

na dzień 15 grudnia 2025 r. publicznie dostępne informacje pokazują, że zarówno Google’s Gemini 3 Pro (wersja zapoznawcza), jak i OpenAI’s GPT-5.2 wyznaczają nowe granice w zakresie rozumowania, multimodalności i pracy na długich kontekstach — lecz obierają różne drogi inżynieryjne (Gemini → rzadkie MoE + ogromny kontekst; GPT-5.2 → konstrukcje gęste/„routing”, kompakcja i tryby bardzo zaawansowanego rozumowania), przez co balansują między szczytowymi wynikami benchmarków a przewidywalnością inżynieryjną, narzędziami i ekosystemem. To, co jest „lepsze”, zależy od podstawowej potrzeby: aplikacje agentowe z ekstremalnym kontekstem i multimodalnością skłaniają się ku Gemini 3 Pro; stabilne narzędzia deweloperskie klasy enterprise, przewidywalne koszty i natychmiastowa dostępność API przemawiają za GPT-5.2.
Czym jest GPT-5.2 i jakie są jego główne funkcje?
GPT-5.2 to wydanie z 11 grudnia 2025 r. w rodzinie GPT-5 (warianty: Instant, Thinking, Pro). Pozycjonowany jest jako najbardziej zaawansowany model firmy do „profesjonalnej pracy wiedzochłonnej” — zoptymalizowany pod kątem arkuszy kalkulacyjnych, prezentacji, rozumowania na długim kontekście, wywoływania narzędzi, generowania kodu i zadań wzrokowych. OpenAI udostępniło GPT-5.2 płatnym użytkownikom ChatGPT oraz poprzez OpenAI API (Responses API / Chat Completions) pod nazwami modeli takimi jak gpt-5.2, gpt-5.2-chat-latest i gpt-5.2-pro.
Warianty modelu i przeznaczenie
- gpt-5.2 / GPT-5.2 (Thinking) — najlepszy do złożonego, wieloetapowego rozumowania (domyślny wariant rodziny „Thinking” używany w Responses API).
- gpt-5.2-chat-latest / Instant — niższa latencja do codziennej asysty i czatu.
- gpt-5.2-pro / Pro — najwyższa wierność/niezawodność do najtrudniejszych problemów (dodatkowa moc obliczeniowa, obsługuje
reasoning_effort: "xhigh").
Kluczowe cechy techniczne (widoczne dla użytkownika)
- Usprawnienia w wizji i multimodalności — lepsze rozumowanie przestrzenne na obrazach i ulepszone rozumienie wideo w połączeniu z narzędziami kodu (narzędzie Python), plus wsparcie dla narzędzi w stylu code-interpreter do wykonywania fragmentów.
- Konfigurowalny wysiłek rozumowania (
reasoning_effort: none|minimal|low|medium|high|xhigh), aby równoważyć opóźnienie/koszt względem głębokości.xhighjest nowością w GPT-5.2 (i obsługiwane w Pro). - Ulepszone radzenie sobie z długim kontekstem oraz funkcje kompakcji, by rozumować w setkach tysięcy tokenów (OpenAI raportuje silne wyniki MRCRv2 / metryki długiego kontekstu).
- Zaawansowane wywoływanie narzędzi i przepływy agentowe — silniejsza koordynacja wieloturnowa, lepsza orkiestracja narzędzi w architekturze „pojedynczego mega-agenta” (OpenAI podkreśla wydajność narzędzi na Tau2-bench).
Czym jest Gemini 3 Pro Preview?
Gemini 3 Pro Preview to najbardziej zaawansowany model generatywnej SI Google’a, wydany w ramach szerszej rodziny Gemini 3 w listopadzie 2025 r. Model kładzie nacisk na zrozumienie multimodalne — potrafi rozumieć i syntetyzować tekst, obrazy, wideo i dźwięk — oraz dysponuje dużym oknem kontekstu (~1 milion tokenów) do obsługi obszernych dokumentów lub baz kodu.
Google pozycjonuje Gemini 3 Pro jako stan sztuki w zakresie głębokości i niuansów rozumowania i wykorzystuje go jako silnik wielu narzędzi deweloperskich i korporacyjnych, w tym Google AI Studio, Vertex AI oraz platform rozwoju agentów jak Google Antigravity.
Na chwilę obecną Gemini 3 Pro jest w wersji zapoznawczej — funkcjonalność i dostęp nadal się rozszerzają, ale model już teraz osiąga wysokie wyniki w logice, zrozumieniu multimodalnym i przepływach agentowych.
Kluczowe cechy techniczne i produktowe
- Okno kontekstu: Gemini 3 Pro Preview obsługuje 1 000 000 tokenów wejściowych (oraz do 64 tys. tokenów wyjścia), co stanowi praktyczną przewagę przy wczytywaniu ekstremalnie dużych dokumentów, książek czy transkryptów wideo w jednym żądaniu.
- Funkcje API: parametr
thinking_level(low/high) do równoważenia latencji i głębokości rozumowania; ustawieniamedia_resolutiondo kontroli wierności multimodalnej i wykorzystania tokenów; obsługa ugruntowania w wyszukiwarce, kontekstu plików/URL, wykonywania kodu i wywoływania funkcji. Podpisy myśli oraz cache kontekstu pomagają utrzymać stan w przepływach wielowywołaniowych. - Tryb Deep Think / wyższe rozumowanie: opcja „Deep Think” zapewnia dodatkowe przejście rozumowania, by podbić wyniki w trudnych benchmarkach. Google publikuje Deep Think jako oddzielną ścieżkę wysokiej wydajności do złożonych problemów.
- Natywna obsługa multimodalności: Wejścia tekstowe, obrazowe, dźwiękowe i wideo z silnym ugruntowaniem względem wyszukiwarki i produktów (wyróżniane są wyniki Video-MMMU i innych benchmarków multimodalnych).
Szybki przegląd — GPT-5.2 vs Gemini 3 Pro
Kompaktowa tabela porównawcza z najważniejszymi faktami (z cytowanymi źródłami).
| Aspekt | GPT-5.2 (OpenAI) | Gemini 3 Pro (Google / DeepMind) |
|---|---|---|
| Dostawca / pozycjonowanie | OpenAI — flagowy upgrade GPT-5.x skupiony na profesjonalnej pracy wiedzochłonnej, kodowaniu i przepływach agentowych. | Google DeepMind / Google AI — flagowa generacja Gemini skoncentrowana na ultradługim, multimodalnym rozumowaniu i integracji narzędzi. |
| Główne odmiany modelu | Instant, Thinking, Pro (oraz automatyczne przełączanie między nimi). Pro dodaje wyższy poziom rozumowania. | Rodzina Gemini 3, w tym Gemini 3 Pro i tryby Deep-Think; nacisk na multimodalność / agentowość. |
| Okno kontekstu (wejście/wyjście) | ~400 000 tokenów łącznej pojemności wejścia; do 128 000 tokenów wyjścia/rozumowania (zaprojektowany do bardzo długich dokumentów i baz kodu). | Do ~1 000 000 tokenów wejścia/okna kontekstu (1M) z maks. 64 tys. tokenów wyjścia |
| Kluczowe mocne strony / fokus | Rozumowanie na długim kontekście, wywoływanie narzędzi agentowych, kodowanie, ustrukturyzowane zadania biurowe (arkusze, prezentacje); aktualizacje safety/system-card podkreślają niezawodność. | Zrozumienie multimodalne w skali, rozumowanie + kompozycja obrazów, bardzo duży kontekst + tryb rozumowania „Deep Think”, mocne integracje narzędzi/agentów w ekosystemie Google. |
| Multimodalność i obrazowanie | Ulepszona wizja i ugruntowanie multimodalne; dostrojony do użycia narzędzi i analizy dokumentów. | Wysokiej jakości generowanie obrazów + kompozycja z rozszerzonym rozumowaniem, edycja obrazów z wieloma referencjami i czytelne renderowanie tekstu. |
| Latencja / interaktywność | Dostawca podkreśla szybszy inference i responsywność promptów (niższa latencja niż w poprzednich modelach GPT-5.x); wiele poziomów (Instant / Thinking / Pro). | Google podkreśla zoptymalizowany „Flash”/serwowanie i porównywalne szybkości interakcji w wielu przepływach; tryb Deep Think wymienia opóźnienie na głębsze rozumowanie. |
| Cechy wyróżniające | Poziomy wysiłku rozumowania (medium/high/xhigh), ulepszone wywoływanie narzędzi, wysokiej jakości generowanie kodu, wysoka efektywność tokenowa dla procesów enterprise. | 1M tokenów kontekstu, silne natywne wczytywanie multimodalne (wideo/audio), tryb rozumowania „Deep Think”, ścisłe integracje z produktami Google (Docs/Drive/NotebookLM). |
| Typowe najlepsze zastosowania | Analiza długich dokumentów, przepływy agentowe, złożone projekty kodowe, automatyzacja enterprise (arkusze/raporty). | Ekstremalnie duże projekty multimodalne, przepływy agentowe o długim horyzoncie wymagające kontekstu 1M tokenów, zaawansowane pipeline’y obraz + rozumowanie. |
Jak porównują się architektury GPT-5.2 i Gemini 3 Pro?
Rdzenna architektura
- Benchmarki / ewaluacje realnej pracy: GPT-5.2 Thinking osiągnął 70,9% wygranych/remisów na GDPval (ewaluacja pracy wiedzochłonnej w 44 zawodach) oraz duże skoki na benchmarkach inżynieryjnych i matematycznych względem wcześniejszych wariantów GPT-5. Znaczne ulepszenia w kodowaniu (SWE-Bench Pro) i naukach ścisłych (GPQA Diamond).
- Narzędzia i agenci: Silne wsparcie wbudowane dla wywoływania narzędzi, wykonywania Pythona i przepływów agentowych (wyszukiwanie dokumentów, analiza plików, agenci data science). 11x szybciej / <1% kosztu względem ekspertów ludzkich dla niektórych zadań GDPval (miara potencjalnej wartości ekonomicznej, 70,9% vs. poprzednio ~38,8%) oraz konkretne zyski w modelowaniu arkuszy (np. +9,3% na zadaniu „junior investment banking” vs GPT-5.1).
- Gemini 3 Pro: Rzadki Transformer Mixture-of-Experts (MoE). Model aktywuje niewielki zestaw ekspertów na token, co pozwala na ekstremalnie dużą łączną pojemność parametrów przy podliniowym koszcie obliczeń na token. Google publikuje kartę modelu wyjaśniającą, że Sparse MoE jest kluczowym czynnikiem profilu wydajności. Ta architektura umożliwia przesuwanie pojemności modelu znacznie wyżej bez liniowego kosztu inference.
- GPT-5.2 (OpenAI): OpenAI kontynuuje wykorzystanie architektur opartych na Transformerach z technikami routing/compaction w rodzinie GPT-5 („router” uruchamia różne tryby — Instant vs Thinking — a firma dokumentuje kompakcję i zarządzanie tokenami dla długiego kontekstu). GPT-5.2 akcentuje trening i ewaluację „myśl zanim odpowiesz” oraz kompakcję dla zadań o długim horyzoncie zamiast ogłaszania klasycznego, szerokiego Sparse-MoE.
Implikacje architektur
- Kompromisy latencja/koszt: Modele MoE jak Gemini 3 Pro mogą oferować wyższą szczytową zdolność na token przy niższym koszcie inference dla wielu zadań, ponieważ uruchamiana jest tylko podgrupa ekspertów. Mogą jednak zwiększać złożoność serwowania i schedulingu (równoważenie ekspertów przy cold start, IO). Podejście GPT-5.2 (gęsty/routowany z kompakcją) sprzyja przewidywalnej latencji i ergonomii developerskiej — zwłaszcza w zintegrowanych narzędziach OpenAI jak Responses, Realtime, Assistants i batch API.
- Skalowanie długiego kontekstu: 1M tokenów wejściowych w Gemini pozwala natywnie podawać ekstremalnie długie dokumenty i strumienie multimodalne. ~400k łącznego kontekstu (wejście+wyjście) w GPT-5.2 nadal jest ogromne i pokrywa większość potrzeb enterprise, ale jest mniejsze niż specyfikacja 1M w Gemini. Dla bardzo dużych korpusów lub wielogodzinnych transkryptów wideo specyfikacja Gemini daje wyraźną przewagę techniczną.
Narzędzia, agenci i multimodalna „instalacja wod-kan”
- OpenAI: głęboka integracja wywoływania narzędzi, wykonywania Pythona, trybów rozumowania „Pro” oraz płatnych ekosystemów agentów (ChatGPT Agents / integracje narzędzi enterprise). Silne ukierunkowanie na przepływy zorientowane na kod oraz generowanie arkuszy/prezentacji jako pierwszorzędnych wyjść.
- Google / Gemini: wbudowane ugruntowanie w Google Search (opcjonalna funkcja rozliczana), wykonywanie kodu, kontekst URL i plików oraz jawne sterowanie rozdzielczością mediów w celu wymiany tokenów na wierność wizualną. API oferuje
thinking_leveli inne pokrętła do strojenia koszt/latencja/jakość.
Jak wypadają liczby w benchmarkach
Okna kontekstu i obsługa tokenów
- Gemini 3 Pro Preview: 1 000 000 tokenów wejściowych / 64 tys. tokenów wyjściowych (karta modelu Pro preview). Knowledge cutoff: styczeń 2025 (Google).
- GPT-5.2: OpenAI demonstruje silną wydajność w długim kontekście (wyniki MRCRv2 w zadaniach „needle” 4k–256k z zakresami >85–95% w wielu ustawieniach) i stosuje funkcje kompakcji; publiczne przykłady kontekstu wskazują na solidną wydajność nawet przy bardzo dużych kontekstach, lecz OpenAI podaje okna specyficzne dla wariantów (i podkreśla kompakcję, a nie jedno „1M”). W API używa się modeli
gpt-5.2,gpt-5.2-chat-latest,gpt-5.2-pro.
Rozumowanie i benchmarki agentowe
- OpenAI (wybrane): Tau2-bench Telecom 98,7% (GPT-5.2 Thinking), silne wzrosty w wieloetapowym użyciu narzędzi i zadaniach agentowych (OpenAI podkreśla konsolidację systemów wieloagentowych w „mega-agenta”). GPQA Diamond i ARC-AGI pokazały wzrosty względem GPT-5.1.
- Google (wybrane): Gemini 3 Pro: LMArena 1501 Elo, MMMU-Pro 81%, Video-MMMU 87,6%, wysokie wyniki GPQA i Humanity’s Last Exam; Google demonstruje też silne planowanie długohoryzontalne w przykładach agentowych.
Narzędzia i agenci:
GPT-5.2: Silne wsparcie wbudowane dla wywoływania narzędzi, wykonywania Pythona i przepływów agentowych (wyszukiwanie dokumentów, analiza plików, agenci data science). 11x szybciej / <1% kosztu względem ekspertów ludzkich dla niektórych zadań GDPval (miara potencjalnej wartości ekonomicznej, 70,9% vs. wcześniej ~38,8%) i konkretne zyski w modelowaniu arkuszy (np. +9,3% w zadaniu juniorskiego analityka bankowości inwestycyjnej vs GPT-5.1).
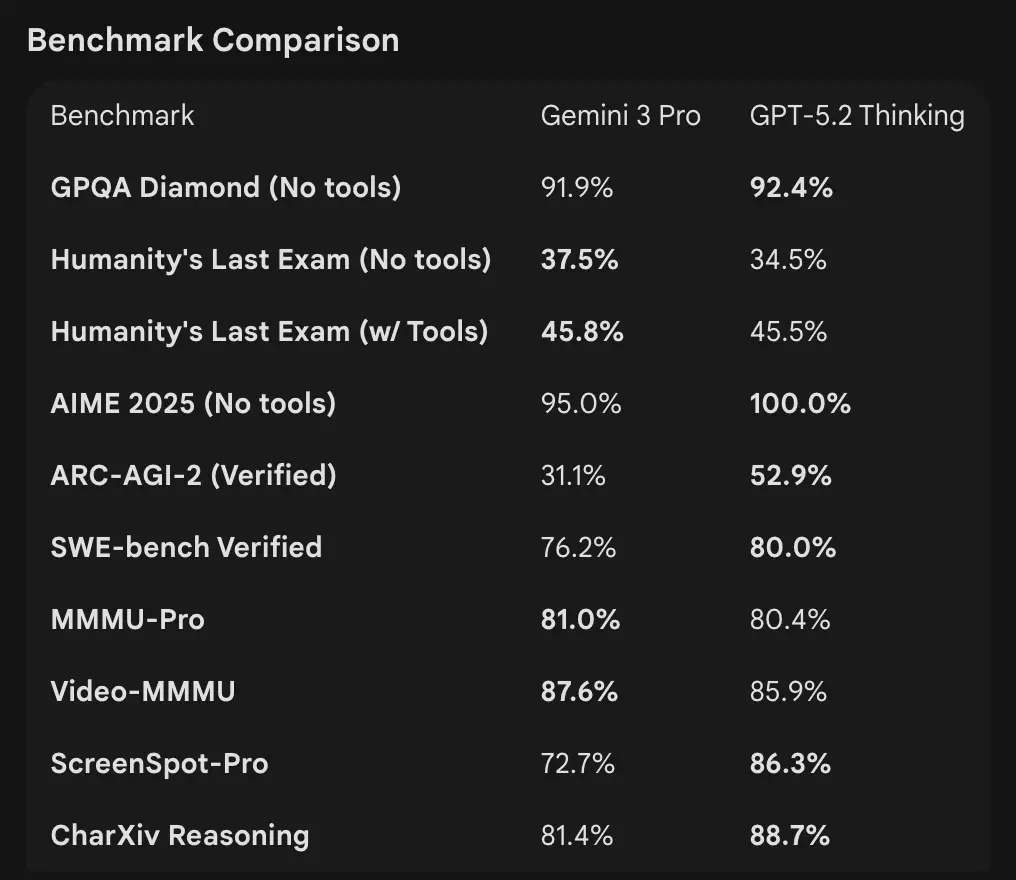
Interpretacja: benchmarki się uzupełniają — OpenAI akcentuje benchmarki realnej pracy wiedzochłonnej (GDPval), pokazując, że GPT-5.2 świetnie radzi sobie z zadaniami produkcyjnymi jak arkusze, slajdy i długie sekwencje agentowe. Google podkreśla rankingi surowego rozumowania i ekstremalnie duże okna kontekstu w jednym żądaniu. Co ma większe znaczenie, zależy od obciążenia: agentowe, długodokumentowe pipeline’y enterprise faworyzują udokumentowaną wydajność GPT-5.2 w GDPval; wczytywanie masywnego surowego kontekstu (np. całe korpusy wideo / pełne książki na raz) faworyzuje 1M wejścia w Gemini.
Jak porównać zdolności multimodalne?
Wejścia i wyjścia
- Gemini 3 Pro Preview: obsługuje wejścia tekst, obraz, wideo, audio, PDF i wyjścia tekstowe; Google oferuje granularne sterowanie
media_resolutionoraz parametrthinking_leveldo strojenia kosztu względem wierności w pracy multimodalnej. Limit wyjściowy 64k tokenów; wejście do 1M tokenów. - GPT-5.2: obsługuje bogate przepływy wizji i multimodalności; OpenAI podkreśla poprawę rozumowania przestrzennego (szacowanie etykiet dla komponentów obrazu), rozumienie wideo (wyniki Video MMMU) i wizję wspieraną narzędziami (zadania wzrokowe + narzędzie Python poprawiają wyniki). GPT-5.2 akcentuje, że złożone zadania wizja + kod bardzo zyskują przy włączonym wsparciu narzędzi (wykonywanie kodu w pętli).
Różnice praktyczne
Granularność vs. rozpiętość: Gemini udostępnia zestaw pokręteł multimodalnych (media_resolution, thinking_level), dzięki którym deweloperzy mogą stroić kompromisy per typ medium. GPT-5.2 akcentuje zintegrowane użycie narzędzi (wykonywanie Pythona w pętli) do łączenia wizji, kodu i transformacji danych. Jeśli przypadek użycia to ciężka analiza wideo + obrazów z ekstremalnie dużymi kontekstami, 1M kontekstu w Gemini jest przekonujące; jeśli przepływy wymagają wykonywania kodu „w pętli” (transformacje danych, generowanie arkuszy), narzędzia kodowe i przyjazność dla agentów w GPT-5.2 mogą być wygodniejsze.
A co z dostępem do API, SDK i cenami?
OpenAI GPT-5.2 (API i ceny)
- API:
gpt-5.2,gpt-5.2-chat-latest,gpt-5.2-proprzez Responses API / Chat Completions. Dojrzałe SDK (Python/JS), przewodniki cookbook i dojrzały ekosystem. - Cennik (publiczny): $1,75 / 1M tokenów wejściowych i $14 / 1M tokenów wyjściowych; rabaty cache (90% dla cache’owanych wejść) obniżają efektywny koszt przy powtarzanych danych. OpenAI podkreśla efektywność tokenową (wyższa cena per token, ale mniejszy całkowity koszt, by osiągnąć próg jakości).
Gemini 3 Pro Preview (API i ceny)
- API:
gemini-3-pro-previewprzez Google GenAI SDK oraz endpointy Vertex AI/GenerativeLanguage. Nowe parametry (thinking_level,media_resolution) i integracja z ugruntowaniami Google oraz narzędziami. - Cennik (public preview): Około $2 / 1M tokenów wejściowych i $12 / 1M tokenów wyjściowych dla poziomów preview poniżej 200k tokenów; mogą obowiązywać dodatkowe opłaty za Search grounding, Mapy lub inne usługi Google (rozliczanie Search grounding startuje 5 stycznia 2026 r.).
Użyj GPT-5.2 i Gemini 3 przez CometAPI
CometAPI to brama/aggregator API: pojedynczy endpoint REST w stylu OpenAI, który daje jednolity dostęp do setek modeli od wielu dostawców (LLM, modele obraz/wideo, embeddingi itd.). Zamiast integrować wiele SDK dostawców, CometAPI pozwala wywoływać znane endpointy w formacie OpenAI (chat/completions/embeddings/images), przełączając modele lub dostawców pod spodem.
Deweloperzy mogą równocześnie korzystać z flagowych modeli dwóch różnych firm przez CometAPI bez zmiany dostawców, a ceny API są bardziej przystępne, zwykle niższe o 20%.
Przykład: szybkie fragmenty API (kopiuj-wklej do testu)
Poniżej minimalne przykłady do uruchomienia. Odzwierciedlają szybkie starty dostawców (OpenAI Responses API + Google GenAI client). Zamień $OPENAI_API_KEY / $GEMINI_API_KEY na własne klucze.
GPT-5.2 — Python (OpenAI Responses API, rozumowanie ustawione na xhigh do trudnych problemów)
# Python (wymaga openai SDK obsługującego Responses API)
from openai import OpenAI
client = OpenAI(api_key="YOUR_OPENAI_API_KEY")
resp = client.responses.create(
model="gpt-5.2-pro", # gpt-5.2 or gpt-5.2-pro
input="Streść ten firmowy raport o objętości 50 tys. tokenów i przygotuj konspekt 10-slajdowej prezentacji z notatkami prelegenta.",
reasoning={"effort": "xhigh"}, # deeper reasoning
max_output_tokens=4000
)
print(resp.output_text) # lub przejrzyj resp, aby uzyskać ustrukturyzowane wyjścia / tokeny
Uwagi: reasoning.effort pozwala wymieniać koszt na głębokość. Użyj gpt-5.2-chat-latest dla stylu czatu Instant. Dokumentacja OpenAI zawiera przykłady responses.create.
GPT-5.2 — curl (prosty)
curl https://api.openai.com/v1/responses \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-5.2",
"input": "Napisz funkcję Pythona, która konwertuje PDF z tabelami do znormalizowanego CSV z typowanymi kolumnami.",
"reasoning": {"effort":"high"}
}'
(Sprawdź JSON pod kątem output_text lub ustrukturyzowanych wyjść.)
Gemini 3 Pro Preview — Python (klient Google GenAI)
# Python (klient google genai) — przykład z dokumentacji Google
from google import genai
client = genai.Client(api_key="YOUR_GEMINI_API_KEY")
response = client.models.generate_content(
model="gemini-3-pro-preview",
contents="Znajdź warunek wyścigu w tym wielowątkowym fragmencie C++: <wklej kod tutaj>",
config={
"thinkingConfig": {"thinking_level": "high"}
}
)
print(response.text)
Uwagi: thinking_level kontroluje wewnętrzne rozumowanie modelu; media_resolution można ustawić dla obrazów/wideo. Przykłady REST i JS znajdują się w przewodniku dewelopera Gemini od Google.
Gemini 3 Pro — curl (REST)
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-X POST \
-d '{
"contents": [{
"parts": [{"text": "Wyjaśnij warunek wyścigu w tym kodzie C++: ..."}]
}],
"generationConfig": {"thinkingConfig": {"thinkingLevel": "high"}}
}'
Dokumentacja Google zawiera przykłady multimodalne (dane obrazów inline, media_resolution).
Który model jest „lepszy” — wskazówki praktyczne
Nie ma uniwersalnego „zwycięzcy”; wybieraj w oparciu o przypadek użycia i ograniczenia. Poniżej krótka macierz decyzyjna.
Wybierz GPT-5.2, jeśli:
- Potrzebujesz ścisłej integracji z narzędziami wykonywania kodu (ekosystem interpreter/narzędzia OpenAI) do programistycznych pipeline’ów danych, generowania arkuszy lub agentowych przepływów kodu. OpenAI podkreśla ulepszenia narzędzia Python i użycie mega-agenta.
- Priorytetem jest efektywność tokenowa wg deklaracji dostawcy oraz chcesz jawnych, przewidywalnych cen OpenAI per token z dużymi rabatami na cache’owane wejścia (pomaga w przepływach wsadowych/produkcyjnych).
- Chcesz ekosystemu OpenAI (integracja produktu ChatGPT, partnerstwa Azure / Microsoft oraz narzędzia wokół Responses API i Codex).
Wybierz Gemini 3 Pro, jeśli:
- Potrzebujesz ekstremalnych wejść multimodalnych (wideo + obrazy + audio + PDF) i chcesz jednego modelu, który natywnie akceptuje te wejścia z oknem wejściowym 1 000 000 tokenów. Google wprost pozycjonuje to do długich wideo, dużych pipeline’ów dokument + wideo i interakcyjnych zastosowań Search/AI Mode.
- Budujesz na Google Cloud / Vertex AI i chcesz ścisłej integracji z ugruntowaniem Google Search, provisioningiem na Vertex i klientami GenAI. Skorzystasz na integracjach z produktami Google (Search AI Mode, AI Studio, Antigravity do tworzenia agentów).
Wniosek: Który lepszy w 2026?
W starciu GPT-5.2 vs. Gemini 3 Pro Preview odpowiedź brzmi: to zależy od kontekstu:
- GPT-5.2 prowadzi w profesjonalnej pracy wiedzochłonnej, głębi analitycznej i ustrukturyzowanych przepływach.
- Gemini 3 Pro Preview błyszczy w zrozumieniu multimodalnym, zintegrowanych ekosystemach i zadaniach wymagających dużego kontekstu.
Żaden model nie jest uniwersalnie „lepszy” — ich mocne strony odpowiadają różnym realnym wymaganiom. Rozsądni adopci dobierają model do konkretnych przypadków użycia, ograniczeń budżetowych i zgodności z ekosystemem.
Jasne jest w 2026 r., że frontier SI znacząco się przesunął, a zarówno GPT-5.2, jak i Gemini 3 Pro posuwają naprzód granice możliwości systemów inteligentnych w przedsiębiorstwach i poza nimi.
Jeśli chcesz spróbować od razu, eksploruj możliwości GPT-5.2 i Gemini 3 Pro w CometAPI's Playground i zapoznaj się z przewodnikiem API po szczegółowe instrukcje. Przed dostępem upewnij się, że zalogowałeś(-aś) się do CometAPI i uzyskałeś(-aś) klucz API. CometAPI oferuje cenę znacznie niższą niż oficjalna, aby ułatwić integrację.
Gotowi do działania? → Bezpłatna wersja próbna GPT-5.2 i Gemini 3 Pro !
Jeśli chcesz