

GLM-5-Turbo é um novo LLM fundamental da Zhipu AI, especificamente treinado e ajustado para fluxos de trabalho no estilo de agentes (a empresa chama o ecossistema-alvo de cenários OpenClaw / “lobster”). Ele oferece um contexto muito longo (até ~200K tokens), streaming e saídas estruturadas, menores taxas de erro em chamadas de ferramentas (relatado ~0,67% em testes de terceiros) e preço por token substancialmente mais baixo. O modelo busca trocar uma pequena quantidade de desempenho de pico em uma única interação por muito mais estabilidade, confiabilidade em ferramentas, tratamento de tarefas agendadas/persistentes e execução de cadeias longas — útil para agentes autônomos, sistemas de orquestração e pipelines com múltiplas ferramentas.
O que é o GLM-5-Turbo?
GLM-5-Turbo é apresentado pela Zhipu como um modelo base criado especificamente para orquestração de agentes e fluxos de trabalho automatizados complexos, em vez de um modelo geral de chat ou multimodal. As escolhas de design enfatizam:
- Treinamento nativamente amigável a agentes (uso de ferramentas, seguimento de comandos, tarefas temporizadas/persistentes).
- Janelas de contexto muito grandes e capacidade de saída para suportar sessões longas, memória e planejamento de cadeia de raciocínio.
- Inferência estável e de alto throughput para fluxos de negócios longos e tarefas agendadas.
Ao contrário dos LLMs tradicionais otimizados para chat ou geração de texto, o GLM-5-Turbo é:
- Foco em agentes (não em chat)
- Construído para ambientes OpenClaw (“lobster”)
- Projetado para fluxos de trabalho autônomos em múltiplas etapas
🦞 O que significa “Lobster Agent”?
O conceito “lobster” refere-se ao OpenClaw, o ecossistema de agentes de IA da Zhipu, onde os modelos:
- Usam ferramentas de forma dinâmica
- Executam longas cadeias de tarefas
- Mantêm memória persistente
- Operam em terminais, aplicativos e APIs
O GLM-5-Turbo é profundamente otimizado para esse paradigma, resolvendo problemas-chave de agentes, como:
- Confiabilidade de chamadas de ferramentas
- Decomposição de tarefas
- Planejamento de longo horizonte
- Estabilidade de execução
Principais recursos e por que eles importam
Contexto longo + enorme capacidade de saída (200K / 128K)
Uma janela de contexto de 200K tokens e capacidade de saída de 128K permitem ao GLM-5-Turbo:
- Manter memória estendida do contexto anterior (conversas, saídas de ferramentas, resultados intermediários).
- Produzir artefatos gerados muito longos (planos em múltiplas etapas, relatórios extensos, bases de código) sem necessidade de concatenar o contexto repetidamente.
- Hospedar agentes de múltiplas interações que precisam reter todo o histórico de execução para tomada de decisão precisa.
Esta é uma escolha técnica deliberada para agentes — em vez de dividir tarefas em prompts curtos, os agentes podem manter um estado coerente ao longo de milhares de turnos conversacionais ou etapas.
Primitivas de agente incorporadas ao treinamento
Em vez de adaptar um modelo genérico a tarefas de agente, o GLM-5-Turbo foi treinado com objetivos no estilo de agentes (por exemplo, comportamento de invocação de ferramentas, análise de comandos/argumentos). O efeito alegado é menos alucinações durante chamadas de ferramentas, planos de múltiplas etapas mais estáveis e latência aprimorada em execuções longas — tudo valioso quando a automação deve encadear muitas APIs ou ferramentas externas com confiabilidade.
Throughput e estabilidade de execução
A variante GLM-5-Turbo melhora a estabilidade de execução e o throughput para fluxos de negócios longos em comparação com modelos grandes generalizados — a linguagem de marketing enfatiza “execução de alto throughput” e “liderança em estabilidade de resposta” entre modelos semelhantes. Isso é significativo para implantações de agentes corporativos, nas quais uma etapa com falha pode quebrar todo o pipeline. Benchmarks independentes de terceiros ainda estão surgindo.
Dados de benchmark do GLM-5-Turbo
Nota: a Zhipu publicou avaliações internas, e benchmarks de terceiros/academia para o GLM-5 estão disponíveis. O GLM-5-Turbo foi recém-lançado; execuções de benchmark independentes da comunidade levarão algum tempo para aparecer. Abaixo listamos os números publicados mais defensáveis e o contexto.
GLM-5 (referência) — métricas publicadas representativas
O GLM-5 da Zhipu (o predecessor principal do Turbo) relata liderança em muitos testes de engenharia/fluxo de trabalho — por exemplo:
- SWE-bench Verified: 77.8 (relatado na documentação do GLM-5 como pontuação líder entre modelos abertos).
- Terminal Bench 2.0: 56.2 (relatado como desempenho topo entre modelos abertos na distribuição fornecida).
Esses números estabelecem o GLM-5 como uma base alta em tarefas de engenharia de software e execução; o GLM-5-Turbo é posicionado para trocar parte do foco em tamanho/parâmetros brutos por melhor confiabilidade de agente e throughput. O GLM-5-Turbo apresentou ~0.67% de erro em chamadas de ferramentas em suas comparações, substancialmente abaixo de execuções GLM-5 comparativas que variaram de ~2.33% a 6.41%.
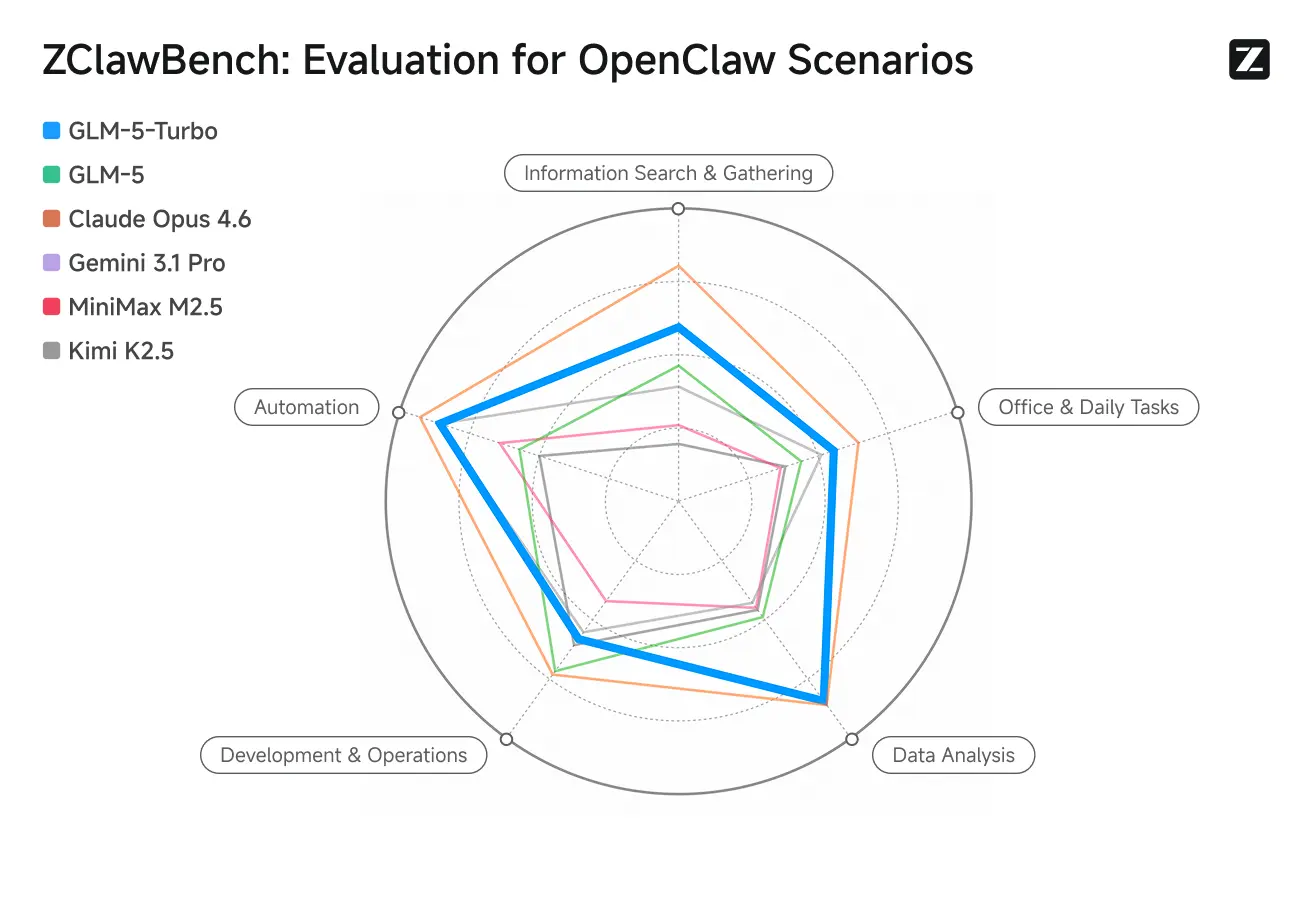
ZClawBench: Benchmark Test for OpenClaw Proxy Scenarios
A Zhipu também lançou o benchmark ZClawBench para avaliação de agentes inteligentes. Em testes cegos cobrindo áreas diversas como desenvolvimento de código, análise de dados e criação de conteúdo, o novo modelo codinome Pony-Alpha-2 venceu a preferência de 90% dos respondentes.
Preço e disponibilidade (quem vende e quanto custa)
A Zhipu implementou um aumento de preço de API de ~20% para a oferta GLM-5-Turbo no lançamento e simultaneamente introduziu níveis de assinatura “Lobster Package” destinados a suavizar o preço por token para implantações de agentes.
Níveis de assinatura relatados (pacotes de exemplo)
Dois pacotes Lobster ilustrativos (preços são conversões e aproximados):
- Plano Lobster de entrada:
39 CNY / mês (US$5.66) por 35,000,000 tokens. - Plano Lobster intermediário:
99 CNY / mês (US$14.36) por 100,000,000 tokens.
Usando esses números publicados, o custo por 1 milhão de tokens é aproximadamente:
- Plano de entrada: ~US$0.162 por 1M tokens.
- Plano intermediário: ~US$0.144 por 1M tokens.
Esses valores por 1M são conversões simples do custo de assinatura publicado e do teto de tokens e ilustram a economia para workloads de agentes de alto volume. (Cálculos baseados na moeda relatada pela imprensa e nas quantidades de tokens.)
Preço de API
Listagem de marketplace representativo (CometAPI): $0.96 por 1M tokens de entrada e $3.20 por 1M tokens de saída para o GLM-5-Turbo.
A página de preços para desenvolvedores da própria Zhipu (Z.ai) lista uma taxa direta um pouco maior para o GLM-5-Turbo: $1.20 por 1M tokens de entrada e $4.00 por 1M tokens de saída (taxas de entrada em cache são menores).
GLM-5-Turbo vs GLM-5 — comparação lado a lado
Em alto nível:
- GLM-5 = modelo base principal de uso geral (raciocínio, codificação, benchmarks)
- GLM-5-Turbo = variante otimizada para agentes do GLM-5 (focada em fluxos longos, uso de ferramentas, estabilidade)
O GLM-5-Turbo não é uma arquitetura de modelo completamente nova, mas sim uma versão especializada e otimizada para produção do GLM-5 desenhada para sistemas de agentes como o OpenClaw.
Posicionamento central
| Modelo | Posicionamento |
|---|---|
| GLM-5 | LLM principal de uso geral (raciocínio, codificação, benchmarks) |
| GLM-5-Turbo | Modelo “agent-first” (automação, orquestração, uso de ferramentas) |
👉 Em termos simples:
- Use GLM-5 → quando quiser inteligência máxima
- Use GLM-5-Turbo → quando quiser automação estável / agentes
Comparação de capacidade de agente (MAIS IMPORTANTE)
GLM-5 (capacidade de agente) já oferece suporte a:
- Uso de ferramentas
- Raciocínio em múltiplas etapas
- Agentes de codificação
Mas limitações:
- Pode perder contexto em cadeias longas
- Chamadas de ferramentas podem degradar com o tempo
- Requer mais lógica de orquestração
O GLM-5-Turbo é explicitamente otimizado para agentes:
Principais melhorias:
- Confiabilidade de chamadas de ferramentas ↑
- Decomposição de tarefas (planejamento) ↑
- Consistência em cadeias longas ↑
- Suporte a execução persistente ↑
Exemplo de melhoria:
- Execução estável por 10+ etapas sem perder contexto
👉 Isso é crítico para:
- Sistemas ao estilo AutoGPT
- Fluxos de trabalho multiagente
- Automação SaaS
Velocidade e eficiência
| Aspecto | GLM-5 | GLM-5-Turbo |
|---|---|---|
| Velocidade de inferência | Moderada | Mais rápida |
| Throughput | Padrão | Maior |
| Latência em tarefas longas | Pode degradar | Otimizada |
O GLM-5-Turbo foi projetado para resolver um problema real do setor:
Modelos grandes ficam lentos ou quebram durante fluxos de trabalho longos
Comparação de preços
| Modelo | Entrada ($/1M tokens) | Saída ($/1M tokens) |
|---|---|---|
| GLM-5 | ~$1.00 | ~$3.20 |
| GLM-5-Turbo | ~$1.20 | ~$4.00 |
👉 O GLM-5-Turbo é mais caro (~20% a mais)
Por que mais caro?
Porque oferece:
- Melhor confiabilidade de orquestração
- Maior estabilidade de produção
- Otimizações específicas para agentes
👉 No ambiente corporativo:
- Você paga mais por token
- Mas reduz custo de falhas + tentativas repetidas
| Atributo | GLM-5 | GLM-5-Turbo |
|---|---|---|
| Objetivo principal | Modelo base principal de uso geral (amplas capacidades, codificação/benchmarks fortes) | Modelo base otimizado para agentes/“OpenClaw” / lobster |
| Janela de contexto | (relatada como alta; GLM-5 foca ~200K (GLM-5 também suporta contexto longo) | 200,000 tokens (explicitamente documentado). |
| Máximo de tokens de saída | (grande, depende do modelo) | 128,000 tokens (documentado). |
| Pontuações de benchmark notáveis | SWE-bench: 77.8; Terminal Bench 2.0: 56.2 (números relatados do GLM-5). | Avaliações internas alegam estabilidade aprimorada em cadeias longas e throughput para fluxos de agentes; benchmarks públicos independentes pendentes. |
| Modalidades | Texto (principal), a família GLM tem variantes de visão em modelos irmãos | Somente texto (por docs) — otimizado para agentes baseados em ferramentas. |
| Casos de uso recomendados | Amplo: chat, código, raciocínio, conteúdo | Orquestração de agentes, invocação de ferramentas, automação de longo horizonte |
| Preços | Preços existentes do GLM-5 (variáveis por plano) | Novo lançamento — aumento de API relatado de ~20%; novos níveis de assinatura Lobster introduzidos |
Como usar o GLM-5-Turbo
CometAPI — acesso único a muitas modelos via API (compatível com OpenAI)
O CometAPI lista o GLM-5-Turbo como disponível e fornece uma base URL e SDK compatíveis com OpenAI. Use a string de modelo que eles publicam (o site lista o GLM-5-Turbo com preço similar). Exemplos adaptados da documentação do CometAPI:
curl (CometAPI):
curl -X POST "https://api.cometapi.com/v1/chat/completions" \ -H "Authorization: Bearer YOUR_COMETAPI_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "z-glm-5-turbo", // ou use o slug de modelo exato exibido na interface do CometAPI "messages": [{"role":"user","content":"Crie uma lista de verificação de 5 etapas para a integração de um novo contratado."}], "max_tokens": 800 }'
O valor do CometAPI é a conveniência de agregação (uma única integração para muitos modelos). Confirme o slug exato do modelo no painel do CometAPI antes de chamar.
Boas práticas ao construir agentes Lobster / OpenClaw com o GLM-5-Turbo
- Projete para confiabilidade, não para latência bruta: a vantagem do Turbo é menor falha em chamadas de ferramentas em cadeias longas. Estruture as execuções do agente para privilegiar conclusões robustas (retries, chamadas idempotentes) em vez de pequenos ganhos de primeiro token.
- Use streaming e chamadas de ferramentas incrementais: adote saídas em streaming/em blocos para reduzir retrabalho e permitir invocação antecipada de ferramentas quando apropriado. O GLM-5-Turbo suporta streaming.
- Saídas estruturadas para analisadores: prefira JSON ou resultados bem formatados para parsing determinístico por ferramentas downstream. O Turbo suporta saídas estruturadas.
- Planeje agendamento/persistência: se seu agente precisar verificar periodicamente ou executar tarefas em background, use as melhores semânticas de tempo e recursos de cache do Turbo para evitar replanejar a cada ciclo.
- Instrumente chamadas de ferramentas e fallbacks: registre chamadas de ferramentas e projete fallbacks elegantes (por exemplo, tentar novamente com leve ajuste de temperatura ou chamar uma ferramenta reserva), pois fluxos agentic são frágeis se uma única API externa falhar. O Turbo reduz taxas de erro, mas não elimina falhas externas.
Developers can access GLM-5 and GLM-5 turbo APIvia CometAPI now.To begin, consult the API guide for detailed instructions. Before accessing, please make sure you have logged in to CometAPI and obtained the API key. CometAPI offer a price far lower than the official price to help you integrate.
Ready to Go?→ Sign up fo GLM-5 and GLM-5 turbo today !