

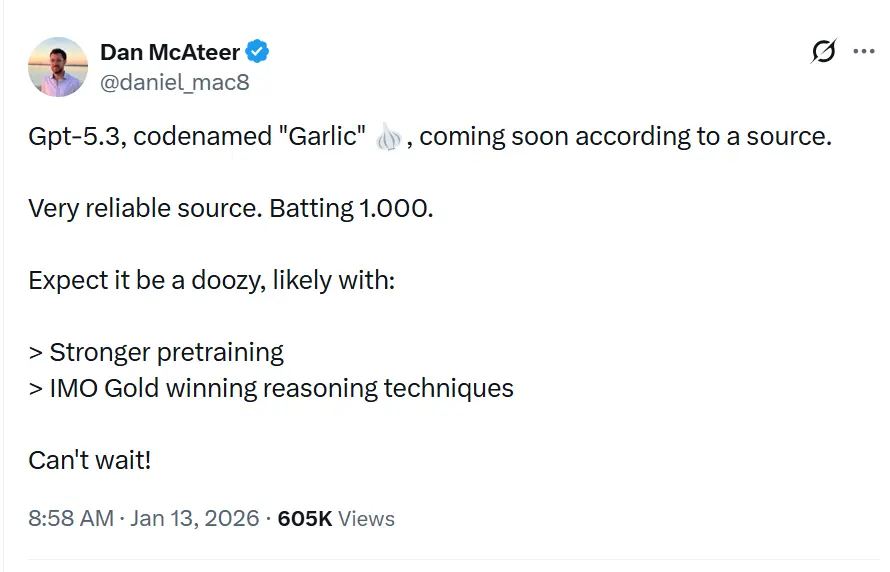
Kryptonim GPT-5.3„Garlic” został w przeciekach i raportach opisany jako kolejna inkrementalna/iteracyjna wersja GPT-5.x, której celem jest zamknięcie luk w rozumowaniu, kodowaniu i wydajności produktu; jest to odpowiedź OpenAI na presję konkurencyjną ze strony Gemini od Google i Claude od Anthropic.
OpenAI eksperymentuje z gęstszą, bardziej efektywną iteracją GPT-5.x ukierunkowaną na silniejsze rozumowanie, szybszą inferencję i dłuższe przepływy pracy w kontekście, zamiast wyłącznie na coraz większą liczbę parametrów. To nie jest tylko kolejna iteracja serii Generative Pre-trained Transformer; to strategiczna kontr-ofensywa. Zrodzona z wewnętrznego „Code Red” ogłoszonego przez CEO Sama Altmana w grudniu 2025 r., „Garlic” oznacza odrzucenie dogmatu „większy znaczy lepszy”, który rządził rozwojem LLM przez pół dekady. Zamiast tego stawia wszystko na nową metrykę: gęstość poznawczą.
Czym jest GPT-5.3 „Garlic”?
GPT-5.3 — o kryptonimie „Garlic” — jest opisywany jako kolejny iteracyjny krok w rodzinie GPT-5 OpenAI. Źródła przedstawiające przeciek pozycjonują Garlic nie jako prosty checkpoint czy korektę tokenów, lecz jako ukierunkowane udoskonalenie architektury i treningu: celem jest uzyskanie wyższej wydajności rozumowania, lepszego planowania wieloetapowego i poprawionego zachowania w długim kontekście z bardziej zwartym, efektywnym modelu inferencyjnym, zamiast polegać wyłącznie na surowej skali. Taka narracja wpisuje się w szersze trendy branżowe ku „gęstym” lub „wysokoefektywnym” projektom modeli.
Przydomek „Garlic” — wyraźne odejście od niebiańskich (Orion) czy słodko-botanicznych (Strawberry) kryptonimów z przeszłości — ma być celową wewnętrzną metaforą. Tak jak pojedynczy ząbek czosnku może nadać potrawie intensywniejszy smak niż większe, mdłe składniki, ten model ma dostarczać skoncentrowaną inteligencję bez ogromnych kosztów obliczeniowych gigantów branży.
Geneza „Code Red”
Istnienia Garlic nie da się oddzielić od kryzysu egzystencjalnego, który go zrodził. Pod koniec 2025 r. OpenAI po raz pierwszy od premiery ChatGPT znalazło się w „pozycji obronnej”. Gemini 3 od Google zdobył koronę na benchmarkach multimodalnych, a Claude Opus 4.5 Anthropic stał się de facto standardem w złożonym kodowaniu i agentowych przepływach pracy. W odpowiedzi kierownictwo OpenAI wstrzymało projekty peryferyjne — w tym eksperymenty z platformą reklamową i konsumenckimi agentami — aby skupić się całkowicie na modelu zdolnym do wykonania „taktycznego uderzenia” na tych konkurentów.
Garlic jest tym uderzeniem. Nie został zaprojektowany, by być największym modelem na świecie; ma być najinteligentniejszy „na parametr”. Łączy linie badawcze wcześniejszych projektów wewnętrznych, przede wszystkim „Shallotpeat”, włączając poprawki błędów i usprawnienia w pre-treningu, które pozwalają mu bić znacznie powyżej swojej „wagi”.
Jaki jest obecny status obserwowanych iteracji modelu GPT-5.3?
Na połowę stycznia 2026 r. GPT-5.3 znajduje się w finalnym etapie wewnętrznej walidacji, fazie w Dolinie Krzemowej często określanej jako „utwardzanie” (hardening). Model jest widoczny w wewnętrznych logach i został punktowo przetestowany przez wybranych partnerów korporacyjnych na podstawie surowych umów NDA.
Obserwowane iteracje i integracja „Shallotpeat”
Droga do Garlic nie była liniowa. Wyciekłe wewnętrzne notatki dyrektora ds. badań Marka Chena sugerują, że Garlic jest w istocie kompozytem dwóch odrębnych ścieżek badawczych. Początkowo OpenAI rozwijało model o kryptonimie „Shallotpeat”, który miał być bezpośrednią inkrementalną aktualizacją. Jednak podczas pre-treningu Shallotpeat badacze odkryli nową metodę „kompresowania” wzorców rozumowania — w istocie uczenie modelu, by wcześniej w procesie treningowym odrzucał redundantne ścieżki neuronowe.
To odkrycie doprowadziło do zarzucenia samodzielnego wydania Shallotpeat. Jego architekturę połączono z bardziej eksperymentalną gałęzią „Garlic”. Rezultat to hybrydowa iteracja, która posiada stabilność dojrzałego wariantu GPT-5, ale eksplodującą efektywność rozumowania nowej architektury.
Kiedy można wnioskować o termin wydania?
Przewidywanie dat premier OpenAI jest notorycznie trudne, ale status „Code Red” przyspiesza standardowe harmonogramy. Na podstawie zbieżności przecieków, aktualizacji dostawców i cykli konkurentów można triangulować okno wydawnicze.
Główne okno: I kwartał 2026 (styczeń – marzec)
Konsensus wśród osób wtajemniczonych wskazuje na premierę w I kw. 2026. „Code Red” ogłoszono w grudniu 2025 r., z dyrektywą wydania „tak szybko, jak to możliwe”. Biorąc pod uwagę, że model jest już w fazie sprawdzania/walidacji (scalenie z „Shallotpeat” przyspieszyło harmonogram), najbardziej prawdopodobny wydaje się koniec stycznia lub początek lutego.
Wdrożenie „Beta”
Możemy zobaczyć etapowe wdrożenie:
- Koniec stycznia 2026: wydanie „preview” dla wybranych partnerów i użytkowników ChatGPT Pro (prawdopodobnie pod etykietą „GPT-5.3 (Preview)”).
- Luty 2026: pełna dostępność API.
- Marzec 2026: integracja z darmową warstwą ChatGPT (ograniczona liczba zapytań), by przeciwdziałać bezpłatnej dostępności Gemini.
3 definiujące cechy GPT-5.3?
Jeśli plotki się potwierdzą, GPT-5.3 wprowadzi zestaw funkcji, które priorytetowo traktują użyteczność i integrację nad surową kreatywnością generatywną. Zestaw funkcjonalności brzmi jak lista życzeń dla architektów systemów i deweloperów korporacyjnych.
1. Wysokiej gęstości wstępne uczenie (EPTE)
Klejnotem koronnym Garlic jest Zwiększona efektywność wstępnego uczenia (EPTE).
Tradycyjne modele uczą się, widząc ogromne ilości danych i tworząc rozległą sieć skojarzeń. Proces treningowy Garlic ma rzekomo obejmować fazę „przycinania”, w której model aktywnie kondensuje informacje.
- Efekt: Model fizycznie mniejszy (pod względem wymagań VRAM), ale zachowujący „wiedzę o świecie” znacznie większego systemu.
- Korzyść: Szybsze prędkości inferencji i znacząco niższe koszty API, adresujące „stosunek inteligencji do kosztu”, który utrudniał masową adopcję modeli takich jak Claude Opus.
2. Natywne agentowe rozumowanie
W przeciwieństwie do wcześniejszych modeli, które wymagały „wrapperów” lub złożonego inżynierii promptów, aby działać jako agenci, Garlic posiada natywne możliwości wywoływania narzędzi.
Model traktuje wywołania API, wykonywanie kodu i zapytania do baz danych jako „pełnoprawnych obywateli” swojego słownika.
- Głęboka integracja: Nie tylko „umie kodować”; rozumie środowisko kodu. Podobno potrafi nawigować po katalogu plików, edytować wiele plików jednocześnie i uruchamiać własne testy jednostkowe bez zewnętrznych skryptów orkiestracyjnych.
3. Ogromne okna kontekstu i wyjścia
Aby konkurować z milionowym oknem kontekstu Gemini, Garlic ma rzekomo oferować 400 000-tokenowe okno kontekstu. Choć mniejsze niż propozycja Google, kluczowym wyróżnikiem jest „Perfect Recall” na tym oknie, wykorzystujący nowy mechanizm uwagi, który zapobiega „utratom środka kontekstu” powszechnym w modelach z 2025 r.
- Limit wyjścia 128k: Być może bardziej ekscytujące dla deweloperów jest domniemane rozszerzenie limitu wyjścia do 128 000 tokenów. Pozwoliłoby to modelowi generować całe biblioteki oprogramowania, kompleksowe opinie prawne czy pełnowymiarowe nowele w jednym przebiegu, eliminując potrzebę „chunkowania”.
4. Drastycznie zredukowane halucynacje
Garlic wykorzystuje technikę wzmocnienia po-treningowego skoncentrowaną na „pokorze epistemicznej” — model jest rygorystycznie uczony, by wiedzieć, czego nie wie. Wewnętrzne testy pokazują odsetek halucynacji znacząco niższy niż w GPT-5.0, co czyni go realnym rozwiązaniem dla branż wysokiego ryzyka, takich jak biomedycyna i prawo.
Jak wypada na tle konkurentów, takich jak Gemini i Claude 4.5?
Sukces Garlic nie będzie mierzony w izolacji, lecz w bezpośrednim porównaniu z dwoma tytanami aktualnie rządzącymi areną: Gemini 3 od Google i Claude Opus 4.5 od Anthropic.
GPT-5.3 „Garlic” vs. Google Gemini 3
Pojedynek skali kontra gęstości.
- Gemini 3: Obecnie model „zlepek wszystkiego”. Dominuje w zrozumieniu multimodalnym (wideo, audio, natywna generacja obrazów) i ma w praktyce nieskończone okno kontekstu. To najlepszy model do „bałaganiastych” danych z realnego świata.
- GPT-5.3 Garlic: Nie może konkurować z surową multimodalną rozpiętością Gemini. Zamiast tego atakuje Gemini na czystości rozumowania. Do czystej generacji tekstu, logiki kodu i złożonego podążania za instrukcjami Garlic ma być ostrzejszy i mniej podatny na „odmowy” lub błądzenie.
- Werdykt: Jeśli musisz przeanalizować 3‑godzinne wideo, użyj Gemini. Jeśli musisz napisać backend dla aplikacji bankowej, użyj Garlic.
GPT-5.3 „Garlic” vs. Claude Opus 4.5
Bitwa o duszę dewelopera.
- Claude Opus 4.5: Wydany pod koniec 2025 r., ten model zdobył serca deweloperów „ciepłem” i „atmosferą”. Słynie z pisania czystego, zrozumiałego dla człowieka kodu i przestrzegania instrukcji systemowych z wojskową precyzją. Jednak jest drogi i wolny.
- GPT-5.3 Garlic: To bezpośredni cel. Garlic ma dorównać biegłości kodowania Opus 4.5, ale przy 2× większej szybkości i 0,5× kosztu. Dzięki „wysokiej gęstości wstępnego uczenia” OpenAI chce zaoferować inteligencję na poziomie Opus przy budżecie na poziomie Sonnet.
- Werdykt: „Code Red” został wywołany konkretnie przez dominację Opus 4.5 w kodowaniu. Sukces Garlic zależy całkowicie od tego, czy zdoła przekonać deweloperów do przełączenia kluczy API z powrotem na OpenAI. Jeśli Garlic potrafi kodować tak dobrze jak Opus, ale działa szybciej, rynek zmieni się z dnia na dzień.
Wnioski
Wczesne wewnętrzne kompilacje Garlic już przewyższają Gemini 3 od Google i Opus 4.5 od Anthropic w specyficznych, wysokowartościowych domenach:
- Biegłość w kodowaniu: W wewnętrznych „twardych” benchmarkach (poza standardowym HumanEval) Garlic wykazuje mniejszą skłonność do utknięcia w „pętlach logiki” w porównaniu z GPT-4.5.
- Gęstość rozumowania: Model potrzebuje mniej tokenów „myślenia”, by dojść do poprawnych wniosków, w bezpośrednim kontraście do „ciężkiego łańcucha myśli” serii o1 (Strawberry).
| Metryka | GPT-5.3 (Garlic) | Google Gemini 3 | Claude 4.5 |
|---|---|---|---|
| Rozumowanie (GDP-Val) | 70.9% | 53.3% | 59.6% |
| Kodowanie (HumanEval+) | 94.2% | 89.1% | 91.5% |
| Okno kontekstu | 400K Tokens | 2M Tokens | 200K Tokens |
| Szybkość inferencji | Ultraszybka | Umiarkowana | Szybka |
Konkluzja
„Garlic” to aktywna i wiarygodna plotka: ukierunkowany tor inżynieryjny OpenAI, który priorytetowo traktuje gęstość rozumowania, efektywność i rzeczywiste narzędzia. Jego pojawienie się najlepiej postrzegać w kontekście przyspieszającego wyścigu zbrojeń między dostawcami modeli (OpenAI, Google, Anthropic) — wyścigu, w którym strategiczną nagrodą jest nie tylko surowa zdolność, lecz użyteczna zdolność w przeliczeniu na dolara i milisekundę opóźnienia.
Jeśli interesuje Cię ten nowy model, obserwuj CometAPI. Zawsze aktualizuje najnowsze i najlepsze modele AI w przystępnej cenie.
Programiści mogą uzyskać dostęp do GPT-5.2 ,Gemini 3, Claude 4.5 poprzez CometAPI już teraz. Aby rozpocząć, zapoznaj się z możliwościami modeli CometAPI w Playground i skonsultuj API guide w celu uzyskania szczegółowych instrukcji. Przed uzyskaniem dostępu upewnij się, że zalogowałeś się do CometAPI i pobrałeś klucz API. CometAPI oferuje cenę znacznie niższą niż oficjalna, aby pomóc Ci w integracji.
Gotowy do działania?→ Zarejestruj się w CometAPI już dziś!
Jeśli chcesz poznać więcej wskazówek, poradników i nowości o AI, obserwuj nas na VK, X i Discord!