

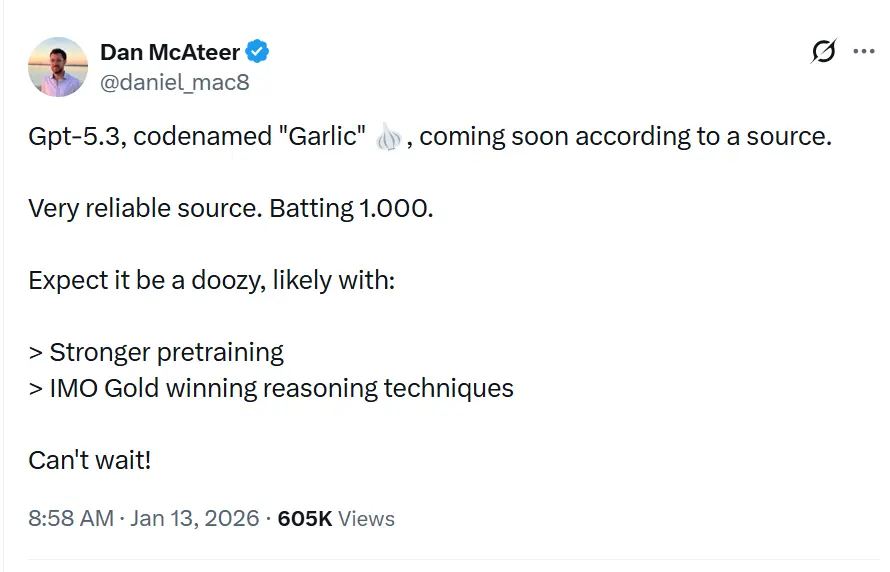
O codinome GPT-5.3“Garlic”, é descrito em vazamentos e reportagens como um próximo lançamento incremental/iterativo da linha GPT-5.x, destinado a fechar lacunas em raciocínio, programação e desempenho de produto para a OpenAI em resposta à pressão competitiva do Gemini do Google e do Claude da Anthropic.
A OpenAI está experimentando uma iteração GPT-5.x mais densa e eficiente, focada em raciocínio mais forte, inferência mais rápida e fluxos de trabalho com contexto mais longo, em vez de simplesmente aumentar continuamente a contagem de parâmetros. Isso não é apenas mais uma iteração da série Generative Pre-trained Transformer; é uma contraofensiva estratégica. Nascido de um "Code Red" interno declarado pelo CEO Sam Altman em dezembro de 2025, “Garlic” representa uma rejeição ao dogma do “maior é melhor” que governou o desenvolvimento de LLMs por meio decênio. Em vez disso, ele aposta tudo em uma nova métrica: densidade cognitiva.
O que é o GPT-5.3 “Garlic”?
GPT-5.3 — codinome “Garlic” — vem sendo descrito como o próximo passo iterativo na família GPT-5 da OpenAI. Fontes que contextualizam o vazamento posicionam o Garlic não como um simples checkpoint ou ajuste de tokens, mas como um refinamento direcionado de arquitetura e treinamento: o objetivo é extrair maior desempenho de raciocínio, melhor planejamento multi-etapas e comportamento aprimorado em contexto longo a partir de um modelo mais compacto e eficiente em inferência, em vez de depender apenas de escala bruta. Essa visão se alinha às tendências mais amplas do setor rumo a projetos de modelos “densos” ou de “alta eficiência”.
O epíteto “Garlic” — um desvio marcante dos codinomes celestiais (Orion) ou botânico-adocicados (Strawberry) do passado — é supostamente uma metáfora interna deliberada. Assim como um único dente de alho pode temperar um prato inteiro de forma mais potente do que ingredientes maiores e mais insossos, este modelo foi projetado para fornecer inteligência concentrada sem a enorme sobrecarga computacional dos gigantes do setor.
A gênese do “Code Red”
A existência do Garlic não pode ser dissociada da crise existencial que lhe deu origem. No fim de 2025, a OpenAI se viu em posição “defensiva” pela primeira vez desde o lançamento do ChatGPT. O Gemini 3 do Google havia conquistado a coroa em benchmarks multimodais, e o Claude Opus 4.5 da Anthropic tornara-se o padrão de fato para programação complexa e fluxos de trabalho agentivos. Em resposta, a liderança da OpenAI pausou projetos periféricos — incluindo experimentos de plataforma de anúncios e expansões de agentes para o consumidor — para focar inteiramente em um modelo capaz de executar um “golpe tático” contra esses concorrentes.
Garlic é esse golpe. Ele não foi projetado para ser o maior modelo do mundo; foi projetado para ser o mais inteligente por parâmetro. Ele funde linhas de pesquisa de projetos internos anteriores, mais notavelmente o “Shallotpeat”, incorporando correções de bugs e eficiências de pré-treinamento que lhe permitem bater acima do seu peso.
Qual é o status atual das iterações observadas do modelo GPT-5.3?
Em meados de janeiro de 2026, o GPT-5.3 está nas etapas finais de validação interna, uma fase muitas vezes descrita no Vale do Silício como “hardening”. O modelo está atualmente visível em logs internos e foi testado pontualmente por alguns parceiros corporativos selecionados sob rígidos acordos de confidencialidade.
Iterações observadas e integração do “Shallotpeat”
A rota até o Garlic não foi linear. Memorandos internos vazados do Chief Research Officer Mark Chen sugerem que o Garlic é na verdade um composto de duas trilhas de pesquisa distintas. Inicialmente, a OpenAI desenvolvia um modelo de codinome “Shallotpeat”, planejado como uma atualização incremental direta. Contudo, durante o pré-treinamento do Shallotpeat, os pesquisadores descobriram um método inédito de “compressão” de padrões de raciocínio — essencialmente ensinando o modelo a descartar vias neurais redundantes mais cedo no processo de treinamento.
Essa descoberta levou ao abandono do lançamento autônomo do Shallotpeat. Sua arquitetura foi mesclada com o ramo mais experimental “Garlic”. O resultado é uma iteração híbrida que possui a estabilidade de uma variante madura do GPT-5, mas a eficiência explosiva de raciocínio de uma nova arquitetura.
Quando podemos inferir que o lançamento ocorrerá?
Prever datas de lançamento da OpenAI é notoriamente difícil, mas o status de “Code Red” acelera cronogramas padrão. Com base na convergência de vazamentos, atualizações de fornecedores e ciclos de concorrentes, podemos triangular uma janela de lançamento.
Janela principal: Q1 2026 (janeiro - março)
O consenso entre insiders é um lançamento no Q1 2026. O “Code Red” foi declarado em dezembro de 2025, com a diretriz de lançar “o mais rápido possível”. Dado que o modelo já está em checagem/validação (a fusão com o “Shallotpeat” tendo acelerado o cronograma), um lançamento no fim de janeiro ou início de fevereiro parece mais plausível.
O lançamento “beta”
Podemos ver um lançamento escalonado:
- Final de janeiro de 2026: um lançamento “preview” para parceiros selecionados e usuários do ChatGPT Pro (possivelmente sob o rótulo “GPT-5.3 (Preview)”).
- Fevereiro de 2026: disponibilidade completa de API.
- Março de 2026: integração na camada gratuita do ChatGPT (consultas limitadas) para contrapor a gratuidade do Gemini.
3 recursos que definem o GPT-5.3?
Se os rumores se confirmarem, o GPT-5.3 introduzirá um conjunto de recursos que priorizam utilidade e integração em vez de criatividade puramente generativa. O conjunto de recursos parece uma lista de desejos para arquitetos de sistemas e desenvolvedores corporativos.
1. Pré-treinamento de alta densidade (EPTE)
A joia da coroa do Garlic é sua Eficiência de Pré-Treinamento Aprimorada (EPTE).
Modelos tradicionais aprendem vendo quantidades massivas de dados e criando uma rede extensa de associações. O processo de treinamento do Garlic supostamente envolve uma fase de “poda” em que o modelo condensa ativamente informações.
- O resultado: um modelo fisicamente menor (em termos de requisitos de VRAM) mas que retém o “Conhecimento de Mundo” de um sistema muito maior.
- O benefício: velocidades de inferência mais rápidas e custos de API significativamente menores, abordando a relação “inteligência versus custo” que tem impedido a adoção em massa de modelos como o Claude Opus.
2. Raciocínio agentivo nativo
Diferentemente de modelos anteriores que exigiam “wrappers” ou engenharia de prompt complexa para funcionar como agentes, o Garlic tem capacidades nativas de chamada de ferramentas.
O modelo trata chamadas de API, execução de código e consultas a banco de dados como “cidadãos de primeira classe” em seu vocabulário.
- Integração profunda: ele não apenas “sabe programar”; entende o ambiente do código. Supostamente consegue navegar por um diretório de arquivos, editar múltiplos arquivos simultaneamente e executar seus próprios testes de unidade sem scripts externos de orquestração.
3. Janelas massivas de contexto e de saída
Para competir com a janela de contexto de um milhão de tokens do Gemini, o Garlic deve chegar com uma janela de contexto de 400,000 tokens. Embora menor que a oferta do Google, o diferencial-chave é a “Lembrança Perfeita” ao longo dessa janela, utilizando um novo mecanismo de atenção que evita a perda “no meio do contexto” comum em modelos de 2025.
- Limite de saída de 128k: talvez mais empolgante para desenvolvedores seja a expansão, segundo rumores, do limite de saída para 128,000 tokens. Isso permitiria ao modelo gerar bibliotecas de software inteiras, peças jurídicas abrangentes ou novelas completas em uma única passada, eliminando a necessidade de “fragmentação”.
4. Alucinação drasticamente reduzida
O Garlic utiliza uma técnica de reforço pós-treinamento focada em “humildade epistêmica” — o modelo é rigorosamente treinado para saber o que ele não sabe. Testes internos mostram uma taxa de alucinação significativamente menor do que a do GPT-5.0, tornando-o viável para setores de alto risco como biomedicina e direito.
Como ele se compara a concorrentes como Gemini e Claude 4.5?
O sucesso do Garlic não será medido isoladamente, mas em comparação direta com os dois titãs que atualmente dominam a arena: o Gemini 3 do Google e o Claude Opus 4.5 da Anthropic.
GPT-5.3 “Garlic” vs. Google Gemini 3
A batalha entre escala e densidade.
- Gemini 3: atualmente o modelo “tudo em um”. Domina em compreensão multimodal (vídeo, áudio, geração nativa de imagens) e tem uma janela de contexto efetivamente infinita. É o melhor modelo para dados “bagunçados” do mundo real.
- GPT-5.3 Garlic: não consegue competir com a amplitude multimodal bruta do Gemini. Em vez disso, ataca o Gemini na pureza do raciocínio. Para geração de texto puro, lógica de código e seguimento de instruções complexas, o Garlic busca ser mais afiado e menos propenso a “recusas” ou divagações.
- O veredicto: se você precisa analisar um vídeo de 3 horas, use o Gemini. Se precisa escrever o backend de um app bancário, use o Garlic.
GPT-5.3 “Garlic” vs. Claude Opus 4.5
A batalha pela alma do desenvolvedor.
- Claude Opus 4.5: lançado no final de 2025, conquistou desenvolvedores com sua “calidez” e “vibes”. É famoso por escrever código limpo, legível por humanos, e por seguir instruções de sistema com precisão militar. Entretanto, é caro e lento.
- GPT-5.3 Garlic: este é o alvo direto. O Garlic busca igualar a proficiência de programação do Opus 4.5, porém a 2x a velocidade e 0,5x o custo. Usando “Pré-treinamento de Alta Densidade”, a OpenAI quer oferecer inteligência em nível Opus com orçamento de Sonnet.
- O veredicto: o “Code Red” foi especificamente acionado pela dominância do Opus 4.5 em programação. O sucesso do Garlic depende inteiramente de convencer desenvolvedores a voltarem suas chaves de API para a OpenAI. Se o Garlic programar tão bem quanto o Opus, mas rodar mais rápido, o mercado mudará da noite para o dia.
Principais conclusões
Builds internos iniciais do Garlic já superam o Gemini 3 do Google e o Opus 4.5 da Anthropic em domínios específicos e de alto valor:
- Proficiência em programação: em benchmarks “duros” internos (além do HumanEval padrão), o Garlic mostrou menor tendência a ficar preso em “loops de lógica” em comparação com o GPT-4.5.
- Densidade de raciocínio: o modelo requer menos tokens de “pensamento” para chegar a conclusões corretas, em contraste direto com a “pesadez de chain-of-thought” da série o1 (Strawberry).
| Métrica | GPT-5.3 (Garlic) | Google Gemini 3 | Claude 4.5 |
|---|---|---|---|
| Raciocínio (GDP-Val) | 70.9% | 53.3% | 59.6% |
| Programação (HumanEval+) | 94.2% | 89.1% | 91.5% |
| Janela de contexto | 400K Tokens | 2M Tokens | 200K Tokens |
| Velocidade de inferência | Ultrarrápida | Moderada | Rápida |
Conclusão
“Garlic” é um rumor ativo e plausível: uma trilha de engenharia da OpenAI focada em priorizar densidade de raciocínio, eficiência e ferramentas para o mundo real. Seu surgimento deve ser visto no contexto de uma corrida armamentista acelerada entre provedores de modelos (OpenAI, Google, Anthropic) — na qual o prêmio estratégico não é apenas capacidade bruta, mas capacidade utilizável por dólar e por milissegundo de latência.
Se você tem interesse nesse novo modelo, acompanhe o CometAPI. Ele sempre atualiza com os melhores e mais recentes modelos de IA a um preço acessível.
Developers can access GPT-5.2 ,Gemini 3, Claude 4.5 through CometAPI Now. Para começar, explore as capacidades de modelos do CometAPI no Playground e consulte o guia da API para instruções detalhadas. Antes de acessar, certifique-se de que você fez login no CometAPI e obteve a chave de API. CometAPI oferece um preço muito inferior ao preço oficial para ajudar na sua integração.
Pronto para começar?→ Cadastre-se no CometAPI hoje!
Se quiser mais dicas, guias e notícias sobre IA, siga-nos no VK, X e Discord!