

xAI po cichu wydane Grok 4.1 (17–18 listopada 2025 r.) — ukierunkowana aktualizacja Grok 4, która priorytetowo traktuje inteligencja emocjonalna, ekspresja twórcza i zmniejszone halucynacje Zachowując przy tym precyzję i precyzję poprzednich wydań Grok. Dostępny jest w dwóch trybach (Thinking/Non-Thinking), został po cichu wprowadzony na rynek na początku listopada, prezentuje najlepsze wyniki w rankingu LMArena i jest dostępny za pośrednictwem grok.com, aplikacji Grok i API.
Czym jest Grok 4.1?
Grok 4.1 to przyrostowy, skoncentrowany na produkcji następca Groka 4: członek rodziny zbudowany na tym samym fundamencie uczenia wzmacniającego na dużą skalę, ale dopracowany i ponownie wytrenowany z intensywnymi optymalizacjami po treningu, ukierunkowanymi na styl, osobowość, dopasowanie i niezawodność w realnym świecie. Jest pozycjonowany jako pragmatyczny, „użyteczny” krok naprzód: inteligentniejszy w ślepych testach preferencji, bardziej inteligentny emocjonalnie, lepszy w kreatywnym pisaniu i mierzalnie mniej podatny na pewne siebie, ale błędne „halucynacje”, które nękały wcześniejszych, wysoko radzących sobie studentów prawa (LLM).
Grok 4.1 pozwala na osiągnięcie jakościowych zmian w następujących czterech wymiarach:
- Kreatywność: Wykazuje silniejsze posłużenie się językiem i wyobraźnią w pisaniu, opowiadaniu historii i kontekstach społecznych;
- Inteligencja emocjonalna: rozpoznaje ton i zmiany emocjonalne, reaguje z bardziej ludzką logiką emocjonalną i formułuje uspokajające i pełne zrozumienia odpowiedzi;
- Spójność osobowości: zachowuje spójny ton i osobowość podczas długich rozmów, nie wykazując już niespójnego zachowania charakterystycznego dla wcześniejszych modeli;
- Współpraca: zachowuje spójność i świadomość celu w dialogach wieloetapowych lub podczas współpracy nad zadaniami.
xAI podsumowuje swoje cechy w jednym zdaniu: „Jest bardziej spostrzegawczy, bardziej empatyczny i bardziej przypomina spójną osobę”.
Jak Grok 4.1 działa pod maską?
Grok 4.1 można najlepiej rozumieć jako ten sam wstępnie wyszkolony szkielet, który jest używany w całej rodzinie Grok 4, plus warstwowy proces poszkoleniowy, który koncentruje się na modelowanie nagród, dopasowanie stylu i ewaluatorzy agentyczni.
Jakie są etapy szkolenia i dopasowania?
Grok 4.1 działa w oparciu o wieloetapowy proces typowy dla nowoczesnych programów LLM, dostosowany do wersji 4.1 poprzez wprowadzenie dwóch ważnych zmian:
- Przedtreningowo + w trakcie treningu: Obszerny korpus wstępny do trenowania na danych internetowych + ukierunkowany trening w trakcie treningu w celu zwiększenia wiedzy dziedzinowej i możliwości multimodalnych.
- Nadzorowane dostrajanie (SFT): Demonstracje pożądanych zachowań przez ludzi (odpowiedzi, strategie odmowy).
- Modelowanie nagród (nowe zastosowanie): xAI wytrenował modele nagród nie tylko na podstawie ludzkich preferencji, ale także wykorzystał je modele wnioskowania agentowego na pograniczu jako osoby oceniające nagrody – skutecznie umożliwiając wysoko wykwalifikowanym ewaluatorom opartym na modelach ocenianie wyników kandydatów na dużą skalę. Umożliwiło to optymalizację nieweryfikowalnych atrybutów, takich jak styl, spójność osobowości, empatia i pomocność bez konieczności przeznaczania niemożliwie dużego budżetu na etykietowanie.
- Optymalizacja polityki (RLHF / RL z nagród modelowych): Standardowa optymalizacja polityki z wykorzystaniem poznanych sygnałów nagrody w celu wytworzenia wdrożonej polityki (model, z którym wchodzą w interakcję konsumenci).
Co nowego w podejściu do modelowania nagród?
W tradycyjnym modelu RLHF zbiera się ludzkie etykiety preferencji (A/B), trenuje się model nagrody, aby je przewidywać, a następnie optymalizuje się model bazowy za pomocą RL (lub próbkowania odrzucenia) pod kątem tej wyuczonej nagrody. Dwie praktyczne innowacje, które xAI podkreśla:
- Modele nagród agentów: Zamiast wyłącznie ludzkich sędziów, xAI wykorzystało sprawne modele rozumowania „agentowego” jako systemy oceniające, aby oceniać subtelniejsze właściwości (ton, niuanse emocjonalne, kreatywność). Systemy oceniające mogą szybko przeprowadzać tysiące porównań parami, umożliwiając inżynierom szybszą iterację. To mechanizm, który zapewnia znaczące ulepszenia w zakresie stylu i inteligencji emocjonalnej.
- Wyrównanie po treningu dla sygnałów nieweryfikowalnych: w przypadku atrybutów, których nie można zmierzyć za pomocą metryki deterministycznej (np. „ciepło” lub „spójna osobowość”) wprowadzono specjalistyczne cele dotyczące nagród i skalowania programów nauczania, dzięki czemu model uczy się styl wyników bez poświęcania podstawowej dokładności faktów.
Jak technicznie działa „myślenie” i „niemyślenie”?
- Grok 4.1 Myślenie (nazwa kodowa
quasarflux) — ujawnia jawne kroki rozumowania (tokeny myślowe) przed wygenerowaniem ostatecznej odpowiedzi; zoptymalizowane pod kątem złożonych zadań i wyższych ELO w LMArena. Dodatkowe tokeny skracają czas wnioskowania, ale pomagają w wieloetapowych zadaniach rozumowania, debugowaniu i wyjaśnianiu. - Grok 4.1 Niemyślący (nazwa kodowa
tensor) Omija jawne tokeny pośrednie, aby uzyskać pojedynczą, natychmiastową odpowiedź końcową. Zmniejsza to opóźnienie i koszt tokena, a jednocześnie korzysta z tych samych, udoskonalonych wag polityki. Tryb bezmyślności został zoptymalizowany pod kątem wyjątkowo niskiego opóźnienia i jednocześnie dużej wydajności.
Optymalizacja dopasowania sentymentu i stylu
Poza prostymi sygnałami „prawdziwości”, Grok 4.1 obejmuje ukierunkowaną optymalizację dopasowania do nastroju, tonu i stylu interpersonalnego. Oznacza to, że proces treningowy obejmuje komponenty nagrody lub straty, które wyraźnie karzą niedopasowany ton (np. niepotrzebnie oschły ton, gdy empatia jest wskazana) oraz nagradzają reakcje zgodne z pożądanym stylem lub profilem sentymentu. W Grok 4.1 sztuczna inteligencja po raz pierwszy wprowadziła cel optymalizacji, jakim jest „dopasowanie osobowości”.
Celem jest pomoc modelowi w utrzymaniu spójnego i stabilnego poczucia tożsamości. W porównaniu z Grok 4, 4.1 dodaje do celów szkoleniowych następujące elementy:
- Nagrody pozytywne za wymiar ekspresji emocjonalnej (nagroda za wyrównanie emocjonalne);
- Wskaźnik spójności osobowości.
Jak oceniano Grok 4.1 i jak się sprawdził?
Co wykazały ślepe testy preferencji u ludzi?
Podczas cichego wdrożenia Grok 4.1 był preferowany w 64.78% przypadków w porównaniu z poprzednim modelem produkcyjnym w rzeczywistym ruchu — jest to wyraźny sygnał preferencji użytkownika wskazujący na lepsze wyniki konwersacji w warunkach rzeczywistych.
Czy Grok 4.1 jest na szczycie rankingów?
xAI informuje, że Grok 4.1 Myślący tryb znajduje się w #1 na arenie tekstowej LMArena, z podawanym ELO wynoszącym 1483, a jego tryb bezrozumny (szybki) plasuje się na 2. miejscu z wynikiem ELO 1465 — wysoka pozycja w publicznych rankingach zarówno pod względem dokładności, jak i prezentacji (kontrola stylu odgrywa rolę).
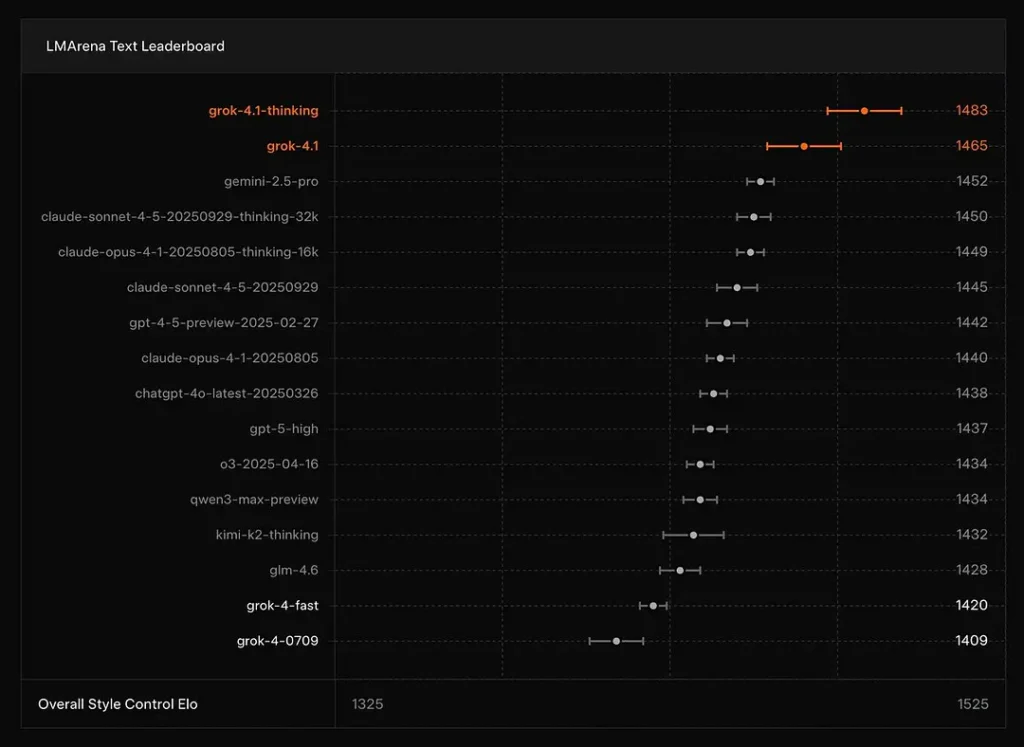
Wnioski: Grok 4.1 przewyższa główne modele serii GPT-4.5 i Claude pod względem rozumienia tekstu, generowania tekstu i ogólnej jakości, ustępując jedynie wersji GPT-5 Advanced Preview.
Inteligencja emocjonalna
xAI przeprowadziło EQ-Bench3, specjalistyczny test inteligencji emocjonalnej obejmujący 45 trudnych scenariuszy odgrywania ról, i podaje, że Grok 4.1 wykazuje znaczną poprawę empatii, tempa i wglądu interpersonalnego. Grok 4.1 uzyskał najwyższe wyniki w rozumieniu kontekstów smutku, empatii i komfortu.

Twórcze pisanie — czy rzeczywiście jest bardziej pomysłowe?
Grok 4.1 został oceniony na Kreatywne pisanie v3 (32 podpowiedzi w 3 iteracjach z rubryką i punktacją ELO). xAI twierdzi, że styl pisania, spójność głosu i kreatywność narracji w wersji 4.1 znacząco wzrosły, plasując ją w czołówce ostatnich rankingów zadań kreatywnych (przykładowe podpowiedzi znajdują się w publikacji). Niezależne raporty potwierdziły te wyniki: recenzenci zauważyli wyraźnie bardziej „charakterystyczny głos” i lepszą spójność dłuższych form. Pod względem jakości pisania Grok 4.1 ustępuje jedynie modelom z serii GPT-5 i przewyższa wszystkie linie produktów Claude, Gemini i Kimi.

Zmniejszona halucynacja / uczciwość
xAI twierdzi, że nastąpiła zauważalna redukcja częstości występowania halucynacji: podali (w ogłoszeniu i postach w mediach społecznościowych), że Grok 4.1 to ~3 razy mniejsze prawdopodobieństwo wystąpienia halucynacji W porównaniu z wcześniejszymi modelami Groka, powołując się na analizy ruchu produkcyjnego i oceny w stylu FActScore (np. zestawy pytań biograficznych/biograficznych – im niższy wynik, tym lepiej). Szczególnie w „trybie bezrozumowym”, gdzie dostępne są zewnętrzne narzędzia wyszukiwania, spójność faktów jest bardziej stabilna.

Dlaczego Grok 4.1 „miażdży” inne modele — czy to przesada?
„Crushes” to określenie marketingowe, ale kryje w sobie obiektywne twierdzenia:
- Tabele wyników: Grok 4.1 zajmuje czołowe miejsca w publicznych rankingach LMArena za generowanie tekstu (1483 ELO w trybie myślenia) oraz wysokie wyniki w kategorii kreatywności i EQ według wydania xAI. Są to porównywalne wskaźniki konkurencji stosowane w całej społeczności.
- Wygrywają preferencje dotyczące rzeczywistego ruchu: xAI zgłasza przewagę preferencji ludzkich w ślepych porównaniach (~65% preferencji w porównaniu z poprzednim modelem produkcyjnym) po cichym wdrożeniu na rzeczywistym ruchu. Odzwierciedla to usprawnienia wprowadzane przez rzeczywistych użytkowników, a nie tylko testy porównawcze.
- Praktyczna nowa możliwość: Połączenie oceniania modeli, RL na podstawie sygnałów nieweryfikowalnych i bardziej rygorystycznych filtrów wejściowych to pragmatyczny krok inżynieryjny, który bezpośrednio poprawia doświadczenia użytkownika w zadaniach konwersacyjnych, empatycznych i kreatywnych, w których konkurencja historycznie wypada słabo.
Tak więc, chociaż „miażdżenie” to barwny sposób na powiedzenie „wiodące wyniki w wielu publicznych i wewnętrznych ocenach”, podstawowe publiczne wskaźniki opublikowane przez xAI potwierdzają ten wniosek
Jak uzyskać dostęp do Grok 4.1
Dostęp konsumencki/aplikacyjny
xAI okresowo udostępniało Grok 4.1 w trybie „Auto” za darmo lub w ramach promocji, jednak poziomy premium (SuperGrok, SuperGrok Heavy) i dostęp do API z wyższymi limitami istnieją i pozostają płatne.
Grok 4.1 jest dostępny dla wszystkich użytkowników on grok.com, **X (dawniej Twitter)**oraz aplikacje Grok na systemy iOS i Android, które są od razu wdrażane w trybie automatycznym, a także można je wybrać jawnie jako „Grok 4.1” w selektorze modeli.
Dostęp do API i plany dla programistów
Punkty końcowe Grok 4.1 są dostępne za pośrednictwem interfejsu API xAI. W chwili publikacji tego artykułu oficjalne API GPT 4.1 nie zostało jeszcze wydane.
Interfejs API Comet obiecuje śledzić najnowszą dynamikę modelu, w tym Grok 4.1 API, która ukaże się równocześnie z oficjalną premierą. Prosimy o cierpliwość i śledzenie rozwoju CometAPI. W oczekiwaniu na tę aktualizację, warto zwrócić uwagę na inne modele Groka, takie jak: Grok-code-fast-1 oraz Grok 4, poznaj ich możliwości w Playground i zapoznaj się z przewodnikiem API, aby uzyskać szczegółowe instrukcje dotyczące wywołania. Przed uzyskaniem dostępu upewnij się, że zalogowałeś się do CometAPI i uzyskałeś klucz API.
Praktyczne wskazówki dotyczące korzystania z Grok 4.1 w środowisku produkcyjnym
Jak zmniejszyć ryzyko halucynacji
- Włącz wyszukiwanie na żywo lub zweryfikowany łańcuch narzędzi do wyszukiwania informacji.
- Podaj kroki weryfikacji:poproś modelkę o podanie źródeł i dowodów na poparcie twierdzeń faktycznych; użyj
responsemetadane umożliwiające sprawdzenie cytowań (jeśli są dostępne). - Uruchom deterministyczne kontrole (weryfikacja faktów LLM, walidatory ustrukturyzowanych danych) jako etap przetwarzania końcowego w przypadku wyników o dużym znaczeniu.
Jak kontrolować ton i styl
- Stosuj wyraźne komunikaty systemowe, aby poprawić swój ton głosu („Jesteś formalny i empatyczny.”).
- Użyj nadzorowanych monitów i małych szablonów lokalnych, aby zapewnić spójny komunikat głosowy we wszystkich aplikacjach.
- Jeśli to możliwe, korzystaj z opcji sterowania stylem xAI i pokręteł sterujących opartych na nagrodach.
Ostateczny werdykt: czy Grok 4.1 to prawdziwa rewolucja?
Grok 4.1 jest nie zupełnie nowa architektura; raczej jest to wyrafinowana i przemyślana po treningu / wyrównanie wydanie skupiające się na tym, co naprawdę interesuje ludzi na czacie: osobowość, inteligencja emocjonalna, kreatywność i mniej błędów rzeczowychWymierne korzyści w rankingach, preferencje dotyczące ruchu drogowego na dużą skalę i ulepszone narzędzia bezpieczeństwa. W przypadku aplikacji, które wymagają wysokiej jakości rozmów, kreatywnej współpracy lub pomocy z tonem głosu, Grok 4.1 to duży krok naprzód, a w kilku testach porównawczych społeczności był najlepszym rozwiązaniem w momencie premiery.
CometAPI to komercyjna platforma agregacji API, która zapewnia programistom ujednolicony, w stylu OpenAI, dostęp REST do setek modeli AI od wielu dostawców – tekstowych modeli LLM, generatorów obrazów/wideo, osadzeń i innych – za pośrednictwem jednego, spójnego interfejsu. Zamiast łączyć oddzielne zestawy SDK lub dedykowane punkty końcowe dla OpenAI, Anthropic, Google, Meta lub mniejszych wyspecjalizowanych dostawców modeli, CometAPI pozwala wywoływać różne modele poprzez zmianę ciągów znaków i kilku parametrów.
Gotowy spróbować?→ Zarejestruj się w CometAPI już dziś !
Jeśli chcesz poznać więcej wskazówek, poradników i nowości na temat sztucznej inteligencji, obserwuj nas na VK, X oraz Discord!