

xAI lançado discretamente Grok 4.1 (17 a 18 de novembro de 2025) — uma atualização focada no Grok 4 que prioriza inteligência emocional, expressão criativa e redução de alucinações mantendo o raciocínio preciso das versões anteriores do Grok, ele chega em dois modos (Pensamento/Não Pensamento), foi lançado silenciosamente no início de novembro, exibe os melhores resultados no ranking do LMArena e está disponível em grok.com, nos aplicativos Grok e na API.
O que é Grok 4.1?
O Grok 4.1 é o sucessor incremental e focado em produção do Grok 4: um membro da família construído sobre a mesma base de aprendizado por reforço em larga escala, mas refinado e re-treinado com otimizações pós-treinamento significativas, visando estilo, personalidade, alinhamento e confiabilidade no mundo real. Ele está sendo posicionado como um passo pragmático e "utilizável" adiante: mais inteligente em testes cegos de preferência humana, mais inteligente emocionalmente, melhor em escrita criativa e mensuravelmente menos propenso ao tipo de "alucinações" confiantes, porém equivocadas, que atormentaram versões anteriores de alto desempenho de softwares de aprendizado de máquina.
O Grok 4.1 alcança mudanças qualitativas nas seguintes quatro dimensões:
- Criatividade: Demonstra um estilo de linguagem e imaginação mais apurados na escrita, na narração de histórias e em contextos sociais;
- Inteligência Emocional: Reconhece o tom de voz e as mudanças emocionais, respondendo com uma lógica emocional mais humana e gerando respostas reconfortantes e compreensivas;
- Coerência de personalidade: Mantém tom e personalidade consistentes em conversas longas, não exibindo mais o comportamento inconsistente de modelos anteriores;
- Colaborativo: Mantém a coerência e a consciência dos objetivos em diálogos com múltiplas interações ou em colaboração em tarefas.
A xAI resume suas características em uma frase: "É mais perspicaz, mais empática e mais parecida com uma pessoa coerente."
Como o Grok 4.1 funciona internamente?
O Grok 4.1 pode ser melhor compreendido como a mesma estrutura pré-treinada usada em toda a família Grok 4, acrescida de um pipeline de pós-treinamento em camadas que se concentra em modelagem de recompensas, alinhamento de estilo e avaliadores agentes.
Quais são as etapas de treinamento e alinhamento?
O Grok 4.1 funciona com um pipeline de múltiplas etapas, típico dos modernos LLMs de ponta, adaptado com duas mudanças importantes para a versão 4.1:
- Pré-treino + meio do treino: Pré-treinamento com um grande corpus de dados da web + treinamento intermediário direcionado para aprimorar o conhecimento do domínio e as capacidades multimodais.
- Ajuste fino supervisionado (SFT): Demonstrações humanas de comportamentos desejados (respostas, estratégias de recusa).
- Modelagem de recompensas (aplicação inovadora): Os modelos de recompensa treinados pela xAI não se baseiam apenas em rótulos de preferência humana, mas também utilizam modelos de raciocínio agentivo de fronteira como avaliadores de recompensas — permitindo efetivamente que avaliadores altamente capacitados, baseados em modelos, pontuem as saídas dos candidatos em escala. Isso possibilitou a otimização de atributos não verificáveis, como estilo, coesão de personalidade, empatia e prestatividade sem exigir um orçamento absurdamente grande para rotulagem humana.
- Otimização de políticas (RLHF / RL a partir de recompensas do modelo): Otimização de política padrão usando os sinais de recompensa aprendidos para produzir a política implementada (a política com a qual os consumidores do modelo interagem).
O que há de novo na abordagem de modelagem de recompensas?
No RLHF tradicional, você coleta rótulos de preferência humana (A/B), treina um modelo de recompensa para prever esses rótulos e, em seguida, otimiza o modelo base com RL (ou amostragem por rejeição) em relação a essa recompensa aprendida. Mas a xAI destaca duas inovações práticas:
- Modelos de recompensa agentiva: Em vez de juízes puramente humanos, a xAI utiliza modelos de raciocínio "agente" capazes como avaliadores para analisar propriedades mais sutis (tom, nuances emocionais, criatividade). Os avaliadores podem realizar milhares de comparações aos pares rapidamente, permitindo que os engenheiros iterem mais rapidamente. Esse é o mecanismo que possibilita grandes melhorias em estilo e inteligência emocional.
- Alinhamento pós-treinamento para sinais não verificáveis: Para atributos que não podem ser medidos com uma métrica determinística (por exemplo, "afeto" ou "personalidade coerente"), foram introduzidos objetivos de recompensa especializados e currículos de escalonamento para que o modelo aprenda. estilo de resultados sem sacrificar a precisão factual essencial.
Como funciona tecnicamente a distinção entre "pensar" e "não pensar"?
- Grok 4.1 Pensamento (codinome)
quasarflux) — Expõe etapas de raciocínio explícitas (tokens de pensamento) antes de produzir a resposta final; otimizado para tarefas complexas e níveis Elo mais altos no LMArena. Os tokens extras aumentam o tempo de inferência, mas auxiliam em tarefas de raciocínio com múltiplas etapas, depuração e explicabilidade. - Grok 4.1 Não-Pensamento (codinome)
tensor) O modo de processamento ignora tokens intermediários explícitos para uma resposta final única e imediata. Isso reduz a latência e o custo do token, mantendo os mesmos pesos de política refinados. O modo de processamento automático foi otimizado para oferecer latência extremamente baixa e, ainda assim, alta capacidade.
Otimização do alinhamento de sentimento e estilo
Além de simples sinais de "veracidade", o Grok 4.1 inclui otimização de alinhamento direcionada para sentimento, tom e estilo interpessoal. Isso significa que o processo de treinamento inclui componentes de recompensa ou perda que punem explicitamente o tom inadequado (por exemplo, ser desnecessariamente seco quando a empatia é apropriada) e recompensam respostas que correspondem a um perfil de estilo ou sentimento desejado. No Grok 4.1, a IA introduziu pela primeira vez o objetivo de otimização de "Alinhamento de Personalidade".
Tem como objetivo ajudar o modelo a manter um senso de identidade consistente e estável. Em comparação com o Grok 4, a versão 4.1 adiciona os seguintes objetivos de treinamento:
- Recompensas positivas para a dimensão da expressão emocional (recompensa de alinhamento emocional);
- Uma métrica de coerência de personalidade.
Como o Grok 4.1 foi avaliado — e qual foi o seu desempenho?
O que demonstraram os testes de preferência humana realizados às cegas?
Durante uma implementação silenciosa, o Grok 4.1 foi preferido em 64.78% das vezes em comparação com o modelo de produção anterior em tráfego real — um forte sinal de preferência humana que indica melhores resultados de conversação em situações reais.
Será que Grok 4.1 está no topo das tabelas de classificação?
A xAI relata que o Grok 4.1 Pensando modo está em #1 na Arena de Texto da LMArena, com um Elo relatado de 1483, e seu modo não racional (rápido) ocupa o 2º lugar com 1465 Elo — ótimas colocações nos placares públicos tanto em precisão quanto em apresentação (o controle de estilo desempenha um papel importante).
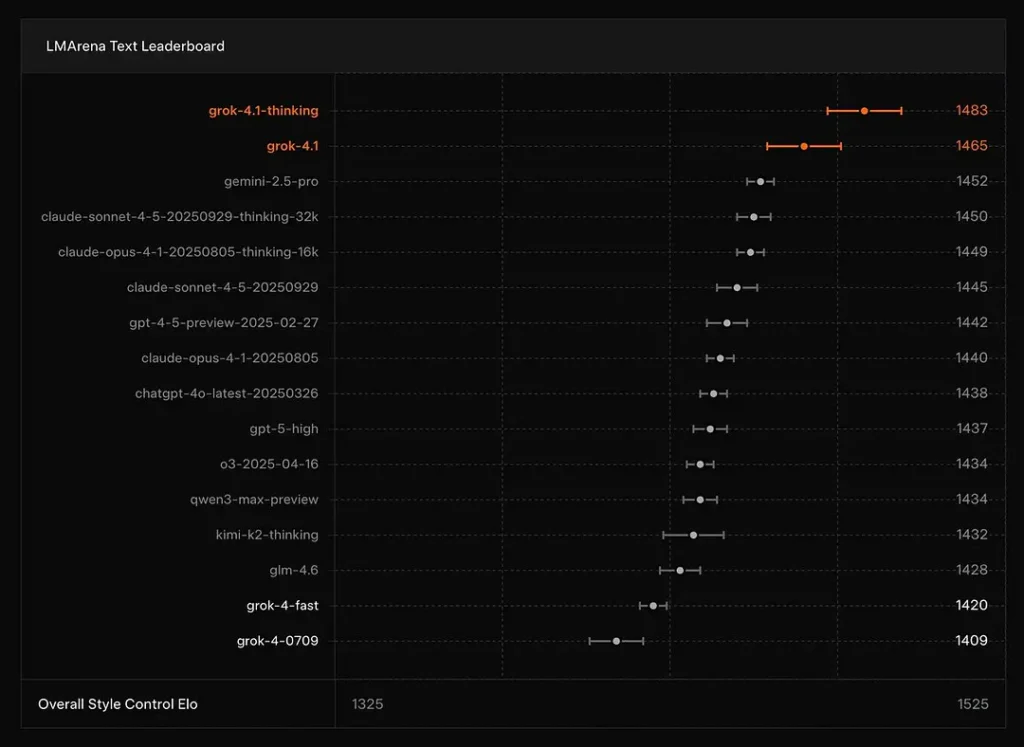
Conclusão: O Grok 4.1 supera os modelos convencionais GPT-4.5 e da série Claude em compreensão de texto, geração e qualidade geral, ficando atrás apenas da versão GPT-5 Advanced Preview.
Inteligência Emocional
A xAI realizou o EQ-Bench3, um teste especializado em inteligência emocional que abrange 45 cenários desafiadores de dramatização, e relata que o Grok 4.1 apresenta ganhos significativos em empatia, ritmo e percepção interpessoal. O Grok 4.1 obteve a pontuação mais alta na compreensão de contextos de tristeza, empatia e conforto.

A escrita criativa — será que é realmente mais imaginativa?
O Grok 4.1 foi avaliado em Escrita Criativa v3 (32 prompts em 3 iterações com rubrica + pontuação Elo). A xAI afirma que o estilo de escrita, a consistência da voz e a criatividade narrativa da versão 4.1 aumentaram substancialmente, colocando-a perto do topo dos rankings recentes para tarefas criativas (exemplos de prompts estão incluídos no comunicado). Relatórios independentes corroboraram essas descobertas: os avaliadores observaram uma “voz distinta” notavelmente mais pronunciada e uma melhor coerência em textos mais longos. Em termos de qualidade de escrita, o Grok 4.1 fica atrás apenas dos modelos da série GPT-5 e supera toda a linha de produtos do Claude, Gemini e Kimi.

Redução de alucinações / honestidade
A xAI afirma ter reduzido significativamente as taxas de alucinações: eles relataram (no anúncio e nas postagens em redes sociais) que o Grok 4.1 é ~3 vezes menos propenso a ter alucinações Em comparação com modelos Grok anteriores, que citam análises de tráfego de produção e avaliações no estilo FActScore (por exemplo, conjuntos de perguntas biográficas, em que quanto menor, melhor), a consistência dos fatos é mais estável, especialmente no "modo sem raciocínio", onde ferramentas de busca externas estão disponíveis.

Por que o Grok 4.1 "supera" outros modelos — isso é um exagero?
"Crushes" soa como marketing, mas há afirmações objetivas por trás dessa afirmação:
- Classificação: O Grok 4.1 ocupa as primeiras posições nos rankings públicos do LMArena para geração de texto (1483 Elo no modo Thinking) e apresenta um desempenho sólido em criatividade e no teste EQ-bench, de acordo com o lançamento do xAI. Essas são métricas competitivas comparáveis, utilizadas por toda a comunidade.
- A preferência por tráfego real vence: A xAI relata que, em comparações às cegas (preferência de aproximadamente 65% em relação ao modelo de produção anterior), a partir de uma implementação silenciosa em tráfego real, a xAI obteve resultados superiores na preferência dos usuários. Isso reflete melhorias reais na experiência do usuário, e não apenas em benchmarks teóricos.
- Nova capacidade prática: A combinação de classificadores de modelos, aprendizado por reforço em sinais não verificáveis e filtros de entrada mais rigorosos é uma medida de engenharia pragmática que melhora diretamente a experiência do usuário em tarefas conversacionais, empáticas e criativas, nas quais os concorrentes historicamente apresentam desempenho inferior.
Portanto, embora "arrasar" seja uma forma expressiva de dizer "liderar em diversas avaliações públicas e internas", as métricas públicas subjacentes publicadas pela xAI corroboram essa conclusão.
Como acessar o Grok 4.1
Acesso do consumidor/aplicativo
A xAI disponibiliza periodicamente o Grok 4.1 no modo "Automático" gratuitamente ou em períodos promocionais, mas os planos premium (SuperGrok, SuperGrok Heavy) e o acesso à API com quotas maiores existem e continuam sendo oferecidos como serviços pagos.
O Grok 4.1 está disponível para todos os usuários. on grok.com, X (antigo Twitter), e os aplicativos Grok para iOS e Android, sendo lançados imediatamente no modo Automático, podendo também ser selecionados explicitamente como “Grok 4.1” no seletor de modelos.
Acesso à API e planos para desenvolvedores
Os endpoints do Grok 4.1 estão disponíveis através da API xAI. Até a data de publicação deste artigo, a API oficial do GPT 4.1 ainda não foi lançada.
CometAPI promete acompanhar a dinâmica mais recente dos modelos, incluindo API do Grok 4.1, que será lançado simultaneamente com o lançamento oficial. Aguarde e continue acompanhando o CometAPI. Enquanto isso, você pode conferir outros modelos do Grok, como Grok-código-rápido-1 e Grok 4Explore as funcionalidades no Playground e consulte o guia da API para obter instruções detalhadas sobre como fazer chamadas. Antes de acessar, certifique-se de ter feito login no CometAPI e obtido a chave da API.
Dicas práticas para usar o Grok 4.1 na produção
Como reduzir o risco de alucinações
- Ativar pesquisa ao vivo ou uma cadeia de ferramentas verificada para consultas de busca de informações.
- Forneça etapas de verificação: peça ao modelo que retorne fontes e evidências para afirmações factuais; use o
responsemetadados para inspecionar citações (se disponíveis). - Executar verificações determinísticas (verificação de fatos em LLMs, validadores de dados estruturados) como uma etapa de pós-processamento para resultados de alto risco.
Como controlar o tom e o estilo
- Use instruções explícitas do sistema para corrigir a voz (“Você é formal e empático.”).
- Use instruções supervisionadas e pequenos modelos locais para garantir uma voz consistente em todos os aplicativos.
- Quando disponível, utilize a opção de controle de estilo do xAI e os botões de direção com recompensa.
Veredito final: o Grok 4.1 representa uma mudança radical?
Grok 4.1 é não uma arquitetura totalmente nova; em vez disso, trata-se de uma arquitetura sofisticada e bem pensada. pós-treinamento / alinhamento Lançamento que se concentra no que os humanos realmente valorizam no chat: personalidade, inteligência emocional, criatividade e menos erros factuaisGanhos mensuráveis em rankings, preferências de tráfego real em larga escala e ferramentas de segurança aprimoradas. Para aplicações que dependem de conversas de alta qualidade, colaboração criativa ou assistência sensível ao tom de voz, o Grok 4.1 representa um grande avanço e, em diversos benchmarks da comunidade, foi o aplicativo com melhor desempenho no momento do lançamento.
A CometAPI é uma plataforma comercial de agregação de APIs que oferece aos desenvolvedores acesso unificado, no estilo REST da OpenAI, a centenas de modelos de IA de diversos fornecedores — modelos de linguagem natural para texto, geradores de imagem/vídeo, embeddings e muito mais — por meio de uma interface única e consistente. Em vez de configurar SDKs separados ou endpoints personalizados para OpenAI, Anthropic, Google, Meta ou outros fornecedores de modelos especializados, a CometAPI permite que você acesse diferentes modelos alterando as strings de modelo e alguns parâmetros.
Pronto para experimentar?→ Inscreva-se no CometAPI hoje mesmo !
Se você quiser saber mais dicas, guias e novidades sobre IA, siga-nos em VK, X e Discord!