla każdej osoby”. Zapewnia drobiazgową kontrolę nad budową kośćca, kształtem oczu (migdałowe, feniksowe, głęboko osadzone, opuchnięte, uśmiechnięte), konturami twarzy i subtelnymi detalami. To eliminuje problem „zestandaryzowanych twarzy AI”, który nękał wcześniejsze modele.

Przykładowa podpowiedź: „Fotorealistyczny portret 28-letniej kobiety pochodzenia wschodnioazjatyckiego, owalna twarz, migdałowe oczy, subtelny uśmiech, szczegółowa tekstura skóry, naturalne oświetlenie.” Wyniki pokazują życiopodobną różnorodność — idealne dla wirtualnych influencerów, NPC w grach lub spersonalizowanego brandingu.
2. Precyzyjna kontrola palety kolorów
Jedną z najbardziej praktycznych funkcji jest nowa kontrola palety kolorów. Alibaba informuje, że użytkownicy mogą wprowadzać konkretne kody kolorów i proporcje, aby odtworzyć style artystyczne lub zablokować barwy marki. Dokumentacja API formalizuje to poprzez parametr color_palette, który przyjmuje od 3 do 10 kolorów (zalecane 8). Dla zespołów brandowych to jedna z najbardziej klarownych, zorientowanych na przedsiębiorstwa funkcji w tym wydaniu. Koniec z losowymi zmianami kolorów — pełna spójność w całych kampaniach.
Oficjalny cytat: „Pożegnaj losowe generowanie kolorów. Osiągnij precyzyjne proporcje barw i urzeczywistnij swoją wizję kreatywną.” — Tongyi Wanxiang.
3. Zaawansowane wielojęzyczne renderowanie tekstu (12 języków, 3,000 tokenów)
Renderuj bardzo długie teksty, tabele, wzory, wykresy i infografiki z jakością druku (odpowiednik A4). Obsługa chińskiego, angielskiego, japońskiego, koreańskiego i jeszcze 8 języków. Artykuły naukowe, plakaty, etykiety produktów i wielojęzyczne banery osiągają niemal perfekcyjną czytelność — to odpowiedź na historyczną słabość narzędzi AI.
4. Interaktywna edycja z dokładnością do piksela z zaznaczaniem prostokątnym
Używaj ramek ograniczających (editRegions) lub narzędzia zaznaczania do ukierunkowanych zmian. Prześlij do 9 obrazów referencyjnych i wydaj polecenia typu „zmień tło na plażowy zachód słońca, zachowując twarz, pozę i odzież”. Dokładność na poziomie piksela zapewnia zachowanie tożsamości.
5. Kompozycyjne generowanie z wielu obrazów (do 12 obrazów sekwencyjnych)
Model zaprojektowano do czegoś więcej niż jednopromptowe generowanie. Alibaba podaje, że można pracować z maksymalnie dziewięcioma obrazami referencyjnymi i generować do 12 obrazów jednocześnie, co idealnie sprawdza się przy spójnych storyboardach, w architekturze i w seriach e-commerce. Przepływ „kliknij, aby edytować” pozwala wybierać konkretne obszary i wprowadzać zmiany z dokładnością do piksela, a dokumentacja API dodaje interaktywną precyzyjną edycję poprzez parametr bounding-box do lokalnych zmian.
Jak działa Wan2.7-Image? (dogłębna analiza techniczna)
Alibaba opisuje Wan2.7-Image jako framework łączący język i wizualia poprzez trening na dużych, zróżnicowanych zbiorach danych. W prostych słowach: model nie tylko uczy się „rysować” obrazy; uczy się również, jak mapować polecenia na strukturę wizualną, kompozycję, oświetlenie i rozmieszczenie tekstu. Dzięki temu lepiej interpretuje intencje użytkownika niż podstawowy system tekst-do-obrazu.
API pokazuje także, że model jest zbudowany pod kątem wejścia multimodalnego. W praktyce żądania są wysyłane w strukturze pojedynczej tury, a treść może obejmować zarówno elementy tekstowe, jak i obrazowe. W edycji użytkownicy mogą przekazać wiele obrazów oraz instrukcje takie jak „przesuń”, „zamień” lub „połącz”, aby ukierunkować wynik. To wyraźny znak, że Wan2.7 zaprojektowano jako system oparty na promptach i referencjach, a nie prosty generator jednorazowy.
Dokumentacja ujawnia także ustawienie trybu myślenia. Domyślnie włączone i poprawia jakość wyników, ale Alibaba zaznacza, że zwiększa czas generowania. To cenna wskazówka co do przepływu pracy modelu: wyższa jakość może wymagać więcej wewnętrnego czasu inferencji, zwłaszcza przy żądaniach złożonych wizualnie lub obszernych tekstowo.
Wan2.7-Image stosuje ujednolicony framework generowania i edycji we współdzielonej przestrzeni utajonej:
- Etap wejściowy: Tekstowy prompt (do 3,000 tokenów) + opcjonalne obrazy referencyjne (do 9).
- Parsowanie semantyczne i Tryb myślenia (wzmocniony w Pro): rozumowanie łańcuchowe analizuje kompozycję, relacje przestrzenne, oświetlenie i logikę, zanim dojdzie do generowania pikseli.
- Mapowanie do współdzielonej przestrzeni utajonej: Semantyka jest bezpośrednio mapowana na cechy wizualne — bez rozłączonych luk enkodera/dekodera.
- Ujednolicone wnioskowanie: Generowanie lub edycja przebiegają w jednym zoptymalizowanym przepływie. Regiony edycji definiowane są przez ramki; palety kolorów wymuszają proporcje.
- Wyjście: Obrazy o wysokiej wierności (standard 768–2048×2048; 4K w Pro), z opcjami JPG/PNG/WEBP, seedami dla powtarzalności i kontrolami bezpieczeństwa.
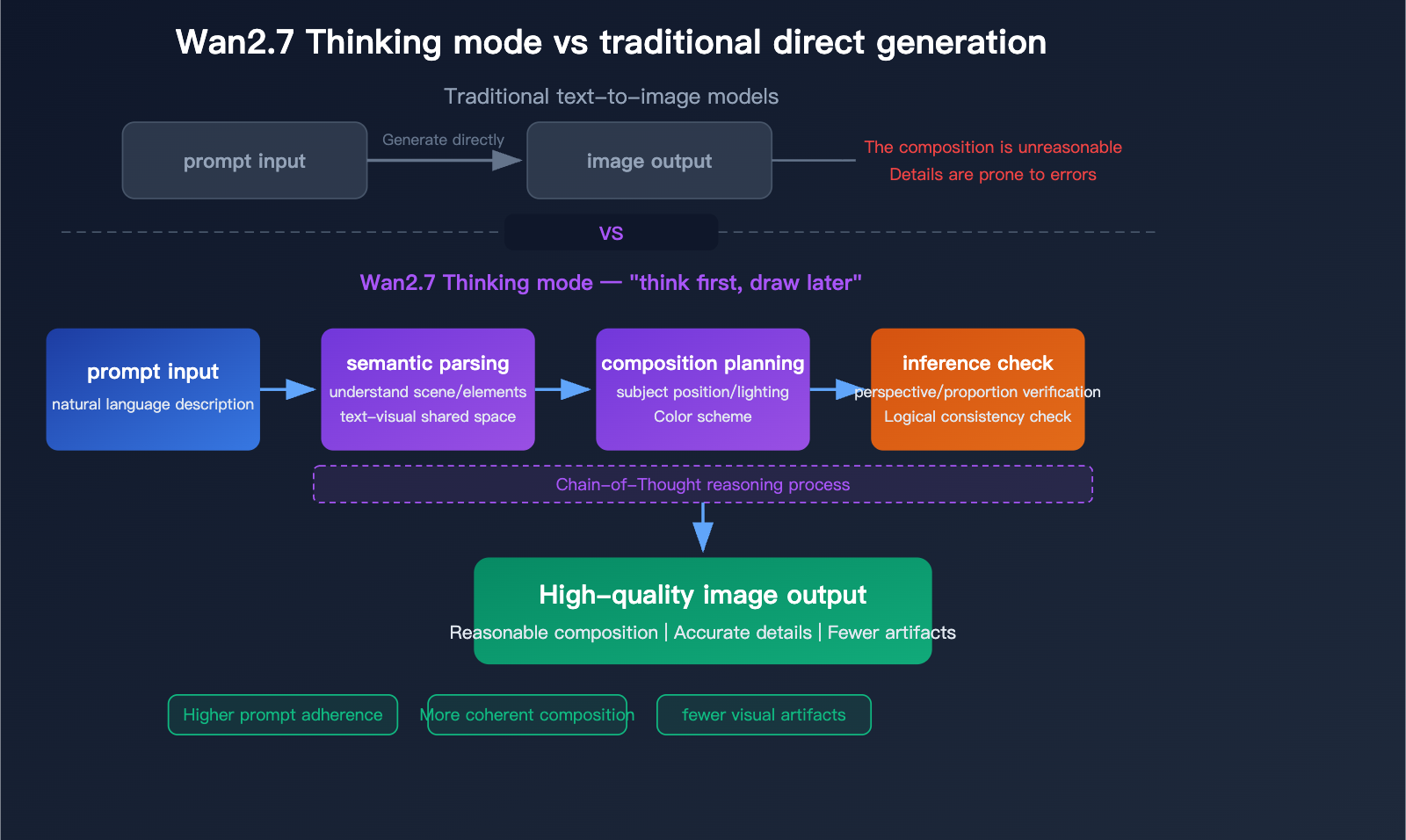
Dogłębna analiza Wan2.7-Image-Pro: nowy punkt odniesienia dla generowania obrazów przez AI z jakością 4K, trybem rozumowania i renderowaniem tekstu w 12 językach — Apiyi.com Blog
Schemat przepływu trybu myślenia (Pro) pokazuje parsowanie semantyczne → planowanie kompozycji → kontrolę inferencji, co daje mniej artefaktów i wyższą zgodność z poleceniami w porównaniu z bezpośrednim generowaniem.
Trening na zróżnicowanych zbiorach danych umożliwia głębokie rozumienie intencji, oświetlenia i układów. Uczenie z długim kontekstem (wspominane w pracach na arXiv) napędza obsługę długich tekstów.
Wan2.7-Image vs Wan2.7-Image-Pro: najważniejsze różnice
Obie wersje startują równocześnie, ale Pro celuje w potrzeby profesjonalne.
| Funkcja | Wan2.7-Image (Standard) | Wan2.7-Image-Pro | Najlepsze zastosowanie |
|---|---|---|---|
| Maks. rozdzielczość | 2048×2048 | 4096×4096 (4K) | Druk/produkcja (Pro) |
| Tryb myślenia | Dostępny (szybsze ustawienie domyślne) | Ulepszony/domyślny z głębszym rozumowaniem | Złożone sceny (Pro) |
| Stabilność kompozycji | Wysoka | Ponadprzeciętne rozumienie semantyczne | Projekty komercyjne (Pro) |
| Szybkość vs jakość | Szybsze iteracje | Wyższa wierność, nieco dłuższy czas | Prototypowanie (Standard) |
| Zastosowanie | Twórcy ogólni, treści społecznościowe | Projekty korporacyjne, akademickie/druk | Skalowalność vs precyzja |
Standard nadaje się do szybkiego prototypowania; Pro dostarcza gotowe do druku 4K z lepszą spójnością.
Jak korzystać z Wan2.7-Image (krok po kroku)
1. Dostęp do platformy
Dostępne przez:
- Alibaba Cloud (platforma BaiLian)
- Oficjalne narzędzia Wanxiang
- CometAPI
2. Wybierz tryb przepływu pracy
Tryb A: tekst do obrazu
Przykładowy prompt:
A cinematic portrait of a cyberpunk woman, neon lighting, ultra-detailed, 8K
Tryb B: edycja obrazu
- Prześlij obraz
- Zaznacz obszar
- Wpisz instrukcję
Przykład:
Replace background with a futuristic city
Tryb C: kompozycja wieloobrazowa
- Prześlij wiele referencji
- Zdefiniuj reguły kompozycji
3. Dopracuj parametry
- Paleta kolorów
- Spójność stylu
- Renderowanie tekstu
4. Eksportuj wynik
- Obrazy w wysokiej rozdzielczości
- Zasoby gotowe do zastosowań komercyjnych
Wydajność benchmarkowa i porównanie z konkurencją
W ślepych testach preferencji użytkowników Wan2.7-Image przewyższa GPT-Image-1.5 pod względem jakości generowania z tekstu i dorównuje lub przewyższa Nano Banana Pro w renderowaniu tekstu, fotorealizmie i wiedzy o świecie.
Tabela porównawcza:
| Model | Renderowanie tekstu | Realizacja poleceń | Dostosowywanie awatarów | Obrazy referencyjne (wiele) | Ujednolicone generowanie/edycja | Rozdzielczość | Open source/API |
|---|---|---|---|---|---|---|---|
| Wan2.7-Image | Doskonałe (12 języków) | Ponadprzeciętne (Tryb myślenia) | Na poziomie kośćca | 9 | Tak | 2K–4K | Tak/API |
| Midjourney V8 | Dobre | Umiarkowane | Silne artystyczne | Ograniczone | Nie | Wysoka | Tylko Discord |
| FLUX | Dobre | Silne (proste) | Dobre | Ograniczone | Nie | Wysoka | Tak |
| DALL-E 3 | Umiarkowane | Dobre | Umiarkowane | Nie | Nie | 2K | API |
| Nano Banana Pro | Silne | Silna edycja | Dobre | Silne | Częściowe | Wysoka | Zamknięty |
Wan2.7-Image prowadzi w zakresie ujednoliconego przepływu pracy, wielojęzycznego tekstu i precyzyjnej kontroli — szczególnie cenne w rynkach nieanglojęzycznych i profesjonalnych pipeline’ach.
CometAPI to kompleksowa platforma agregująca interfejsy dużych modeli, oferująca bezproblemową integrację i zarządzanie usługami API. Obsługuje wiele API do generowania obrazów, takie jak GPT-image-1.5, seria Nano Banana, Midjourney oraz Qwen Image Series itd., w cenach niższych niż na oficjalnych stronach.
Kto powinien używać Wan2.7-Image
Wan2.7-Image jest szczególnie istotny dla zespołów, które potrzebują szybkości i elastyczności, a nie tylko jednorazowego tworzenia sztuki. Dotyczy to marketerów performance, projektantów produktów, studiów e-commerce, zespołów od treści społecznościowych i agencji produkujących wiele wariantów z tego samego briefu. Obsługa wielu obrazów wejściowych, wielokrotnej generacji i edycji opartej na instrukcjach sprawia, że model jest wyjątkowo atrakcyjny w przepływach pracy, gdzie liczą się spójność, szybkość i kontrola nad poleceniem.
Przykładowe zastosowania
- Gry/Rozrywka: Wygeneruj 100 unikalnych NPC w kilka minut.
- Marketing/E-commerce: Karuzele spójne z brandem z dokładnymi paletami kolorów.
- Edukacja/Akademia: Plakaty gotowe do druku z wzorami i tabelami.
- Agencje projektowe: Storyboardy i poprawki klienta dzięki interaktywnej edycji.
Wzrost produktywności wynika z mniejszej liczby iteracji i bezproblemowej integracji referencji.
Wnioski:
Alibaba Wan2.7-Image redefiniuje kreatywność AI poprzez ujednolicenie generowania, edycji i rozumienia. Jego 5 kluczowych funkcji, współdzielona przestrzeń utajona i ulepszenia wersji Pro dostarczają profesjonalnych rezultatów, z którymi konkurenci wciąż mają problem. Niezależnie od tego, czy prototypujesz treści społecznościowe, czy tworzysz gotowe do druku wizualizacje akademickie, oferuje bezkonkurencyjną precyzję i efektywność.
Zacznij już dziś na wan.video lub przez API w CometAPI. Dla deweloperów i przedsiębiorstw połączenie mocy, dostępności i popartej danymi przewagi czyni Wan2.7-Image oczywistym liderem wśród ujednoliconych modeli AI do obrazów w 2026 r. i później.