

Uni-1 firmy Luma AI to coś więcej niż nowy model text-to-image. W ujęciu samej Lumy jest to „model rozumowania multimodalnego, który potrafi generować piksele”, zbudowany na „Unified Intelligence”, dzięki czemu rozumie intencje, reaguje na wskazówki i „myśli razem z tobą”. Raport techniczny firmy mówi, że model wykorzystuje autoregresyjny transformer tylko-dekoderowy, w którym tekst i obrazy są reprezentowane w jednej przeplatanej sekwencji, oraz że Uni-1 potrafi wykonywać ustrukturyzowane wewnętrzne rozumowanie przed i w trakcie syntezy obrazu. To połączenie sprawia, że Uni-1 jest jednym z najciekawszych wydań modeli obrazowych roku 2026.
Czym jest model obrazowy UNI-1?
Uni-1 to nowy model obrazowy Luma AI do zadań wymagających zarówno rozumienia, jak i generowania w jednym systemie. Luma przedstawia go jako model rozumowania multimodalnego, a nie klasyczny, wyłącznie dyfuzyjny silnik obrazowania, co ma znaczenie, ponieważ model ma robić więcej niż tylko tworzyć atrakcyjne wizualnie wyniki: został zaprojektowany, by interpretować instrukcje, zachowywać ograniczenia referencji i rozumować nad logiką sceny w trakcie generowania. Raport techniczny firmy opisuje Uni-1 jako pierwszy zunifikowany model rozumienia i generowania na drodze do multimodalnej inteligencji ogólnej.
Dlaczego Uni-1 jest inny
Stary pipeline ma sufit: generowanie obrazu bez rozumienia może zajść tylko do pewnego punktu. Uni-1 jest przedstawiany jako krok w kierunku „zunifikowanej inteligencji”, gdzie język, percepcja, wyobraźnia, planowanie i wykonanie są obsługiwane w jednej architekturze. To więcej niż branding. Uni-1 potrafi przesunąć się od wizualnego podobieństwa w stronę intencjonalnej kompozycji, wiarygodności i logiki sceny.
Większa historia jest taka, że modele obrazowe stają się bardziej sprawcze. Najnowszy stack obrazowy Google kładzie nacisk na konwersacyjną edycję, ugruntowanie w wyszukiwarce, fuzję wielu obrazów i spójność postaci; rodzina GPT Image OpenAI akcentuje natywną multimodalność i podążanie za instrukcjami. Uni-1 dołącza do tego trendu, ale mocniej stawia na ideę, że model powinien „pomyśleć” o obrazie, zanim go narysuje. To czyni Uni-1 szczególnie interesującym dla workflowów, w których precyzja i powtarzalność liczą się równie mocno co wizualny sznyt.
Jak właściwie działa Uni-1?
🔬 Proces tokenizacji
- Tekst → sekwencja tokenów
- Obraz → tokenizowane płytki
- Połączone w pojedynczą przeplataną sekwencję
🔁 Proces generowania
- Wejściowy prompt + referencje
- Model wykonuje wewnętrzne rozumowanie
- Planuje kompozycję
- Generuje tokeny sekwencyjnie
Matematycznie: P(x1,...,xn)=∏P(xi∣x1,...,xi−1)P(x_1,...,x_n) = \prod P(x_i | x_1,...,x_{i-1})P(x1,...,xn)=∏P(xi∣x1,...,xi−1)
🧠 Warstwa wewnętrznego rozumowania
Uni-1:
- Dekonponuje instrukcje
- Rozwiązuje ograniczenia
- Planuje układ przed renderowaniem
👉 To duży skok w porównaniu z modelami dyfuzyjnymi.
Autoregresyjne generowanie tylko-dekoderowe
Najważniejszy szczegół techniczny to fakt, że Uni-1 jest autoregresyjny, a nie dyfuzyjny. Raport techniczny Lumy mówi, że to autoregresyjny transformer tylko-dekoderowy, a tekst i obrazy są kodowane w jednej przeplatanej sekwencji. Mówiąc prościej, model nie zaczyna po prostu od szumu i nie „odszumia” stopniowo w kierunku obrazu. Zamiast tego generuje tokeny krok po kroku, co pozwala mu rozumować nad promptem, rozwiązywać ograniczenia i planować kompozycję przed i w trakcie renderowania.
🔬 Proces tokenizacji
- Tekst → sekwencja tokenów
- Obraz → tokenizowane płytki
- Połączone w pojedynczą przeplataną sekwencję
Dyfuzja vs Autoregresja
| Cecha | Modele dyfuzyjne | Uni-1 (autoregresyjny) |
|---|---|---|
| Generowanie | Szum → obraz | Token po tokenie |
| Rozumowanie | Ograniczone | Silne |
| Edycja | Słaba | Wieloturowa |
| Renderowanie tekstu | Słabe | Silne |
| Kontrola | Niska | Wysoka |
Architektura rdzeniowa
Uni-1 to:
- Autoregresyjny transformer tylko-dekoderowy
- Wspólna przestrzeń tokenów dla tekstu + obrazów
Ta architektura ma znaczenie, ponieważ daje modelowi szansę zachowania spójności, gdy prompt jest skomplikowany. Luma mówi, że Uni-1 potrafi dekomponować instrukcje, rozwiązywać sprzeczne ograniczenia i planować obraz, zanim renderowanie się rozpocznie. Jest to szczególnie przydatne w zadaniach takich jak strukturalne dopełnianie scen, rozmieszczanie wielu obiektów, wieloturowe dopracowywanie oraz edycje wymagające, by wynik pozostał wierny obrazowi referencyjnemu, a jednocześnie spełniał nowe instrukcje.
Do czego model wydaje się zaprojektowany lepiej
Uczenie się generowania obrazów poprawia rozumienie. Luma mówi, że trening generacji obrazów istotnie poprawia drobnoziarniste rozumienie wizualne, zwłaszcza w zakresie regionów, obiektów i układów. Dlatego Uni-1 nie jest jednokierunkowym generatorem, lecz systemem zunifikowanym, w którym generowanie i rozumienie wzajemnie się wzmacniają. Na etapie inferencji oznacza to, że Uni-1 próbuje zamknąć lukę między „widzeniem” a „tworzeniem”. To duży skok w porównaniu z modelami dyfuzyjnymi.
Proces generowania:
- Wejściowy prompt + referencje
- Model wykonuje wewnętrzne rozumowanie
- Planuje kompozycję
- Generuje tokeny sekwencyjnie
Matematycznie: P(x1,...,xn)=∏P(xi∣x1,...,xi−1)P(x_1,...,x_n) = \prod P(x_i | x_1,...,x_{i-1})P(x1,...,xn)=∏P(xi∣x1,...,xi−1)
Jakie funkcje i kluczowe zalety oferuje Uni-1?
Silne podążanie za instrukcjami i sterowalność
Najmocniejszą stroną Uni-1 jest kontrola. model jest zbudowany pod kątem precyzyjnej edycji, uporządkowanego użycia referencji i powtarzalnych workflowów. Dla twórców oznacza to mniej „hazardu promptowego”, a więcej powtarzalnych rezultatów.
Jedną z praktycznych zalet jest to, że został zbudowany do kontrolowanej iteracji. Ziarna pozwalają odtwarzać wyniki, a role referencji pomagają modelowi zrozumieć, czy obraz ma prowadzić tożsamość postaci, nastrój, paletę czy kompozycję. To sprawia, że Uni-1 jest łatwiejszy do reżyserowania niż model sterowany wyłącznie promptem, zwłaszcza dla zespołów tworzących reklamy, storyboardy, makiety produktowe czy zasoby marki, gdzie spójność ma znaczenie.
Generowanie oparte na referencjach z zachowaniem tożsamości
Dużą przewagą jest obsługa referencji. Luma wprost mówi, że Uni-1 korzysta z kontroli ugruntowanych w źródłach i potrafi zachować tożsamość, kompozycję oraz kluczowe ograniczenia wizualne z jednej lub wielu referencji. To czyni go atrakcyjnym dla zastosowań komercyjnych, takich jak postacie marki, makiety produktów, zasoby kampanii i każdy projekt, w którym obiekt musi pozostać rozpoznawalny w wariantach. To jeden z najczytelniejszych sposobów, w jaki Uni-1 różni się od bardziej estetycznych systemów obrazowych.
Biegłość kulturowa i szerokie spektrum stylów
Luma podkreśla także generowanie świadome kultury. Jej sekcja „Cultured” wskazuje na memy, mangę, kinowe estetyki, zwykłe fotografie, sport i wizerunki zwierząt, pokazując, że model ma działać w wielu językach wizualnych, a nie w jednym, genericznym stylu. Ma to znaczenie, bo dobry współczesny model obrazowy nie tylko powinien wiernie oddać realistyczną scenę; musi też rozumieć konwencje wizualne kultury internetowej, projektowania editorialowego, stylizowanej ilustracji i treści społecznościowych.
Multimodalne myślenie jako wybór projektowy
Różnicą nie jest tylko to, że Uni-1 generuje obrazy, ale że Luma ujmuje generowanie obrazów jako zadanie rozumowania. Uni-1 potrafi wykonywać ustrukturyzowane wewnętrzne rozumowanie, a uczenie się generowania obrazów poprawia drobnoziarniste rozumienie wizualne w zakresie regionów, obiektów i układów. To sugeruje model, który ma zrozumieć scenę przed renderowaniem, a nie po prostu statystycznie przybliżyć prompt.
Benchmarki wydajności
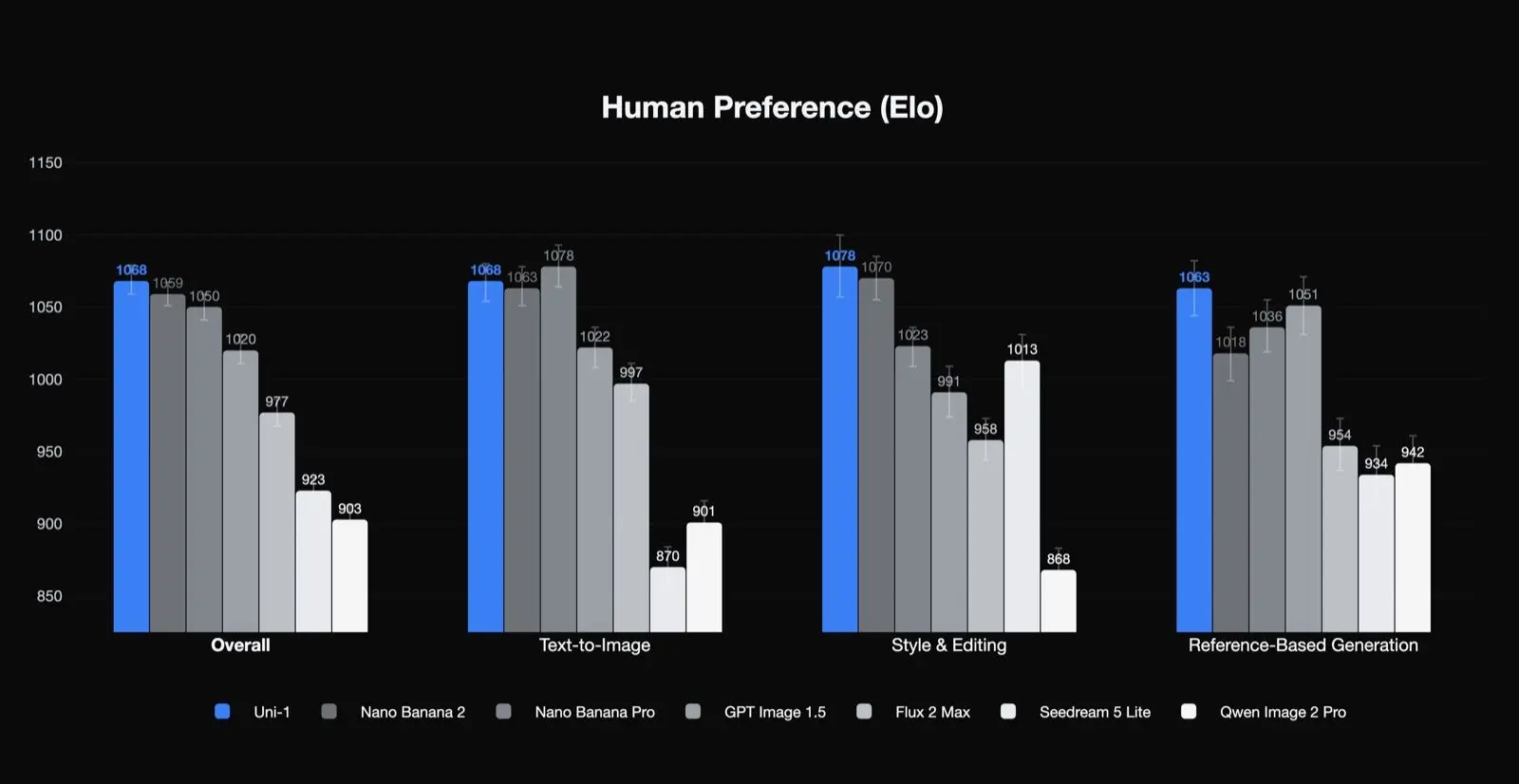
Wyniki preferencji ludzkich Lumy
Uni-1 zajmuje pierwsze miejsce w Elo preferencji ludzkich dla ogólnej jakości, stylu i edycji oraz generowania opartego na referencjach, a drugie w text-to-image. To znaczący wynik, ponieważ sugeruje, że model jest szczególnie mocny w zadaniach, na których zależy zespołom produkcyjnym: edycji, spójności i prowadzonej transformacji. Sugeruje także, że jego najlepsze przypadki użycia to niekoniecznie pojedyncze jednorazowe generowanie z tekstu.
RISEBench: reasoning-informed visual editing
Najbardziej przyciągający uwagę benchmark to RISEBench, który ocenia edycję wizualną opartą na rozumowaniu w kategoriach czasowych, przyczynowych, przestrzennych i logicznych. Zewnętrzne relacje z premiery Lumy mówią, że Uni-1 uzyskuje 0.51 ogółem w RISEBench, przed Google Nano Banana 2 z 0.50, Nano Banana Pro z 0.49 i OpenAI GPT Image 1.5 z 0.46. W rozumowaniu przestrzennym Uni-1 raportowany jest na poziomie 0.58 wobec 0.47 dla Nano Banana 2. W rozumowaniu logicznym Uni-1 ma 0.32, ponad dwukrotnie więcej niż 0.15 GPT Image 1.5. Różnice nie są ogromne ogólnie, ale duże w najtrudniejszych kategoriach rozumowania.

ODinW-13 i teza „generowanie poprawia rozumienie”
Uni-1 wypada także mocno w ODinW-13, benchmarku gęstej detekcji o otwartym słownictwie. Doniesienia o danych technicznych Lumy mówią, że pełny model uzyskuje 46.2 mAP, niemal dorównując Gemini 3 Pro Google z 46.3. Te same relacje podają, że wariant wyłącznie rozumiejący ma 43.9 mAP, co implikuje, że trening generacyjny poprawia rozumienie o 2.3 punktu. To istotne, bo wspiera główną tezę Lumy: generowanie obrazów i rozumienie obrazów mogą się wzajemnie wzmacniać, a nie konkurować.
Cena API Uni-1
| Input price (text) | $0.50 |
|---|---|
| Input price (images) | $1.20 |
| Output price (text and thinking) | $3.00 |
| Output price (images) | $45.45 |
Po stronie konsumenckiej, strona cen Lumy wymienia Plus za $30/miesiąc, Pro za $90/miesiąc i Ultra za $300/miesiąc, z darmowymi kredytami startowymi w każdym planie. Oznacza to, że de facto są dwa poziomy wycen do rozważenia: członkostwo konsumenckie w platformie oraz wycena na poziomie API modelu do zastosowań produkcyjnych.
Na razie Uni-1 API w CometAPI jest Available Soon, z obiecaną zniżką na start. Obecnie CometAPI oferuje też znakomite surowe modele obrazowe, takie jak Midjourney i Nano Banana 2.
Uni-1 vs GPT Image 1.5 vs Nano Banana 2
Uni-1 kontra Nano Banana 2 Google
Nano Banana 2 wygląda na mocniejszy w szeroko pojętej obsłudze referencji i integracji ekosystemowej. Google akcentuje ugruntowanie w wyszukiwaniu obrazów, iterację konwersacyjną i workflowy oparte silnie na referencjach (do 14 referencji). Uni-1, w przeciwieństwie, jest wyraźniej ukierunkowany na rozumowanie, wiarygodność scen i precyzyjną edycję w zunifikowanej architekturze modelu. W praktyce Google wydaje się zoptymalizowany pod szybkość, mainstreamową skalę produkcyjną i natywne ugruntowanie Google; Luma pod kątem strukturalnego rozumowania wizualnego i sterowalnej edycji obrazu.
W publicznych porównaniach wokół Uni-1 kompromis jest jasny: Nano Banana 2 pozostaje bardzo mocny w czysto tekstowo-obrazowej jakości i szybkości, podczas gdy Uni-1 mocniej stawia na edycję wymagającą rozumowania, kontrolę referencji i wierność instrukcjom.
Uni-1 kontra GPT Image OpenAI
W raportowanych benchmarkach Uni-1 minimalnie wyprzedza GPT Image 1.5 w RISEBench ogółem i wyraźniej w rozumowaniu logicznym. W porównaniu z rodziną GPT Image OpenAI, Uni-1 jest wężej i agresywniej pozycjonowany wokół rozumowania wizualnego i kontrolowanej edycji. Dokumentacja OpenAI akcentuje wiedzę o świecie, multimodalne rozumienie i kontekstową świadomość; dokumentacja Lumy podkreśla ustrukturyzowane wewnętrzne rozumowanie, kontrolę ugruntowaną w referencjach oraz zbenchmarkowaną sprawność edycji wizualnej. Zatem choć oba są multimodalne, Uni-1 jest bardziej oczywiście „specjalistycznym modelem rozumowania obrazowego”, podczas gdy GPT Image jawi się jako ogólny system multimodalny, który przy okazji generuje obrazy bardzo dobrze.
Porównanie cen wśród trzech
W wycenie porównanie zależy od rozmiaru wyjścia i poziomu produktu, więc nie jest to idealnie „jabłka do jabłek”. Publikowana równowartość 2048px dla Uni-1 to około $0.0909 na obraz. Najnowsza strona cen modelu obrazowego Google podaje $0.134 za obraz 1K/2K i $0.24 za obraz 4K dla najnowszego Gemini image preview, podczas gdy strona cen GPT Image OpenAI podaje cenę per obraz $0.011 w niskiej jakości dla 1024x1024, $0.042 w średniej jakości i $0.167 w wysokiej jakości, z większymi wyjściami wysokiej jakości po $0.25. Innymi słowy, OpenAI może być znacznie tańszy na niskim poziomie, Google jest agresywny w segmencie szybkości i skali, a Uni-1 plasuje się pośrodku z mocnym profilem cena–wydajność dla 2K.
Różnice filozoficzne
| Model | Podejście |
|---|---|
| Uni-1 | Zunifikowana inteligencja multimodalna |
| GPT Image | LLM + generowanie obrazów |
| Nano Banana 2 | Zoptymalizowana dyfuzja produkcyjna |
Szczegółowa tabela porównawcza
| Cecha | Uni-1 | GPT Image 1.5 | Nano Banana 2 |
|---|---|---|---|
| Architektura | Autoregresyjna | Hybrydowa | Dyfuzyjna |
| Ujednolicenie multimodalne | ✅ Natywne | Częściowe | ❌ |
| Zdolność rozumowania | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ |
| Jakość obrazu | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| Renderowanie tekstu | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐ |
| Przepływy pracy edycyjne | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ |
| Szybkość | Średnia | Szybka | Szybka |
| Kontrola | Wysoka | Średnia | Średnia |
CometAPI zapewnia interaktywne tworzenie surowych obrazów dla GPT Image 1.5, Nano Banana 2, oraz nadchodzącego Uni-1, a także programowanie przez API. Obniżone ceny i rozliczanie pay‑as‑you‑go czynią go preferowanym wyborem dla deweloperów.
Do czego Uni-1 nadaje się najlepiej
Uni-1 wygląda szczególnie mocno w przypadkach, gdy potrzebujesz powtarzalności, spójności postaci lub kontroli wielu referencji. Obejmuje to kampanie marki, makiety produktów, koncepcje editorialowe, storyboardy, warianty lokalizacyjne i edycje obrazów, w których kompozycja ma pozostać nienaruszona, ale styl lub otoczenie powinny się zmienić. Przykłady Lumy mocno skłaniają się ku tym przypadkom użycia, a rozdział modelu na „Create vs Modify” to w zasadzie bezpośrednia odpowiedź na typowe bóle produkcyjne.
Jeśli twoja praca to głównie „zrób coś ładnego z jednego promptu”, różnica może wydać się mniej dramatyczna. Ale jeśli twój workflow to „zrób pięć powiązanych wersji, zachowaj tę samą postać, zachowaj kadr, zmień oświetlenie i zrób to odtwarzalne w przyszłym tygodniu”, projekt Uni-1 zaczyna mieć dużo sensu. To wniosek, ale naturalnie wynika z funkcji kontroli, na które Luma kładzie nacisk.
Najlepsze praktyki, by uzyskać lepsze rezultaty z Uni-1
Zacznij od użycia właściwego trybu. Wskazówki Lumy są proste: Create, gdy chcesz nowej sceny, Modify, gdy chcesz zachować istniejącą. Mieszanie tych intencji czyni rezultaty bardziej chybotliwymi.
Używaj etykiet referencji jak profesjonalista. Luma poleca sformułowania takie jak „Use IMAGE1 as a STYLE reference” albo „Use IMAGE2 as LIGHTING.” Model radzi sobie lepiej, gdy każda referencja ma zadanie, zamiast mglistej „inspiracji”.
Zablokuj ziarno, gdy znajdziesz coś dobrego. Luma explicite rekomenduje najpierw eksplorować bez ziarna, potem zapisać ziarno, gdy masz mocny wynik. Następnie zmieniaj jeden parametr naraz. To najprostszy sposób, by przekształcić generowanie w kontrolowany system produkcyjny.
Bądź konkretny i precyzyjny. Luma ostrzega przed mglistymi słowami jak „piękny” czy „niesamowity” i zachęca do nazwanych estetyk, takich jak „plakat filmowy włoskiego giallo z lat 70.” lub dokładnych wskazówek dotyczących stylu kamery. W praktyce konkretne prompty zwykle wygrywają z poetyckimi, bo model może zakotwiczyć się w realnej strukturze.
Używaj łańcucha Create → Modify. Luma explicite nazywa to jednym z najpotężniejszych workflowów: eksploruj w Create, a potem dopracowuj w Modify. To słodki punkt dla poważnej produkcji, bo ogranicza cofanie i zachowuje dobre elementy kompozycji, jednocześnie dopinając detale.
Ostateczny werdykt
Uni-1 to najczytelniejsza jak dotąd deklaracja Lumy, że generowanie obrazów przesuwa się z „prompt in, picture out” w stronę tworzenia wizualnego prowadzonego rozumowaniem. Jego publiczne mocne strony to kontrola, obsługa referencji, odtwarzalność oraz architektura modelu, która utrzymuje język i piksele w jednym systemie.
Dla twórców i zespołów, którym zależy na wysoko klikalnych materiałach wizualnych, spójnych postaciach, precyzyjnych edycjach i klarowności wyceny wysokiej rozdzielczości, Uni-1 to model, na który zdecydowanie warto zwracać uwagę. Jeśli rollout API przebiegnie gładko, może stać się jedną z najciekawszych alternatyw dla Nano Banana 2 Google i GPT Image 1.5 OpenAI w 2026 roku.
Planujesz zacząć tworzyć surowe obrazy? CometAPI, jednoprzystankowa platforma agregująca API modeli multimodalnych, zaprasza!