
grok-code-fast-1 to szybkościowo zorientowany, opłacalny kosztowo agentowy model kodowania xAI, zaprojektowany do zasilania integracji z IDE i zautomatyzowanych agentów kodujących. Kładzie nacisk na niską latencję, zachowania agentowe (wywołania narzędzi, ślady krokowego rozumowania) oraz korzystny profil kosztowy w codziennych przepływach pracy deweloperów.
Kluczowe funkcje (w skrócie)
- Wysoka przepustowość / niska latencja: skupiony na bardzo szybkim wypisywaniu tokenów i szybkich zakończeniach dla zastosowań w IDE.
- Agentowe wywoływanie funkcji i narzędzi: obsługuje wywołania funkcji i orkiestrację narzędzi zewnętrznych (uruchamianie testów, linterów, pobieranie plików) umożliwiając wieloetapowe agentowe przepływy kodowania.
- Duże okno kontekstu: zaprojektowany do obsługi dużych baz kodu i kontekstów wieloplikowych (w adapterach marketplace dostawcy wymieniają okna kontekstu 256k).
- Widoczne rozumowanie / ślady: odpowiedzi mogą zawierać krokowe ślady rozumowania, aby decyzje agenta były możliwe do inspekcji i debugowania.
Szczegóły techniczne
Architektura i trening: xAI podaje, że grok-code-fast-1 został zbudowany od podstaw w oparciu o nową architekturę i korpus pretreningowy bogaty w treści programistyczne; następnie model przeszedł kurację potreningową na wysokiej jakości, rzeczywistych zbiorach danych z pull requestów i kodu. Ten łańcuch inżynieryjny ma uczynić model praktycznym w przepływach agentowych (IDE + użycie narzędzi).
Serwowanie i kontekst: grok-code-fast-1 i typowe wzorce użycia zakładają strumieniowe wyjścia, wywołania funkcji oraz bogate wstrzykiwanie kontekstu (przesyłanie kolekcji/plików). W wielu chmurowych marketplace’ach i adapterach platform jest już wymieniany z dużym wsparciem kontekstu ( 256k kontekstów w niektórych adapterach).
Funkcje użyteczności: Widoczne ślady rozumowania (model ujawnia planowanie/użycie narzędzi), wskazówki dotyczące inżynierii promptów i przykładowe integracje oraz wczesne integracje partnerskie (np. GitHub Copilot, Cursor).
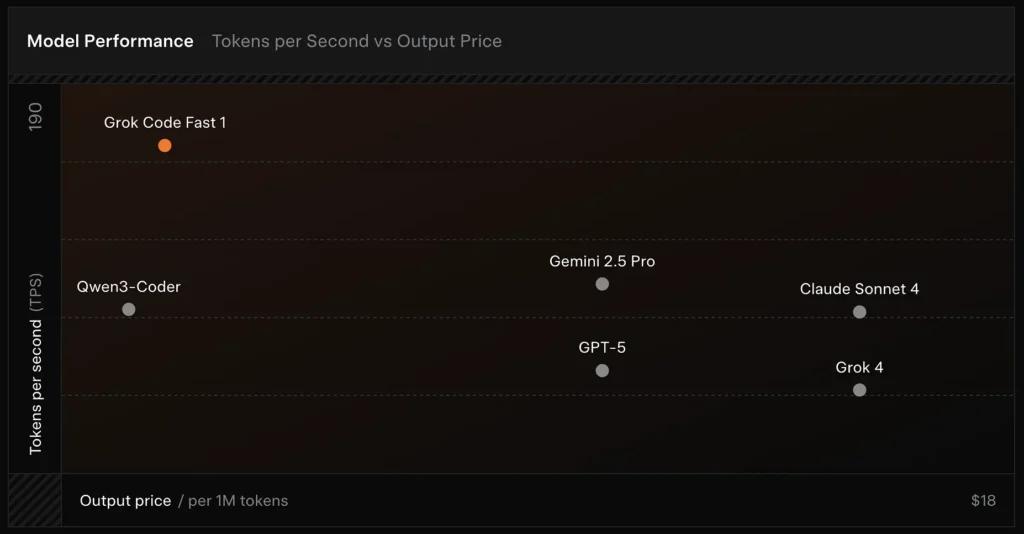
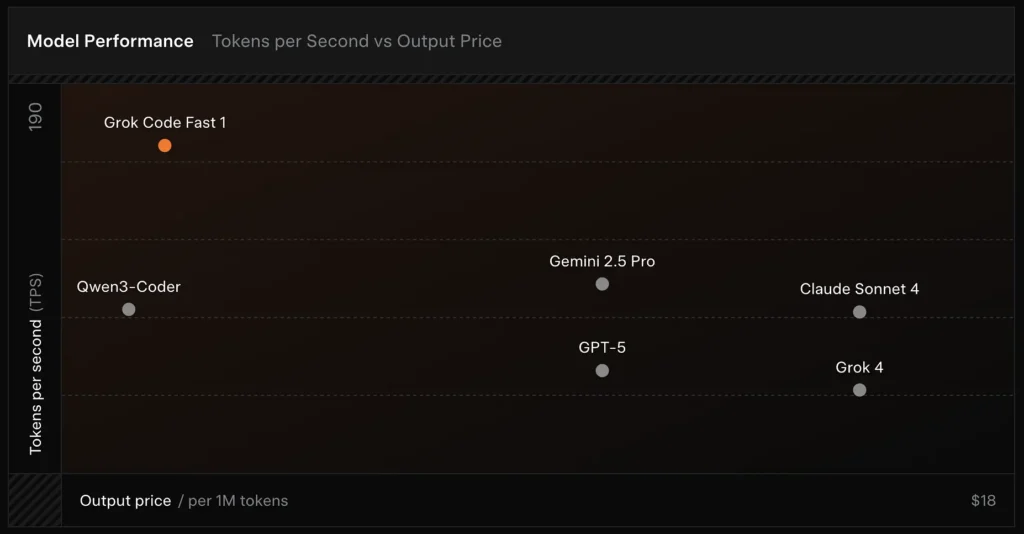
Wydajność w benchmarkach (na co punktuje)
SWE-Bench-Verified: xAI raportuje wynik 70.8% na swoim wewnętrznym harnessie na podzestawie SWE-Bench-Verified — benchmarku powszechnie używanym do porównań modeli inżynierii oprogramowania. Niedawna praktyczna ocena wykazała średnią ocenę ludzką ≈ 7.6 na mieszanym zestawie zadań kodowania — konkurencyjną wobec niektórych wysoko wycenianych modeli (np. Gemini 2.5 Pro), ale ustępującą większym multimodalnym/„najlepiej rozumującym” modelom takim jak Claude Opus 4 i Grok 4 od xAI w zadaniach o wysokiej trudności rozumowania. Benchmarki pokazują też zróżnicowanie w zależności od zadania: znakomity przy typowych poprawkach błędów i zwięzłej generacji kodu, słabszy w niektórych niszowych lub specyficznych dla bibliotek problemach (przykład Tailwind CSS).
Porównanie :
- vs Grok 4: Grok-code-fast-1 wymienia część absolutnej poprawności i głębszego rozumowania na znacznie niższy koszt i szybszą przepustowość; Grok 4 pozostaje opcją o wyższych możliwościach.
- vs Claude Opus / GPT-class: Te modele często prowadzą w złożonych, kreatywnych lub trudnych zadaniach rozumowania; Grok-code-fast-1 dobrze konkuruje w wysokonakładowych, rutynowych zadaniach deweloperskich, gdzie liczą się latencja i koszt.
Ograniczenia i ryzyka
Dotychczas zaobserwowane ograniczenia praktyczne:
- Luki domenowe: spadki wydajności przy niszowych bibliotekach lub nietypowo sformułowanych problemach (przykłady obejmują przypadki brzegowe Tailwind CSS).
- Kompromis kosztu tokenów rozumowania: ponieważ model może emitować wewnętrzne tokeny rozumowania, silnie agentowe/obszerne rozumowanie może zwiększyć długość wyjścia (i koszt) inferencji.
- Dokładność / przypadki brzegowe: choć silny w rutynowych zadaniach, Grok-code-fast-1 może halucynować lub generować niepoprawny kod dla nowych algorytmów lub adwersarialnych zadań; może wypadać gorzej od najlepszych modeli nastawionych na rozumowanie w wymagających benchmarkach algorytmicznych.
Typowe zastosowania
- Wsparcie w IDE i szybkie prototypowanie: szybkie podpowiedzi, inkrementalne dopisywanie kodu i interaktywne debugowanie.
- Zautomatyzowani agenci / przepływy kodu: agenci, którzy orkiestrują testy, uruchamiają polecenia i edytują pliki (np. pomocnicy CI, boty-recenzenci).
- Codzienne zadania inżynieryjne: generowanie szkieletów kodu, refaktoryzacje, sugestie triage’u błędów i szkielety projektów wieloplikowych, gdzie niska latencja wyraźnie poprawia przepływ pracy dewelopera.
Jak wywołać API grok-code-fast-1 z CometAPI
grok-code-fast-1 Cennik API w CometAPI, 20% taniej niż oficjalna cena:
- Tokeny wejściowe: $0.16/ M tokens
- Tokeny wyjściowe: $2.0/ M tokens
Wymagane kroki
- Zaloguj się do cometapi.com. Jeśli nie jesteś jeszcze naszym użytkownikiem, najpierw się zarejestruj
- Uzyskaj poświadczenie — klucz API interfejsu. Kliknij „Add Token” w sekcji API token w centrum osobistym, uzyskaj klucz tokenu: sk-xxxxx i zatwierdź.
Sposób użycia
- Wybierz endpoint “
grok-code-fast-1”, aby wysłać żądanie API i ustaw ciało żądania. Metodę żądania i ciało żądania znajdziesz w dokumentacji API na naszej stronie. Nasza strona udostępnia też test w Apifox dla Twojej wygody. - Zamień <YOUR_API_KEY> na swój rzeczywisty klucz CometAPI z konta.
- Wstaw swoje pytanie lub prośbę do pola content — na to odpowie model.
- . Przetwórz odpowiedź API, aby uzyskać wygenerowaną odpowiedź.
CometAPI udostępnia w pełni kompatybilne REST API — dla bezproblemowej migracji. Kluczowe szczegóły w API doc:
- Base URL: https://api.cometapi.com/v1/chat/completions
- Model Names: “
grok-code-fast-1“ - Authentication: token Bearer poprzez nagłówek
Authorization: Bearer YOUR_CometAPI_API_KEY - Content-Type:
application/json.
Integracja API i przykłady
Fragment Pythona dla wywołania ChatCompletion przez CometAPI:
pythonimport openai
openai.api_key = "YOUR_CometAPI_API_KEY"
openai.api_base = "https://api.cometapi.com/v1/chat/completions"
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Summarize grok-code-fast-1's main features."}
]
response = openai.ChatCompletion.create(
model="grok-code-fast-1",
messages=messages,
temperature=0.7,
max_tokens=500
)
print(response.choices.message)
Zobacz także Grok 4