

GLM-5-Turbo to nowy bazowy model LLM od Zhipu AI, specjalnie trenowany i dostrajany pod przepływy pracy w stylu agentowym (firma określa docelowy ekosystem jako scenariusze OpenClaw / „lobster”). Oferuje bardzo długi kontekst (do ~200 tys. tokenów), strumieniowanie i ustrukturyzowane wyjścia, niższe wskaźniki błędów wywołań narzędzi (raportowane ~0,67% w testach zewnętrznych) oraz istotnie niższe ceny za token . Model ma na celu wymianę niewielkiej części szczytowej wydajności pojedynczej odpowiedzi na znacznie lepszą stabilność, niezawodność narzędzi, obsługę zadań harmonogramowanych/trwałych oraz wykonywanie długich łańcuchów — co jest przydatne dla autonomicznych agentów, systemów orkiestracji i potoków wielonarzędziowych.
Czym jest GLM-5-Turbo?
GLM-5-Turbo jest przedstawiany przez Zhipu jako model bazowy zbudowany specjalnie do orkiestracji agentów i złożonych zautomatyzowanych przepływów pracy, a nie jako ogólny model do czatu lub multimodalny. Założenia projektowe kładą nacisk na:
- Natywne szkolenie przyjazne agentom (użycie narzędzi, wykonywanie poleceń, zadania czasowe/trwałe).
- Bardzo duże okna kontekstowe i pojemność wyjściową, aby wspierać długie sesje, pamięć i planowanie łańcucha rozumowania.
- Stabilne wnioskowanie o wysokiej przepustowości dla długich procesów biznesowych i zadań harmonogramowanych.
W przeciwieństwie do tradycyjnych LLM-ów zoptymalizowanych pod czat lub generowanie tekstu, GLM-5-Turbo jest:
- Agent-first (nie chat-first)
- Zbudowany dla środowisk OpenClaw („lobster”)
- Zaprojektowany do wieloetapowych autonomicznych przepływów pracy
🦞 Co oznacza „Lobster Agent”?
Pojęcie „lobster” odnosi się do OpenClaw, ekosystemu agentów AI Zhipu, w którym modele:
- Dynamicznie używają narzędzi
- Wykonują długie łańcuchy zadań
- Utrzymują trwałą pamięć
- Działają w terminalach, aplikacjach i API
GLM-5-Turbo jest głęboko zoptymalizowany pod ten paradygmat, rozwiązując kluczowe problemy agentów, takie jak:
- Niezawodność wywołań narzędzi
- Dekompozycja zadań
- Planowanie długoterminowe
- Stabilność wykonania
Kluczowe funkcje i dlaczego są ważne
Długi kontekst + ogromna pojemność wyjściowa (200K / 128K)
Okno kontekstowe 200 tys. tokenów i możliwość wygenerowania 128 tys. tokenów pozwalają GLM-5-Turbo:
- Zachować rozszerzoną pamięć wcześniejszego kontekstu (rozmów, wyjść narzędzi, wyników pośrednich).
- Tworzyć bardzo długie artefakty (wieloetapowe plany, długie raporty, bazy kodu) bez wielokrotnego „doszywania” kontekstu.
- Obsługiwać agentów wieloturowych, którzy muszą zachować pełną historię wykonania, aby podejmować trafne decyzje.
Jest to świadomy wybór techniczny dla agentów — zamiast dzielić zadania na krótkie prompty, agenci mogą utrzymywać spójny stan przez tysiące tur konwersacji lub kroków.
Prymitywy agentowe wbudowane w trening
Zamiast adaptować model ogólnego przeznaczenia do zadań agentowych, GLM-5-Turbo trenowano z celami w stylu agentowym (np. zachowanie przy wywoływaniu narzędzi, parsowanie poleceń/argumentów). Deklarowany efekt to mniej halucynacji podczas wywołań narzędzi, stabilniejsze plany wieloetapowe i lepsze opóźnienia przy długich przebiegach — wszystko to jest cenne tam, gdzie automatyzacja musi niezawodnie łączyć wiele zewnętrznych API lub narzędzi.
Przepustowość i stabilność wykonania
Wariant GLM-5-Turbo poprawia stabilność wykonania i przepustowość w długich procesach biznesowych w porównaniu z uogólnionymi dużymi modelami — przekaz marketingowy podkreśla „wysokoprzepustowe wykonywanie” i „wiodącą stabilność odpowiedzi” wśród podobnych modeli. Ma to znaczenie dla wdrożeń agentowych w przedsiębiorstwach, gdzie nieudany krok może przerwać cały potok. Niezależne benchmarki stron trzecich wciąż się pojawiają.
Dane benchmarkowe GLM-5-Turbo
Uwaga: Zhipu opublikowało oceny wewnętrzne, a benchmarki GLM-5 od stron trzecich/środowiska akademickiego są dostępne. GLM-5-Turbo został wydany niedawno; pojawienie się niezależnych benchmarków społeczności zajmie trochę czasu. Poniżej podajemy najbardziej wiarygodne, opublikowane dane i kontekst.
GLM-5 (punkt odniesienia) — reprezentatywne opublikowane metryki
GLM-5 od Zhipu (flagowy poprzednik Turbo) raportuje wysokie wyniki w wielu zadaniach inżynieryjnych/przepływowych — na przykład:
- SWE-bench Verified: 77,8 (raportowane w dokumentacji GLM-5 jako czołowy wynik wśród modeli otwartych).
- Terminal Bench 2.0: 56,2 (raportowane jako najlepszy wynik modelu otwartego dla danego rozkładu).
Liczby te ustanawiają GLM-5 jako wysoki punkt odniesienia w zadaniach z zakresu inżynierii oprogramowania i wykonywania; GLM-5-Turbo jest pozycjonowany jako model, który zamienia część surowego nacisku na rozmiar/liczbę parametrów na lepszą niezawodność agentową i przepustowość. GLM-5-Turbo wykazał ~0,67% błędów wywołań narzędzi w ich przebiegach porównawczych, istotnie mniej niż porównywane przebiegi dostawcy GLM-5, które mieściły się w zakresie ~2,33% do 6,41%.
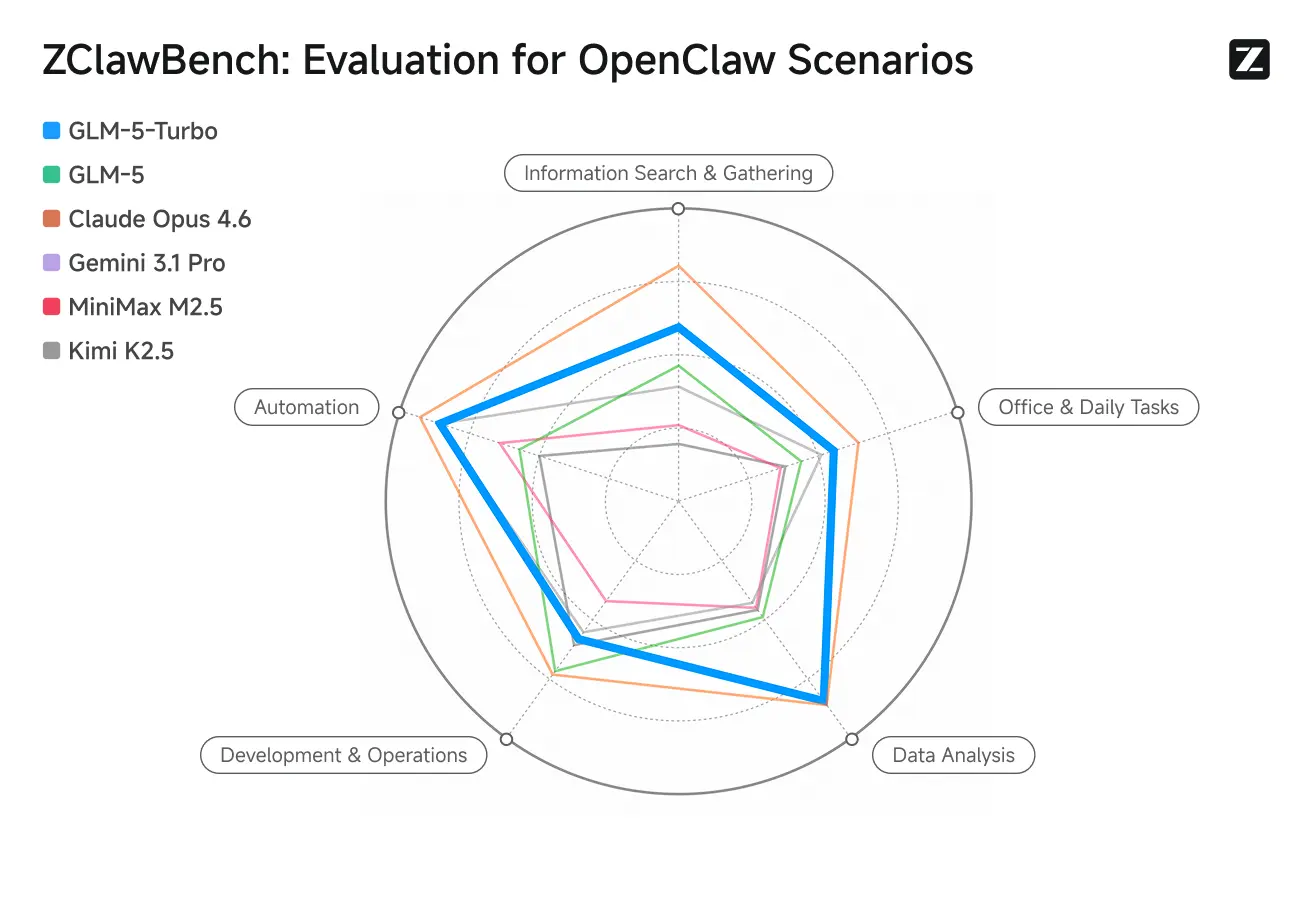
ZClawBench: test benchmarkowy dla scenariuszy proxy OpenClaw
Zhipu udostępniło również benchmark ZClawBench do oceny inteligentnych agentów. W ślepych testach obejmujących różne dziedziny, takie jak rozwój oprogramowania, analiza danych i tworzenie treści, nowy model o nazwie kodowej Pony-Alpha-2 zdobył uznanie 90% respondentów.
Ceny i dostępność (kto sprzedaje i za ile)
Zhipu wprowadziło ~20% podwyżkę cen API dla oferty GLM-5-Turbo przy premierze, a jednocześnie zaprezentowało poziomy subskrypcji „Lobster Package”, które mają ustabilizować ceny tokenów dla wdrożeń agentowych.
Raportowane poziomy subskrypcji (przykładowe pakiety)
Dwa przykładowe pakiety Lobster (ceny są raportowanymi przeliczeniami i są przybliżone):
- Plan Entry Lobster: ~39 CNY / miesiąc (~5,66 USD) za 35 000 000 tokenów.
- Plan Mid Lobster: ~99 CNY / miesiąc (~14,36 USD) za 100 000 000 tokenów.
Na podstawie tych opublikowanych liczb koszt 1 miliona tokenów wynosi w przybliżeniu:
- Plan Entry: ~0,162 USD za 1 mln tokenów.
- Plan Mid: ~0,144 USD za 1 mln tokenów.
Te wartości za 1 mln są prostymi przeliczeniami opublikowanego kosztu subskrypcji i limitu tokenów oraz ilustrują ekonomię dużych obciążeń agentowych. (Obliczenia oparte na podawanych w mediach walutach i liczbach tokenów).
Cena API
Reprezentatywna oferta marketplace (CometAPI): 0,96 USD za 1 mln tokenów wejściowych i 3,20 USD za 1 mln tokenów wyjściowych dla GLM-5-Turbo.
Na własnej stronie cenowej dla deweloperów (Z.ai) Zhipu podaje nieco wyższą stawkę bezpośrednią dla GLM-5-Turbo: 1,20 USD za 1 mln tokenów wejściowych i 4,00 USD za 1 mln tokenów wyjściowych (stawki dla cache’owanych wejść są niższe).
GLM-5-Turbo vs GLM-5 — porównanie obok siebie
Na wysokim poziomie:
- GLM-5 = flagowy model bazowy ogólnego przeznaczenia (mocne rozumowanie, kodowanie, benchmarki)
- GLM-5-Turbo = wariant zoptymalizowany pod agentów modelu GLM-5 (ukierunkowany na długie przepływy pracy, użycie narzędzi, stabilność)
GLM-5-Turbo nie jest całkowicie nową architekturą modelu, lecz wyspecjalizowaną, zoptymalizowaną produkcyjnie wersją GLM-5 zaprojektowaną dla systemów agentowych takich jak OpenClaw.
Główne pozycjonowanie
| Model | Pozycjonowanie |
|---|---|
| GLM-5 | Flagowy LLM ogólnego przeznaczenia (rozumowanie, kodowanie, benchmarki) |
| GLM-5-Turbo | Model agent-first (automatyzacja, orkiestracja, użycie narzędzi) |
👉 Mówiąc prosto:
- Użyj GLM-5 → gdy chcesz maksymalnej inteligencji
- Użyj GLM-5-Turbo → gdy chcesz stabilnej automatyzacji / agentów
Porównanie możliwości agentowych (NAJWAŻNIEJSZE)
GLM-5 (zdolności agentowe) już obsługuje:
- Użycie narzędzi
- Wieloetapowe rozumowanie
- Agentów kodujących
Ale ma ograniczenia:
- Może tracić kontekst w długich łańcuchach
- Wywołania narzędzi mogą z czasem ulegać pogorszeniu
- Wymaga większej ilości logiki orkiestracyjnej
GLM-5-Turbo jest jawnie zoptymalizowany pod agentów:
Kluczowe ulepszenia:
- Niezawodność wywołań narzędzi ↑
- Dekompozycja zadań (planowanie) ↑
- Spójność długich łańcuchów ↑
- Obsługa trwałego wykonywania ↑
Przykład ulepszenia:
- Stabilne wykonywanie przez ponad 10 kroków bez utraty kontekstu
👉 Jest to kluczowe dla:
- Systemów w stylu AutoGPT
- Przepływów pracy multi-agentowych
- Automatyzacji SaaS
Szybkość i efektywność
| Aspekt | GLM-5 | GLM-5-Turbo |
|---|---|---|
| Szybkość wnioskowania | Umiarkowana | Wyższa |
| Przepustowość | Standardowa | Wyższa |
| Opóźnienie przy długich zadaniach | Może się pogarszać | Zoptymalizowane |
GLM-5-Turbo został zaprojektowany, aby rozwiązać realny problem branżowy:
Duże modele zwalniają lub ulegają awarii podczas długich przepływów pracy
Porównanie cen
| Model | Wejście (USD/1M tokenów) | Wyjście (USD/1M tokenów) |
|---|---|---|
| GLM-5 | ~1,00 USD | ~3,20 USD |
| GLM-5-Turbo | ~1,20 USD | ~4,00 USD |
👉 GLM-5-Turbo jest droższy (~20% więcej)
Dlaczego jest droższy?
Ponieważ zapewnia:
- Lepszą niezawodność orkiestracji
- Wyższą stabilność produkcyjną
- Optymalizacje specyficzne dla agentów
👉 W przedsiębiorstwach:
- Płacisz więcej za token
- Ale ograniczasz koszt awarii + ponownych prób
| Atrybut | GLM-5 | GLM-5-Turbo |
|---|---|---|
| Główny cel | Flagowy model bazowy ogólnego przeznaczenia (szerokie możliwości, mocne kodowanie/benchmarki) | Model bazowy zoptymalizowany pod agentów / „OpenClaw” / lobster |
| Okno kontekstowe | (raportowane jako duże; GLM-5 koncentruje się na ~200K (GLM-5 również obsługuje długi kontekst) | 200 000 tokenów (jawnie udokumentowane). |
| Maksymalna liczba tokenów wyjściowych | (duża, zależna od modelu) | 128 000 tokenów (udokumentowane). |
| Godne uwagi wyniki benchmarków | SWE-bench: 77,8; Terminal Bench 2.0: 56,2 (raportowane liczby dla GLM-5). | Wewnętrzne ewaluacje wskazują na poprawę stabilności długich łańcuchów i przepustowości dla przepływów agentowych; niezależne publiczne benchmarki są w toku. |
| Modalności | Tekst (podstawowo), rodzina GLM ma warianty vision w modelach pokrewnych | Tylko tekst (zgodnie z dokumentacją) — zoptymalizowany pod agentów opartych na narzędziach. |
| Zalecane przypadki użycia | Szerokie: czat, kod, rozumowanie, treść | Orkiestracja agentów, wywoływanie narzędzi, automatyzacja długoterminowa |
| Ceny | Obowiązujące ceny GLM-5 (różne w zależności od planu) | Nowa premiera — raportowana ~20% podwyżka cen API; wprowadzono nowe poziomy subskrypcji Lobster |
Jak używać GLM-5-Turbo
CometAPI — pojedynczy dostęp API do wielu modeli (zgodny z OpenAI)
CometAPI udostępnia GLM-5-Turbo i zapewnia bazowy URL oraz SDK zgodne z OpenAI. Użyj ciągu modelu, który publikują (ich strona pokazuje GLM-5-Turbo w podobnych cenach). Przykłady zaadaptowane z dokumentacji CometAPI:
curl (CometAPI):
curl -X POST "https://api.cometapi.com/v1/chat/completions" \ -H "Authorization: Bearer YOUR_COMETAPI_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "z-glm-5-turbo", // or use the exact model slug shown in CometAPI UI "messages": [{"role":"user","content":"Create a 5-step checklist for onboarding a new hire."}], "max_tokens": 800 }'
Wartością CometAPI jest wygoda agregatora (jedna integracja dla wielu modeli). Przed wywołaniem potwierdź dokładny slug modelu w panelu CometAPI.
Najlepsze praktyki przy budowie agentów Lobster / OpenClaw z GLM-5-Turbo
- Projektuj pod niezawodność, a nie surowe opóźnienie: przewagą Turbo jest niższy odsetek nieudanych wywołań narzędzi w długich łańcuchach. Strukturyzuj przebiegi agentów tak, by preferowały solidne zakończenia (ponowne próby, idempotentne wywołania narzędzi) zamiast minimalnych zysków w czasie do pierwszego tokenu.
- Używaj streamingu i przyrostowych wywołań narzędzi: korzystaj ze strumieniowania/wyjść porcjowanych, aby ograniczyć konieczność poprawek i umożliwić wcześniejsze wywoływanie narzędzi tam, gdzie to właściwe. GLM-5-Turbo obsługuje streaming.
- Ustrukturyzowane wyjścia dla parserów: preferuj JSON lub dobrze sformatowane wyniki do deterministycznego parsowania przez narzędzia downstream. Turbo obsługuje ustrukturyzowane wyjścia.
- Planuj harmonogramowanie / trwałość: jeśli agent ma okresowo sprawdzać lub uruchamiać zadania w tle, wykorzystaj lepszą semantykę czasu i funkcje cache Turbo, aby uniknąć ponownego planowania w każdym cyklu.
- Instrumentuj wywołania narzędzi i fallbacki: rejestruj wywołania narzędzi i projektuj łagodne ścieżki awaryjne (np. ponów próbę z nieco inną temperaturą lub wywołaj narzędzie zapasowe), ponieważ przepływy agentowe są kruche, jeśli pojedynczne zewnętrzne API zawiedzie. Turbo zmniejsza wskaźniki błędów, ale nie eliminuje awarii zewnętrznych
Deweloperzy mogą już teraz uzyskać dostęp do API GLM-5 i GLM-5 turbo przez CometAPI. Aby rozpocząć, zapoznaj się z przewodnikiem po API, aby uzyskać szczegółowe instrukcje. Przed uzyskaniem dostępu upewnij się, że zalogowano się do CometAPI i uzyskano klucz API. CometAPI oferuje cenę znacznie niższą niż oficjalna, aby pomóc Ci we wdrożeniu.
Gotowy do startu?→ Zarejestruj się już dziś, aby korzystać z GLM-5 i GLM-5 turbo !