
.png&w=3840&q=75)
GPT-5.4 Mini i GPT-5.4 Nano to nowe kompaktowe warianty z rodziny frontier GPT-5.4 firmy OpenAI: Mini oferuje najlepszy w swojej klasie kompromis między wydajnością a opóźnieniem dla programowania, multimodalnych zadań UI i obciążeń subagentów; Nano celuje w ultra-niski koszt i opóźnienie dla klasyfikacji, ekstrakcji, rankingów oraz masowo równoległych subagentów. Mini zapewnia dokładność bliską modelom frontier w wielu benchmarkach deweloperskich, działając przy tym ponad 2× szybciej niż poprzednie modele mini; Nano jest znacząco tańszy na token i idealny tam, gdzie najważniejsze są przepustowość i responsywność. Modele są już dostępne w API (GPT 5.4 Mini i Nano są dostępne w CometAPI).
Czym są GPT-5.4 Mini i GPT-5.4 Nano?
Krótka definicja: GPT-5.4 Mini i GPT-5.4 Nano to kompaktowe, zaprojektowane warianty rodziny GPT-5.4, stworzone po to, by przenieść kluczowe zalety dużego GPT-5.4 (wnioskowanie, programowanie, percepcja multimodalna, korzystanie z narzędzi) do szybszych i tańszych modeli przeznaczonych do zadań o dużym wolumenie i niskich opóźnieniach. Modele zostały ogłoszone przez OpenAI w ramach wdrożenia GPT-5.4.
- GPT-5.4 Mini — Wydajny mały model, który „zbliża się do wydajności GPT-5.4 w kilku ewaluacjach”, jednocześnie będąc zoptymalizowanym pod kątem szybkości i niższego kosztu. Jest szczególnie wyróżniany do programowania, wnioskowania, multimodalnej interpretacji UI (zrzuty ekranu) oraz jako subagent w systemach agentowych. OpenAI podaje, że działa ponad 2× szybciej niż poprzednie warianty „mini”.
- GPT-5.4 Nano — Najmniejszy i najtańszy wariant GPT-5.4; rekomendowany do klasyfikacji, ekstrakcji, rankingów oraz „wspierających” subagentów wykonujących wąskie, powtarzalne zadania przy bardzo wysokiej przepustowości. Oferuje mniejsze możliwości głębszego wnioskowania w zamian za niższe opóźnienia i oszczędność kosztów.
Dostępność i cena
OpenAI podaje dwa konkretne punkty odniesienia, których można użyć do porównania kosztów:
- GPT-5.4 (pełny flagowy model) cena wejścia API: $2.50 / 1M tokenów (oraz wyższa cena wyjścia dla modelu flagowego).
- GPT-5.4 mini cena wejścia API: $0.75 / 1M tokenów oraz wyjścia $4.50 / 1M tokenów.
- GPT-5.4 nano cena wejścia API: $0.20 / 1M oraz wyjścia $1.25 / 1M.
Porównując to obok siebie: cena tokena wejściowego mini (0.75) to 30% ceny modelu flagowego (2.50), czyli mniej więcej jedna trzecia kosztu wejścia; cena wyjścia mini (4.50) to około 32% ceny wyjścia modelu flagowego podanej w tabeli cen API, czyli również około jednej trzeciej. Nano jest jeszcze tańszy: jego koszt wejścia to około 8% kosztu wejścia modelu flagowego, a koszt wyjścia to poniżej 10% kosztu wyjścia modelu flagowego. Właśnie dlatego OpenAI opisuje mini/nano jako modele kosztujące „około jednej trzeciej” (mini) i „ułamek” (nano) kosztu używania największych modeli do zadań wielkoskalowych. Cena tokena nano wzrosła z $0.05 do $0.20, a cena tokena mini wzrosła z $0.25 do $0.75 (dla tokenów wejściowych).
Na platformie OpenAI
GPT-5.4 mini jest dostępny w trzech miejscach: API OpenAI, Codex (platforma IDE/aplikacja deweloperska OpenAI) oraz ChatGPT (dostępny dla użytkowników Free i Go przez opcję „Thinking” oraz jako fallback przy limitach dla płatnych planów). W API obsługuje wejścia tekstowe i obrazowe, korzystanie z narzędzi (function calling), wyszukiwanie w sieci/plikach, computer use oraz skills — a także oferuje bardzo duże okno kontekstowe (400k tokenów), aby obsługiwać przepływy pracy oparte na dokumentach i wielu zrzutach ekranu. Cennik API to $0.75 za 1M tokenów wejściowych i $4.50 za 1M tokenów wyjściowych.
GPT-5.4 nano jest dostępny wyłącznie przez API. Jego ceny katalogowe to $0.20 za 1M tokenów wejściowych oraz $1.25 za 1M tokenów wyjściowych — co pozycjonuje go jako najtańszy wariant w rodzinie GPT-5.4. Model nano świadomie rezygnuje z części możliwości na rzecz kosztu i szybkości.
Na platformie zewnętrznej
CometAPI to multimodalna platforma agregująca API AI, która uruchomiła już API serii GPT 5.4, w tym GPT 5.4 Mini i GPT 5.4 Nano, w cenie o 20% niższej niż cena OpenAI.
GPT 5.4 Nano:
| Cena Comet (USD / M tokenów) | Cena oficjalna (USD / M tokenów) |
|---|---|
| Wejście:$0.16/M; Wyjście:$1/M | Wejście:$0.2/M; Wyjście:$1.25/M |
GPT 5.4 Nano:
| Cena Comet (USD / M tokenów) | Cena oficjalna (USD / M tokenów) |
|---|---|
| Wejście:$0.6/M; Wyjście:$3.6/M | Wejście:$0.75/M; Wyjście:$4.5/M |
Kluczowe funkcje i nowości
Poniżej przedstawiono najważniejsze możliwości — czyli to, dlaczego inżynierowie i zespoły produktowe zwrócą na nie uwagę.
Kodowanie i obsługa długiego kontekstu
Okno kontekstowe: GPT-5.4 mini obsługuje okno kontekstowe o wielkości 400k tokenów (OpenAI wyraźnie podaje dla mini kontekst 400k). To wystarcza do pracy z wieloma plikami kodu, rozbudowanymi dokumentami albo wieloturowymi sesjami agentów, w których kontekst ma znaczenie. Kontekst Nano jest mniejszy względem pełnego GPT-5.4, ale nadal znaczący dla szybkich, krótkich zadań.
Wnioskowanie
Poziomy wnioskowania: OpenAI udostępnia konfigurowalne reasoning_effort (none → xhigh); mini i nano mogą działać z różnym poziomem wysiłku wnioskowania, ale przy wyższym poziomie mini zmniejsza dystans do pełnego GPT-5.4 w wielu benchmarkach rozumowania. W kilku benchmarkach inteligencji (np. GPQA Diamond) mini osiąga 88.0% wobec 93.0% dla GPT-5.4, a nano uzyskuje 82.8%, co wskazuje na solidne wnioskowanie jak na mały model. To wyniki opublikowane przez OpenAI w poście premierowym.
Rozumienie multimodalne (wizja i UI)
Percepcja wizualna i zadania UI: GPT-5.4 mini pokazuje bardzo mocne wyniki multimodalne w zadaniach UI (zrzuty ekranu, gęste obrazy dokumentów). W OSWorld-Verified (benchmark computer use) mini osiąga 72.1%, znacznie bliżej wyniku GPT-5.4 wynoszącego 75.0% i zdecydowanie powyżej wcześniejszych modeli mini — dlatego mini pozycjonowany jest do automatyzacji opartych na zrzutach ekranu i responsywnych asystentów multimodalnych. Nano uzyskuje słabsze wyniki w benchmarkach wizualnych, ale nadal jest użyteczny w prostszych zadaniach obrazowych.
Wywoływanie narzędzi i computer use
Natywne możliwości narzędzi/click: GPT-5.4 wprowadza i rozwija natywne narzędzia computer use; mini dziedziczy możliwość wywoływania narzędzi, wykonywania function calling, interpretacji zrzutów ekranu i orkiestracji subagentów. Benchmarki wywołań narzędzi (Toolathlon, MCP Atlas) pokazują, że mini i nano osiągają przyzwoite wyniki (Toolathlon: mini 42.9%, nano 35.5%) — co ilościowo opisuje ich zdolność do wywoływania i koordynowania zewnętrznych narzędzi. Te metryki pochodzą z ogłoszenia OpenAI.
Halucynacje / zgodność z faktami / wskaźniki błędów
OpenAI podaje, że GPT-5.4 jest „jak dotąd najbardziej zgodnym z faktami modelem” i wykazuje spadek liczby halucynacji względem GPT-5.2; mini i nano mają niższą bezwzględną zgodność z faktami niż pełny model (np. HLE z narzędziami: GPT-5.4 52.1%, mini 41.5%, nano 37.7%), co sugeruje większą potrzebę weryfikacji, gdy mniejsze modele są używane do zadań wymagających wysokiej poprawności faktograficznej. Gdy poprawność ma znaczenie, należy stosować weryfikację opartą na narzędziach (wywołania narzędzi, przywoływanie cytowań).
Szybkość
OpenAI podaje, że GPT-5.4 mini działa ponad 2× szybciej niż wcześniejszy GPT-5 mini według typowych estymacji opóźnień w stylu produkcyjnym (opartych na symulowanym zachowaniu produkcyjnym obejmującym czas wywołań narzędzi i próbkowane tokeny). To przyspieszenie jest kluczową obietnicą nowej rodziny i właśnie ono pozwala używać mini jako responsywnego subagenta wewnątrz interaktywnych aplikacji, takich jak asystenci programowania.
Jak wypadają mini i nano — czy „zbliżają się” do pełnego GPT-5.4?
OpenAI opublikowało obszerny zestaw porównań benchmarkowych obejmujących programowanie, korzystanie z narzędzi, multimodalne zadania computer use, testy inteligencji i ewaluacje długiego kontekstu. Najważniejsze wyniki (tam, gdzie dotyczy, przy reasoning effort xhigh) obejmują:
| Benchmark | GPT-5.4 | GPT-5.4 Mini | GPT-5.4 Nano | GPT-5 Mini (stary) | Uwagi |
|---|---|---|---|---|---|
| SWE-Bench Pro (programowanie) | 57.7% | 54.4% | 52.4% | 45.7% | Mini zbliża się do pełnego modelu w kodowaniu |
| Terminal-Bench 2.0 (interaktywne kodowanie) | 75.1% | 60.0% | 46.3% | — | Silne możliwości kodowania w czasie rzeczywistym dla Mini |
| Toolathlon (użycie narzędzi) | 54.6% | 42.9% | 35.5% | — | Mierzy orkiestrację i wywoływanie narzędzi |
| GPQA Diamond (zaawansowane QA) | 93.0% | 88.0% | 82.8% | — | Benchmark inteligencji i wnioskowania |
| OSWorld-Verified (zadania GUI) | 75.0% | 72.1% | 39.0% | 42.0% | Możliwości UI/computer use |
Te liczby pokazują, że mini często znacząco zmniejsza dystans — zwłaszcza w zadaniach programistycznych i computer use — podczas gdy nano zajmuje użyteczny środek między możliwościami a kosztem.
Co te liczby oznaczają prostym językiem?
- GPT-5.4 Mini ≈ „niemal flagowy” w wielu zadaniach produkcyjnych. W SWE-Bench Pro (metryka skuteczności w programowaniu) mini osiąga 54.4% wobec 57.7% modelu flagowego — to niewielka względna różnica dla wielu rzeczywistych zadań programistycznych, szczególnie gdy liczy się opóźnienie. W OSWorld (computer use) mini ma 72.1% wobec 75.0% modelu flagowego — znów bardzo blisko w zadaniach UI/opartych na zrzutach ekranu.
- GPT-5.4 Nano poświęca więcej możliwości na rzecz szybkości/kosztu. Wynik Nano w programowaniu (52.4% w SWE-Bench Pro) jest solidny względem starszych modeli mini, ale jego wynik OSWorld spada do 39.0%, co pokazuje, że do zadań wymagających złożonego, wieloetapowego rozumienia UI albo agentowych sekwencji narzędzi nano nadaje się mniej. Nano najlepiej sprawdza się w jednokrokowej klasyfikacji, ekstrakcji i małych zadaniach pomocniczych.
- Użycie narzędzi się poprawia, ale nadal pozostaje wrażliwe. Toolathlon i inne metryki użycia narzędzi znacząco rosną przy przejściu z GPT-5 mini na GPT-5.4 mini/nano, co pokazuje, że OpenAI poprawiło niezawodność wywoływania narzędzi w mniejszych modelach — ale pełny model nadal prowadzi w złożonej orkiestracji narzędzi.
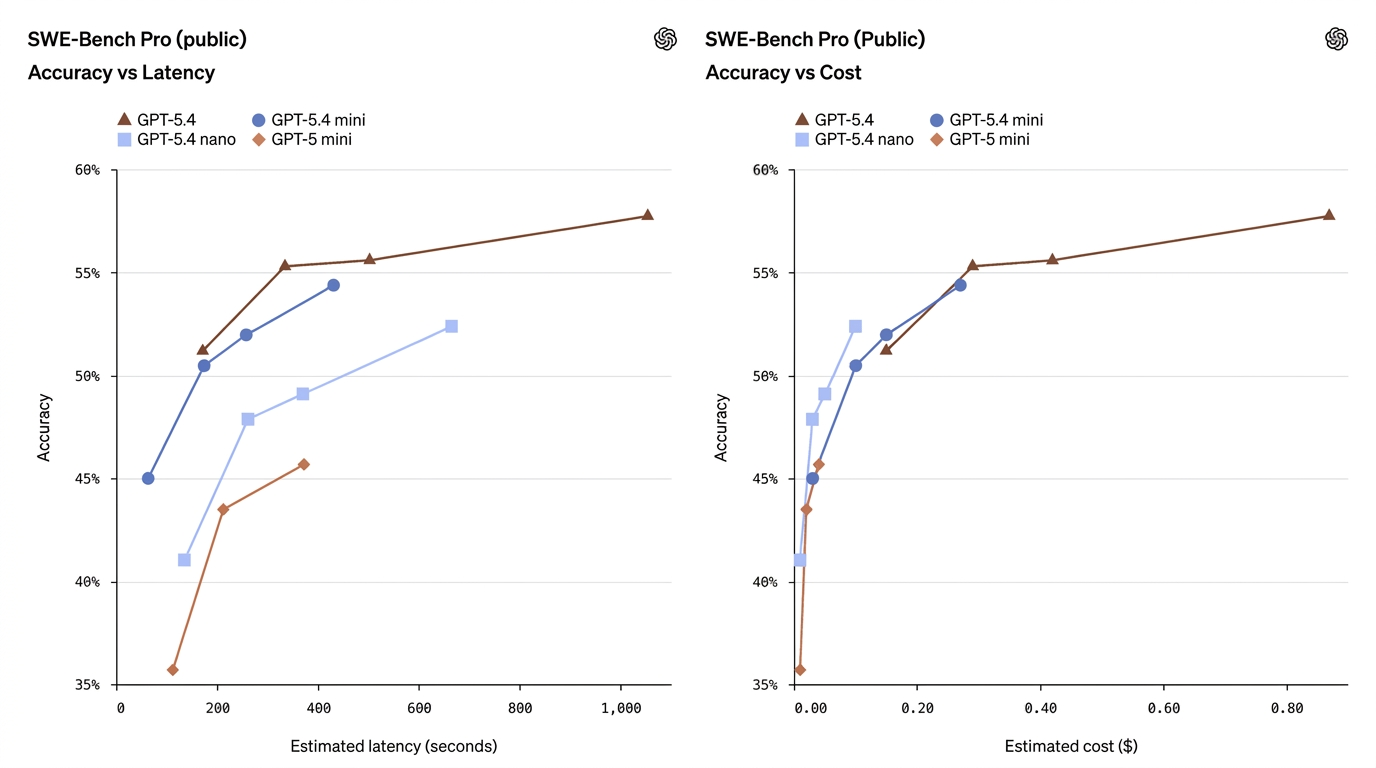
Jak działają w środowisku produkcyjnym
Kompresja, dystylacja i optymalizacje inżynieryjne
Kompaktowe modele, takie jak mini/nano, zwykle wykorzystują kombinację dystylacji modelu, kwantyzacji i przycinania architektury, aby zachować najbardziej wartościowe możliwości (heurystyki kodowania, percepcję wizualną), jednocześnie redukując koszt obliczeniowy inferencji. Sformułowania OpenAI wskazują na ukierunkowane prace inżynieryjne mające zachować konkretne zestawy umiejętności (programowanie, multimodalne rozumienie UI) w mniejszych wariantach.
Zalecane wzorce
- Wzorzec orkiestrator + subagent: Użyj GPT-5.4 (dużego) jako planisty/sędziego i deleguj pracę do subagentów GPT-5.4 mini / nano do szybkiego wykonania (wyszukiwanie, parsowanie, edycja). To obniża całkowity koszt i zmniejsza opóźnienie dla użytkownika. OpenAI wyraźnie rekomenduje ten wzorzec projektowy.
- Fallback i obsługa limitów: Udostępnij mini jako fallback przy limitach w ChatGPT lub Codex, aby zapytania wrażliwe na czas nadal otrzymywały kompetentną odpowiedź, gdy pełny model jest niedostępny.
- Architektura warstwowa dla kontroli kosztów: Pipeline’y masowe (indeksowanie, ekstrakcja) → GPT-5.4 nano; interaktywne komponenty UI → GPT-5.4 mini; końcowy osąd redakcyjny / złożone łańcuchy → pełny GPT-5.4. Takie wielowarstwowe podejście równoważy koszt i możliwości.
Opóźnienie i równoległość
Mini i nano są zoptymalizowane pod kątem równoległych subagentów, gdzie wielu małych wykonawców działa jednocześnie — np. skanując tysiące PDF-ów równolegle. Koncepcja OpenAI „tool yields” mierzy, jak równoległe wywołania narzędzi zmniejszają opóźnienie ściany czasowej; mini/nano zostały zaprojektowane tak, aby takie wzorce były opłacalne kosztowo.
Jak używać mini i nano w praktyce
Czy powinienem wszędzie zastąpić wywołania modelu flagowego przez mini/nano?
Nie automatycznie. Właściwym wzorcem, który OpenAI wyraźnie rekomenduje, jest delegowanie: używaj większego modelu do planowania, złożonego osądu albo końcowej weryfikacji, a wiele wspierających, krótszych podzadań przekazuj subagentom mini lub nano. Ten wzorzec obniża koszt i opóźnienie, jednocześnie zachowując zabezpieczenia większego modelu tam, gdzie mają największe znaczenie. Przykłady zastosowań:
- Interaktywni asystenci programowania: model flagowy planuje i recenzuje; mini obsługuje szybkie wyszukiwanie kodu, edycje i krótkie testy jednostkowe.
- Agenci „computer use” oparci na zrzutach ekranu: mini może szybko analizować złożone interfejsy; model flagowy rozwiązuje niejednoznaczne wieloetapowe planowanie.
- Wielkoskalowe pipeline’y ekstrakcji i klasyfikacji: nano przetwarza ogromne wsady wejść (formularze, logi) i zwraca wyniki strukturalne; model flagowy obsługuje wyjątki i złożone przypadki brzegowe.
Czy mini lub nano można używać do zadań multimodalnych lub obrazowych?
Tak — mini obsługuje wejścia obrazowe i dobrze wypada w benchmarkach opartych na multimodalności/wizji (MMMUPro/OmniDocBench), zbliżając się w niektórych testach do modelu flagowego. Siła multimodalna Nano jest bardziej ograniczona: chociaż wypada lepiej niż wcześniejsze modele nano, nie jest to najlepszy wybór do głębokiego multimodalnego wnioskowania ani agentowych zadań opartych na obrazach.
Wyścig o możliwości małych modeli przyspieszył
Jeszcze trzy miesiące temu małe modele były uznawane za „wystarczająco dobre”. Teraz GPT-5.4 mini zbliża się do modeli flagowych w benchmarkach programistycznych i niemal dorównuje im pod względem wydajności obliczeniowej.
Trend stojący za tym zjawiskiem jest jasny: możliwości modeli flagowych są szybko przenoszone do mniejszych modeli. OpenAI, Google i Anthropic robią dokładnie to samo: destylują kluczowe możliwości dużych modeli do mniejszych, szybszych i tańszych wersji.
Podsumowanie
Premiera tych dwóch modeli oznacza przesunięcie w zastosowaniach AI: z koncentracji na skali w stronę praktycznej efektywności. Dzięki szybkim czasom odpowiedzi zapewniają bardziej niezawodne zaplecze dla interakcji AI w czasie rzeczywistym i dla rozbijania złożonych przepływów zadań.
Dla deweloperów oznacza to redefinicję struktury kosztów systemów agentowych. Gdy koszty spadają do tego poziomu, wiele scenariuszy agentowych, które wcześniej były „teoretycznie wykonalne, ale ekonomicznie nieopłacalne”, staje się realnych.
Deweloperzy mogą już uzyskać dostęp do GPT 5.4 Mini i GPT-5.4 Nano przez CometAPI (CometAPI to kompleksowa platforma agregująca API dużych modeli, takich jak GPT APIs, Nano Banana APIs itd.). Przed uzyskaniem dostępu upewnij się, że zalogowano się do CometAPI i uzyskano klucz API. CometAPI oferuje cenę znacznie niższą od oficjalnej, aby ułatwić integrację.
Gotowy do działania?