
.png&w=3840&q=75)
GPT-5.4 Mini e GPT-5.4 Nano são as novas variantes compactas da família de ponta GPT-5.4 da OpenAI: a Mini busca o melhor equilíbrio entre desempenho e latência para tarefas de programação, UI multimodal e cargas de trabalho de subagentes; a Nano busca custo e latência ultrabaixos para classificação, extração, ranqueamento e subagentes massivamente paralelos. A Mini oferece precisão próxima à de modelos de ponta em muitos benchmarks de desenvolvimento enquanto roda >2× mais rápido que minis anteriores; a Nano é significativamente mais barata por token e ideal onde taxa de transferência e responsividade são os fatores mais importantes. Esses modelos já estão disponíveis na API (GPT 5.4 Mini e Nano estão disponíveis na CometAPI).
O que são GPT-5.4 Mini e GPT-5.4 Nano?
Definição breve: GPT-5.4 Mini e GPT-5.4 Nano são variantes compactas e engenheiradas da família GPT-5.4, projetadas para trazer os pontos fortes centrais do GPT-5.4 de grande porte (raciocínio, programação, percepção multimodal, uso de ferramentas) para modelos mais rápidos e de menor custo, voltados a cargas de trabalho de alto volume e baixa latência. Os modelos foram anunciados pela OpenAI como parte do lançamento do GPT-5.4.
- GPT-5.4 Mini — Um modelo pequeno de alto desempenho que “se aproxima do desempenho do GPT-5.4 em várias avaliações”, otimizado para velocidade e menor custo. É especificamente destacado para programação, raciocínio, interpretação de UI multimodal (capturas de tela) e como subagente em sistemas agentivos. A OpenAI relata que ele roda mais de 2× mais rápido que variantes “mini” anteriores.
- GPT-5.4 Nano — A menor e mais barata variante GPT-5.4; recomendada para classificação, extração, ranqueamento e subagentes “de apoio” que lidam com tarefas estreitas e repetitivas com altíssima taxa de transferência. Ele troca profundidade de raciocínio por economia de latência e custo.
Disponibilidade e preço
A OpenAI fornece dois pontos de dados concretos para comparar custos:
- Preço de entrada da API do GPT-5.4 (modelo principal): $2.50 / 1M tokens (e preço de saída mais alto no modelo principal).
- Preço de entrada da API do GPT-5.4 mini: $0.75 / 1M tokens e saída $4.50 / 1M tokens.
- Preço de entrada da API do GPT-5.4 nano: $0.20 / 1M e saída $1.25 / 1M.
Colocando lado a lado: o preço por token de entrada da mini (0.75) é 30% do modelo principal (2.50), portanto aproximadamente um terço do custo de entrada; o preço de saída da mini (4.50) é cerca de 32% de um preço de saída do modelo principal citado na tabela de preços da API, ou seja, também cerca de um terço. A nano é ainda mais barata: seu custo de entrada é cerca de 8% do custo de entrada do modelo principal, e seu custo de saída é inferior a 10% do custo de saída do modelo principal. Essas proporções explicam por que a OpenAI apresenta a mini/nano como “cerca de um terço” (mini) e “uma fração de” (nano) do custo de usar os maiores modelos para tarefas de alto volume. O preço do token da nano subiu de $0.05 para $0.20, e o preço do token da mini subiu de $0.25 para $0.75 (para tokens de entrada).
Na plataforma da OpenAI
A GPT-5.4 mini está disponível em três lugares: a API da OpenAI, o Codex (a plataforma IDE/app para desenvolvedores da OpenAI) e o ChatGPT (disponível para usuários Free e Go pela opção “Thinking” e como fallback em caso de limite de taxa para planos pagos). Na API, ela suporta entradas de texto e imagem, uso de ferramentas (function calling), busca web/arquivos, uso de computador e skills — e oferece uma janela de contexto muito grande (400k tokens) para atender fluxos com muitos documentos e várias capturas de tela. A precificação da API é $0.75 por 1M tokens de entrada e $4.50 por 1M tokens de saída.
A GPT-5.4 nano está disponível apenas pela API. Seus preços de tabela são $0.20 por 1M tokens de entrada e $1.25 por 1M tokens de saída — posicionando-a como a opção de menor custo na família GPT-5.4. O modelo nano deliberadamente troca capacidade por custo e velocidade.
Em plataforma de terceiros
A CometAPI é uma plataforma de agregação multimodal de APIs de IA que agora lançou a API da Série GPT 5.4, incluindo GPT 5.4 Mini e GPT 5.4 Nano, com 20% de desconto em relação ao preço da OpenAI.
GPT 5.4 Nano:
| Comet Price (USD / M Tokens) | Official Price (USD / M Tokens) |
|---|---|
| Input:$0.16/M; Output:$1/M | Input:$0.2/M; Output:$1.25/M |
GPT 5.4 Nano:
| Comet Price (USD / M Tokens) | Official Price (USD / M Tokens) |
|---|---|
| Input:$0.6/M; Output:$3.6/M | Input:$0.75/M; Output:$4.5/M |
Principais recursos e o que há de novo
Abaixo estão as capacidades em destaque — por que engenheiros e equipes de produto vão se importar.
Codificação e suporte a contexto longo
Janela de contexto: a GPT-5.4 mini suporta uma janela de contexto de 400k tokens (a OpenAI lista explicitamente a mini com 400k de contexto). Isso é suficiente para bases de código com múltiplos arquivos, documentos extensos ou sessões de agente de múltiplas turnos em que o contexto importa. O contexto da Nano é menor em relação ao GPT-5.4 completo, mas ainda substancial para tarefas curtas e rápidas.
Raciocínio
Níveis de raciocínio: a OpenAI expõe o reasoning_effort configurável (none → xhigh); mini e nano podem operar com diferentes níveis de esforço, mas a mini reduz a diferença em relação ao GPT-5.4 completo em muitos benchmarks de raciocínio quando em esforço mais alto. Em vários benchmarks de inteligência (por exemplo, GPQA Diamond), a mini atinge 88.0% contra 93.0% do GPT-5.4, e a nano registra 82.8%, indicando raciocínio respeitável para um modelo pequeno. Esses são os resultados publicados pela OpenAI em seu post de lançamento.
Compreensão multimodal (visão e UI)
Percepção visual e tarefas de UI: a GPT-5.4 mini apresenta desempenho multimodal muito forte em tarefas de UI (capturas de tela, imagens de documentos densos). No OSWorld-Verified (um benchmark de uso de computador), a mini marca 72.1%, bem próxima dos 75.0% do GPT-5.4 e muito acima das minis anteriores — por isso a mini é posicionada para automações guiadas por capturas de tela e assistentes multimodais responsivos. A nano tem desempenho menor em benchmarks visuais, mas ainda é útil para tarefas simples com imagens.
Invocação de ferramentas e uso de computador
Capacidades nativas de ferramenta/clique: o GPT-5.4 introduz e amplia recursos nativos de uso de computador; a mini herda a capacidade de chamar ferramentas, fazer chamadas de função, interpretar capturas de tela e orquestrar subagentes. Benchmarks de chamadas de ferramenta (Toolathlon, MCP Atlas) mostram mini e nano com pontuações respeitáveis (Toolathlon: mini 42.9%, nano 35.5%) — quantificando sua habilidade de chamar e coordenar ferramentas externas. Essas métricas são do anúncio da OpenAI.
Alucinação / factualidade / taxas de erro
A OpenAI relata que o GPT-5.4 é o “modelo mais factual até agora” e mostra reduções de alucinação vs GPT-5.2; mini e nano apresentam factualidade absoluta menor que o modelo completo (por exemplo, HLE com ferramentas: GPT-5.4 52.1%, mini 41.5%, nano 37.7%), o que sugere uma necessidade maior de verificação quando modelos menores são usados em tarefas com alto requisito factual. Use verificação baseada em ferramentas (chamadas de ferramentas, recuperação de citações) quando a correção for crítica.
Velocidade
A OpenAI relata que a GPT-5.4 mini roda mais de 2× mais rápido que a GPT-5 mini anterior em estimativas de latência típicas de produção (com base em comportamento de produção simulado que inclui durações de chamadas de ferramentas e amostragem de tokens). Esse ganho de velocidade é uma afirmação central para a nova família e permite usar a mini como subagente responsivo em apps interativos como assistentes de programação.
Como mini e nano se saem — eles “se aproximam” do GPT-5.4 completo?
A OpenAI publicou um conjunto abrangente de comparações de benchmarks em programação, uso de ferramentas, tarefas multimodais de uso de computador, testes de inteligência e avaliações de contexto longo. Os números principais (com esforço de raciocínio xhigh quando aplicável) incluem:
| Benchmark | GPT-5.4 | GPT-5.4 Mini | GPT-5.4 Nano | GPT-5 Mini (Antigo) | Notas |
|---|---|---|---|---|---|
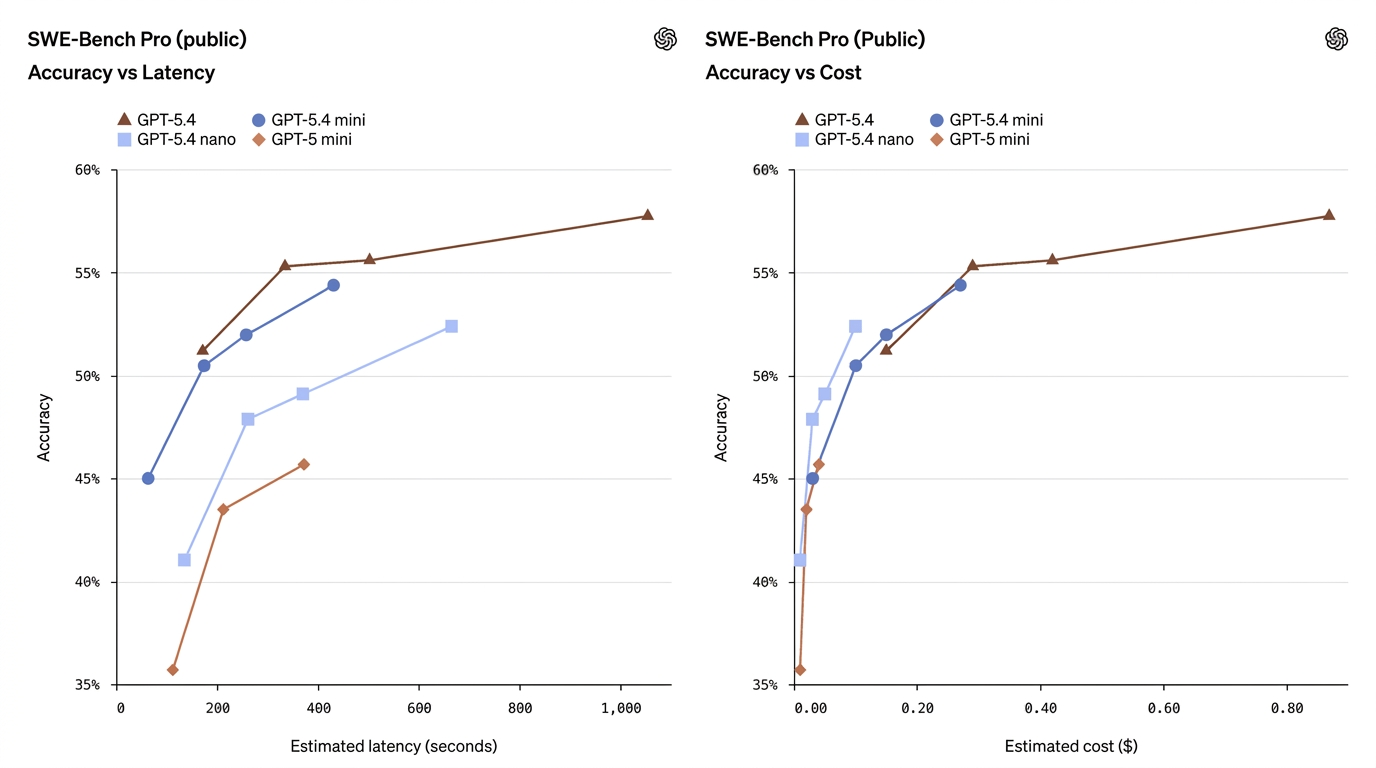
| SWE-Bench Pro (Programação) | 57.7% | 54.4% | 52.4% | 45.7% | Mini se aproxima do desempenho do modelo completo em programação |
| Terminal-Bench 2.0 (Programação interativa) | 75.1% | 60.0% | 46.3% | — | Forte capacidade de programação em tempo real para a Mini |
| Toolathlon (Uso de ferramentas) | 54.6% | 42.9% | 35.5% | — | Mede orquestração e chamadas de ferramentas |
| GPQA Diamond (QA avançado) | 93.0% | 88.0% | 82.8% | — | Benchmark de inteligência e raciocínio |
| OSWorld-Verified (Tarefas de GUI) | 75.0% | 72.1% | 39.0% | 42.0% | Capacidade de UI/uso de computador |
Esses números mostram que a mini muitas vezes reduz bastante a diferença — especialmente em programação e uso de computador — enquanto a nano ocupa um meio-termo útil entre capacidade e custo.
O que esses números significam em termos simples?
- GPT-5.4 Mini ≈ “quase principal” em muitas tarefas de produção. No SWE-Bench Pro (métrica de taxa de acerto em programação), a mini marca 54.4% vs 57.7% do modelo principal — um pequeno gap relativo para muitas tarefas de programação do mundo real, especialmente quando a latência importa. No OSWorld (uso de computador), a mini faz 72.1% contra 75.0% — novamente, muito próximo em tarefas de UI/capturas de tela.
- GPT-5.4 Nano troca mais capacidade por velocidade/custo. A pontuação de programação da nano (52.4% no SWE-Bench Pro) é respeitável em relação às minis mais antigas, mas sua pontuação no OSWorld cai para 39.0%, mostrando que, para tarefas que exigem compreensão complexa de UI com múltiplas etapas ou sequências agentivas de ferramentas, a nano é menos adequada. A nano brilha em classificação de turno único, extração e pequenas tarefas auxiliares.
- Uso de ferramentas melhora, mas permanece sensível. As métricas do Toolathlon e de outros testes de uso de ferramentas sobem substancialmente ao migrar da GPT-5 mini para as GPT-5.4 mini/nano, mostrando que a engenharia da OpenAI melhorou a confiabilidade na invocação de ferramentas nos modelos de menor porte — mas o modelo completo ainda lidera em orquestração de ferramentas complexa.
Como funcionam em produção
Compressão, destilação e otimizações de engenharia
Modelos compactos como mini/nano normalmente usam uma combinação de destilação de modelo, quantização e poda arquitetural para preservar capacidades de alto valor (heurísticas de programação, perceptos visuais) enquanto reduzem o custo de inferência. A redação da OpenAI indica engenharia focada em preservar conjuntos de habilidades específicos (programação, compreensão de UI multimodal) nos footprints menores.
Padrões recomendados
- Padrão orquestrador + subagente: Use o GPT-5.4 (grande) como planejador/árbitro e distribua trabalho para subagentes GPT-5.4 mini / nano para execução rápida (buscar, analisar, editar). Isso reduz o custo total e a latência para o usuário. A OpenAI endossa explicitamente esse padrão de design.
- Fallback e tratamento de limite de taxa: Exponha a mini como fallback de limite de taxa no ChatGPT ou no Codex para que consultas sensíveis ao tempo ainda recebam uma resposta capaz quando o modelo completo estiver indisponível.
- Arquitetura em camadas para controle de custos: Pipelines em massa (indexação, extração) → GPT-5.4 nano; componentes de UI interativos → GPT-5.4 mini; julgamento editorial final / encadeamentos complexos → GPT-5.4 completo. Essa abordagem multicamada equilibra custo e capacidade.
Latência e paralelização
Mini e nano são otimizadas para subagentes paralelos, onde muitos pequenos workers rodam simultaneamente — por exemplo, varrendo milhares de PDFs em paralelo. O conceito de “tool yields” da OpenAI mede como chamadas de ferramentas paralelas reduzem a latência de relógio; mini/nano são engenheiradas para tornar esses padrões custo-efetivos.
Como eu usaria mini e nano na prática
Devo substituir minhas chamadas ao modelo principal por mini/nano em todos os lugares?
Não automaticamente. O padrão correto que a OpenAI recomenda explicitamente é a delegação: use um modelo maior para planejamento, julgamento complexo ou verificação final e distribua muitas subtarefas de suporte e mais curtas para subagentes mini ou nano. Esse padrão reduz custo e latência enquanto mantém os guardrails do modelo maior onde eles mais importam. Casos de uso:
- Assistentes de programação interativos: o modelo principal planeja e revisa; a mini lida com buscas rápidas de código, edições e pequenos testes unitários.
- Agentes de “uso de computador” orientados por capturas de tela: a mini consegue analisar interfaces densas rapidamente; o modelo principal resolve planejamentos ambíguos de múltiplas etapas.
- Pipelines de extração e classificação de alto volume: a nano processa enormes lotes (formulários, logs) e retorna resultados estruturados; o modelo principal lida com exceções e casos-limite complexos.
Mini ou nano podem ser usados para tarefas multimodais ou com imagens?
Sim — a mini suporta entradas de imagem e tem bom desempenho em benchmarks multimodais/vision-driven (MMMUPro/OmniDocBench), aproximando-se do modelo principal em alguns testes. A força multimodal da nano é mais limitada: embora melhore em relação às nanos anteriores, não é a melhor escolha para raciocínio multimodal profundo ou tarefas agentivas baseadas em imagem.
A corrida por capacidades de modelos pequenos se intensificou
Três meses atrás, modelos pequenos eram considerados “bons o suficiente”. Agora, a GPT-5.4 mini está se aproximando de modelos principais em benchmarks de programação e praticamente empatando em desempenho computacional.
A tendência por trás disso é clara: as capacidades dos modelos principais estão sendo rapidamente transferidas para modelos menores. OpenAI, Google e Anthropic estão fazendo o mesmo: destilando as capacidades centrais de modelos grandes em versões menores, mais rápidas e mais baratas.
Conclusão
O lançamento desses dois modelos sinaliza uma mudança nas aplicações de IA de um foco em escala para um foco em eficiência prática. Com capacidades de resposta rápida, eles oferecem suporte de base mais confiável para interação em tempo real com IA e para o desmembramento de fluxos de tarefas complexos.
Para desenvolvedores, isso significa que a estrutura de custos dos sistemas de agentes está sendo redefinida. Quando os custos caem a esse nível, muitos cenários de agentes que antes eram “teoricamente viáveis, mas economicamente inviáveis” tornam-se exequíveis.
Os desenvolvedores podem acessar GPT 5.4 Mini e GPT-5.4 Nano via CometAPI agora. Antes de acessar, certifique-se de que você fez login na CometAPI e obteve a chave de API. A CometAPI oferece um preço muito inferior ao preço oficial para ajudar na integração.
Pronto para começar?