
Gemini 2.5 Flash API é o mais recente modelo de IA multimodal do Google, projetado para tarefas de alta velocidade e custo-eficientes com recursos de raciocínio controláveis, permitindo que os desenvolvedores ativem ou desativem recursos avançados de “pensamento” por meio da API Gemini. Os modelos mais recentes são gemini-2.5-flash.
Visão geral do Gemini 2.5 Flash
O Gemini 2.5 Flash foi projetado para fornecer respostas rápidas sem comprometer a qualidade da saída. Ele suporta entradas multimodais, incluindo texto, imagens, áudio e vídeo, tornando-o adequado para diversas aplicações. O modelo pode ser acessado por meio de plataformas como Google AI Studio e Vertex AI, fornecendo aos desenvolvedores as ferramentas necessárias para uma integração perfeita em diversos sistemas.
Informações básicas (recursos)
O Gemini 2.5 Flash apresenta vários recursos de destaque características que o distinguem dentro da família Gemini 2.5:
- Raciocínio Híbrido:Os desenvolvedores podem definir um orçamento_pensamento parâmetro para controlar com precisão quantos tokens o modelo dedica ao raciocínio interno antes da saída.
- Fronteira de Pareto: Posicionado no ponto ótimo de custo-desempenhoO Flash oferece a melhor relação preço-inteligência entre os modelos 2.5.
- Suporte multimodal: Processos texto, imagens, vídeo e auditivo nativamente, permitindo capacidades de conversação e análise mais ricas.
- Contexto de 1 milhão de tokens: O comprimento de contexto incomparável permite análise profunda e compreensão de documentos longos em uma única solicitação.
Controle de versão de modelo
O Gemini 2.5 Flash passou pela seguinte chave versões:
- gemini-2.5-flash-lite-preview-09-2025: Usabilidade aprimorada da ferramenta: desempenho aprimorado em tarefas complexas e multietapas, com um aumento de 5% nas pontuações verificadas pelo SWE-Bench (de 48.9% para 54%). Eficiência aprimorada: ao habilitar o raciocínio, obtém-se resultados de maior qualidade com menos tokens, reduzindo a latência e os custos.
- Prévia 04-17: Lançamento de acesso antecipado com capacidade de “pensar”, disponível via gemini-2.5-flash-preview-04-17.
- Disponibilidade geral estável (GA):A partir de 17 de junho de 2025, o ponto final estável gêmeo-2.5-flash substitui a pré-visualização, garantindo confiabilidade de nível de produção sem alterações de API em relação à pré-visualização de 20 de maio.
- Descontinuação da visualização: Os endpoints de visualização foram programados para desligamento em 15 de julho de 2025; os usuários devem migrar para o endpoint do GA antes dessa data.
A partir de julho de 2025, o Gemini 2.5 Flash estará disponível publicamente e estável (sem alterações em relação ao gemini-2.5-flash-preview-05-20 ).Se você estiver usando gemini-2.5-flash-preview-04-17, o preço de visualização atual continuará até a aposentadoria programada do ponto final do modelo em 15 de julho de 2025, quando será desativado. Você pode migrar para o modelo disponível ao público em geral.gemini-2.5-flash".
Mais rápido, mais barato, mais inteligente:
- Objetivos de design: baixa latência + alto rendimento + baixo custo;
- Aceleração geral no raciocínio, processamento multimodal e tarefas de texto longo;
- O uso de tokens é reduzido em 20–30%, reduzindo significativamente os custos de raciocínio.
Especificações técnicas
Janela de contexto de entrada: até 1 milhão de tokens, permitindo ampla retenção de contexto.
Tokens de saída: capazes de gerar até 8,192 tokens por resposta.
Modalidades suportadas: Texto, imagens, áudio e vídeo.
Plataformas de integração: disponíveis no Google AI Studio e no Vertex AI.
Preço: Modelo de preço competitivo baseado em tokens, facilitando uma implantação econômica.
Detalhes Técnicos
Sob o capô, o Gemini 2.5 Flash é um baseado em transformador grande modelo de linguagem treinado em uma mistura de dados da web, código, imagem e vídeo. Chave técnico especificações incluem:
Treinamento Multimodal: Treinado para alinhar múltiplas modalidades, o Flash pode misturar perfeitamente texto com imagens, vídeo, ou auditivo, útil para tarefas como resumo de vídeo ou legendagem de áudio.
Processo de Pensamento Dinâmico: Implementa um loop de raciocínio interno onde o modelo da empresa e decompõe prompts complexos antes da saída final.
Orçamentos de Pensamento Configuráveis: O orçamento_pensamento pode ser definido a partir de 0 (sem raciocínio) até Tokens 24,576, permitindo compensações entre latência e qualidade de resposta.
Integração de ferramentas: Apoia Aterramento com a Pesquisa Google, Execução de Código, Contexto de URL e Chamada de função, permitindo ações do mundo real diretamente de prompts de linguagem natural.
Desempenho de referência
Em avaliações rigorosas, o Gemini 2.5 Flash demonstra líder da indústria desempenho:
- Prompts difíceis do LMArena: Pontuado perdendo apenas para o 2.5 Pro no desafiador teste Hard Prompts, demonstrando fortes capacidades de raciocínio em várias etapas.
- Pontuação MMLU de 0.809: Excede o desempenho médio do modelo com um 0.809 Precisão da MMLU, refletindo seu amplo conhecimento de domínio e capacidade de raciocínio.
- Latência e taxa de transferência: Conquistas 271.4 fichas/seg velocidade de decodificação com um 0.29 s de tempo para o primeiro token, tornando-o ideal para cargas de trabalho sensíveis à latência.
- Líder em relação preço/desempenho: No $0.26/1 M tokensO Flash supera muitos concorrentes e ainda os iguala ou os supera em benchmarks importantes.
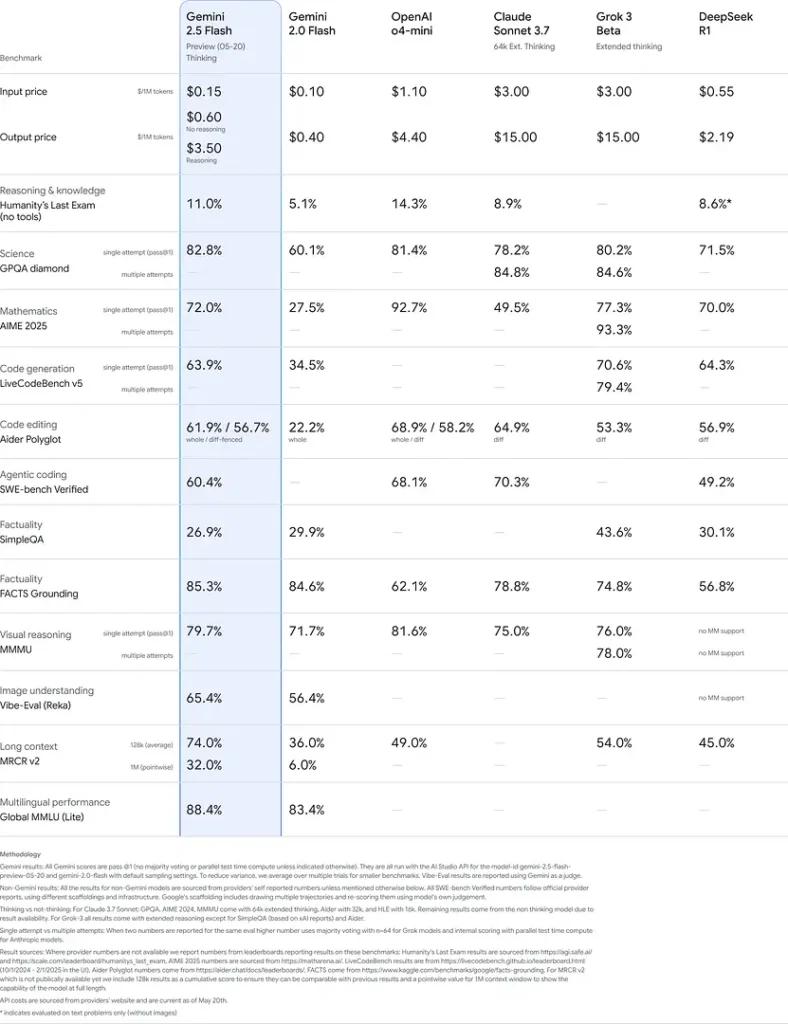
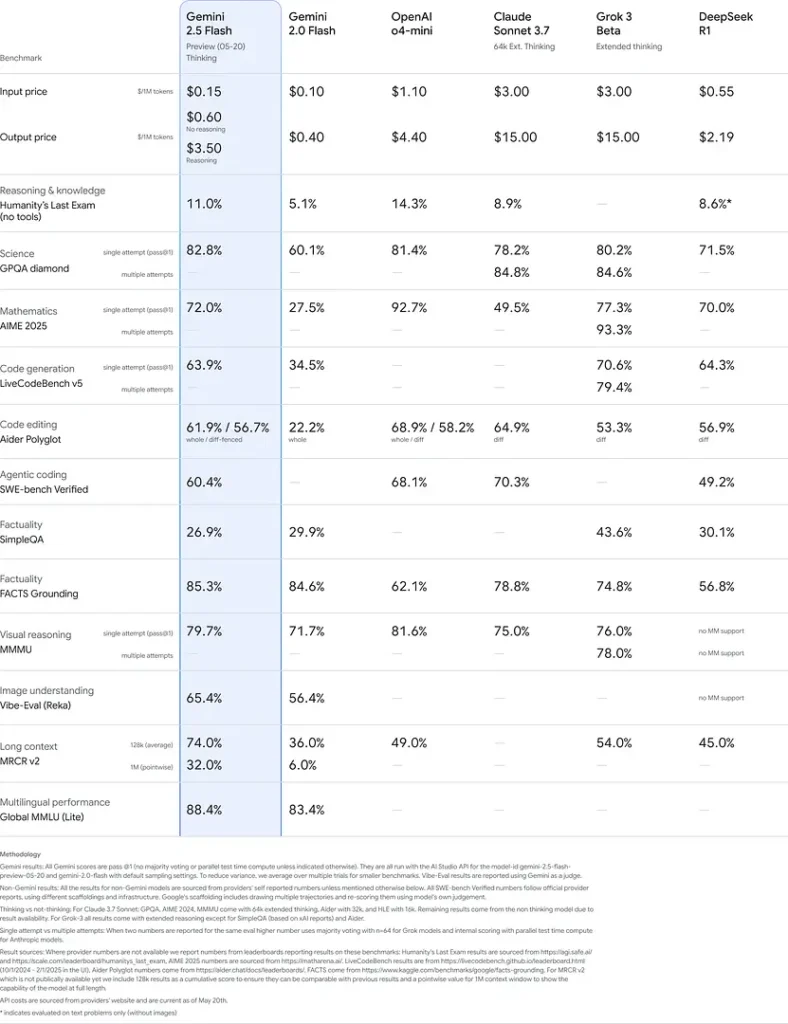
Esses resultados indicam a vantagem competitiva do Gemini 2.5 Flash em raciocínio, compreensão científica, resolução de problemas matemáticos, codificação, interpretação visual e capacidades multilíngues:
Limitações
Embora poderoso, o Gemini 2.5 Flash carrega certas limitações:
- Riscos de segurança:O modelo pode apresentar uma tom “pregador” e podem produzir resultados aparentemente plausíveis, mas incorretos ou tendenciosos (alucinações), especialmente em consultas de casos extremos. A supervisão humana rigorosa continua sendo essencial.
- Limites de taxa: O uso da API é limitado por limites de taxa (10 RPM, 250,000 TPM, 250 RPD em níveis padrão), o que pode afetar o processamento em lote ou aplicativos de alto volume.
- Piso de Inteligência:Embora excepcionalmente capaz para um chamada de conferência modelo, ele permanece menos preciso do que 2.5 Pro nas tarefas de agente mais exigentes, como codificação avançada ou coordenação multiagente.
- Compensações de custos:Embora ofereça o melhor preço-desempenho, uso extensivo do pensando O modo aumenta o consumo geral de tokens, aumentando os custos para prompts de raciocínio profundo.
Veja também API Gemini 2.5 Pro
Conclusão
O Gemini 2.5 Flash é uma prova do compromisso do Google com o avanço das tecnologias de IA. Com seu desempenho robusto, recursos multimodais e gerenciamento eficiente de recursos, ele oferece uma solução abrangente para desenvolvedores e organizações que buscam aproveitar o poder da inteligência artificial em suas operações.
Como ligar Gemini 2.5 Flash API da CometAPI
Gemini 2.5 Flash Preços da API no CometAPI, 20% de desconto sobre o preço oficial:
- Tokens de entrada: $ 0.24 / M tokens
- Tokens de saída: US$ 0.96/M tokens
Etapas Necessárias
- Faça o login no cometapi.com. Se você ainda não é nosso usuário, registre-se primeiro
- Obtenha a chave de API da credencial de acesso da interface. Clique em "Adicionar Token" no token da API no centro pessoal, obtenha a chave de token: sk-xxxxx e envie.
- Obtenha a URL deste site: https://api.cometapi.com/
Métodos de uso
- Selecione a opção "
gemini-2.5-flash” endpoint para enviar a solicitação de API e definir o corpo da solicitação. O método e o corpo da solicitação são obtidos da documentação da API do nosso site. Nosso site também oferece o teste Apifox para sua conveniência. - Substituir com sua chave CometAPI real da sua conta.
- Insira sua pergunta ou solicitação no campo de conteúdo — é a isso que o modelo responderá.
- . Processe a resposta da API para obter a resposta gerada.
Para obter informações sobre o modelo lançado na API Comet, consulte https://api.cometapi.com/new-model.
Para obter informações sobre o preço do modelo na API Comet, consulte https://api.cometapi.com/pricing.
Exemplo de uso da API
Os desenvolvedores podem interagir com gêmeo-2.5-flash através da API da CometAPI, permitindo a integração em diversas aplicações. Abaixo, um exemplo em Python:
import os
from openai import OpenAI
client = OpenAI(
base_url="
https://api.cometapi.com/v1/chat/completions",
api_key="<YOUR_API_KEY>",
)
response = openai.ChatCompletion.create(
model="gemini-2.5-flash",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain the concept of quantum entanglement."}
]
)
print(response)
Este script envia um prompt para o Gemini 2.5 Flash modelo e imprime a resposta gerada, demonstrando como utilizar Gemini 2.5 Flash para explicações complexas.