
grok-code-fast-1 é o modelo de codificação agentivo da xAI, focado em velocidade e eficiente em custos, projetado para impulsionar integrações com IDEs e agentes de codificação automatizados. Ele enfatiza baixa latência, comportamentos agentivos (chamadas de ferramentas, rastros de raciocínio passo a passo) e um perfil de custo compacto para os fluxos de trabalho cotidianos de desenvolvedores.
Principais recursos (visão geral rápida)
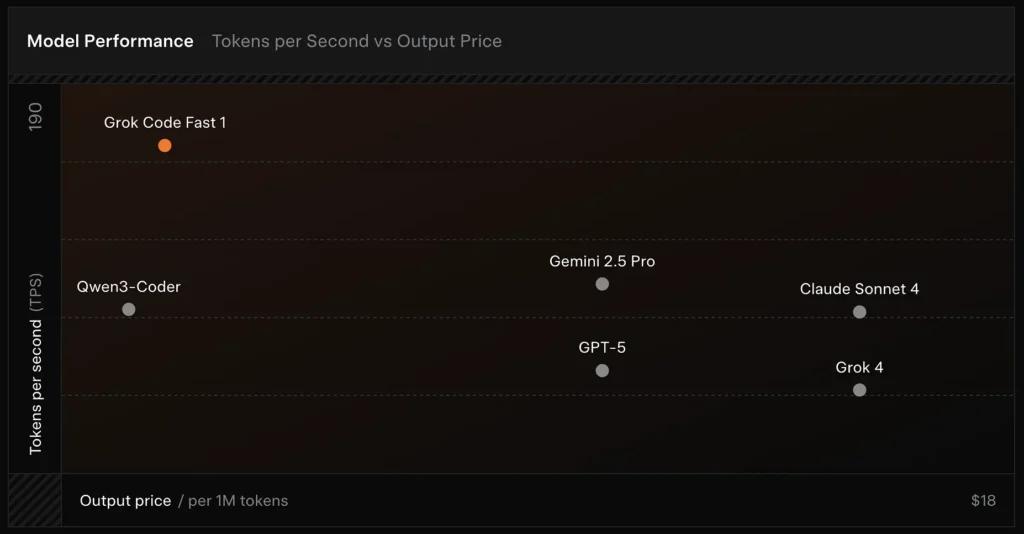
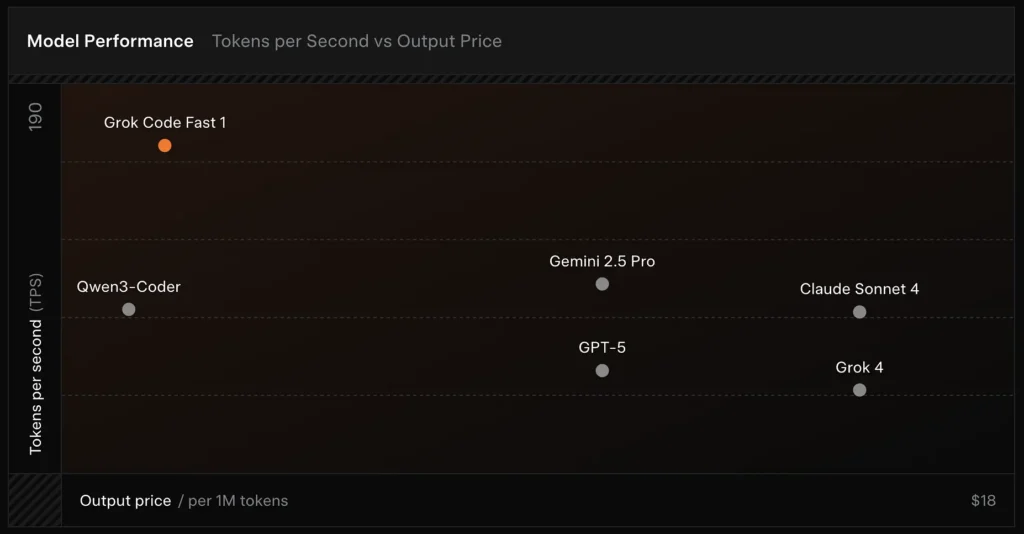
- Alta vazão/baixa latência: focado em saída de tokens muito rápida e conclusões ágeis para uso em IDE.
- Chamadas de função agentivas e ferramentas: suporta chamadas de função e orquestração de ferramentas externas (executar testes, linters, busca de arquivos) para viabilizar agentes de codificação de múltiplas etapas.
- Janela de contexto grande: projetado para lidar com grandes bases de código e contextos multiarquivo (fornecedores listam janelas de contexto de 256k em adaptadores de marketplace).
- Raciocínio/traços visíveis: as respostas podem incluir rastros de raciocínio passo a passo destinados a tornar as decisões do agente inspecionáveis e depuráveis.
Detalhes técnicos
Arquitetura e treinamento: a xAI afirma que o grok-code-fast-1 foi construído do zero com uma nova arquitetura e um corpus de pré-treinamento rico em conteúdo de programação; o modelo então recebeu curadoria pós-treinamento em conjuntos de dados de pull requests/código de alta qualidade e do mundo real. Esse pipeline de engenharia é voltado a tornar o modelo prático em fluxos de trabalho agentivos (IDE + uso de ferramentas).
Serviço e contexto: grok-code-fast-1 e os padrões típicos de uso pressupõem saídas em streaming, chamadas de função e injeção de contexto rica (envio/coleções de arquivos). Vários marketplaces em nuvem e adaptadores de plataforma já o listam com suporte a contexto grande ( contextos de 256k em alguns adaptadores).
Recursos de usabilidade: rastros de raciocínio visíveis (o modelo expõe seu planejamento/uso de ferramentas), orientação de engenharia de prompts e integrações de exemplo, além de integrações com parceiros de lançamento iniciais (por exemplo, GitHub Copilot, Cursor).
Desempenho em benchmarks (no que ele pontua)
SWE-Bench-Verified: a xAI relata uma pontuação de 70,8% em sua bancada interna no subconjunto SWE-Bench-Verified — um benchmark comumente usado para comparações de modelos de engenharia de software. Uma avaliação prática recente reportou uma classificação humana média ≈ 7,6 em um conjunto misto de tarefas de codificação — competitiva com alguns modelos de alto valor (por exemplo, Gemini 2.5 Pro), mas atrás de modelos multimodais/“melhores em raciocínio” maiores, como Claude Opus 4 e o próprio Grok 4 da xAI, em tarefas de raciocínio de alta dificuldade. Benchmarks também mostram variação por tarefa: excelente para correções de bugs comuns e geração concisa de código, mais fraco em alguns problemas de nicho ou específicos de bibliotecas (exemplo com Tailwind CSS).
Comparação :
- vs Grok 4: O Grok-code-fast-1 troca um pouco de correção absoluta e raciocínio mais profundo por custo muito menor e maior vazão; o Grok 4 continua sendo a opção de maior capacidade.
- vs Claude Opus / classe GPT: Esses modelos costumam liderar em tarefas complexas, criativas ou de raciocínio difícil; o Grok-code-fast-1 compete bem em tarefas rotineiras de alto volume em que latência e custo importam.
Limitações e riscos
Limitações práticas observadas até agora:
- Lacunas de domínio: quedas de desempenho em bibliotecas de nicho ou problemas formulados de maneira incomum (exemplos incluem casos extremos do Tailwind CSS).
- Trade-off de custo de tokens de raciocínio: como o modelo pode emitir tokens internos de raciocínio, um raciocínio altamente agentivo/verboso pode aumentar o comprimento da saída de inferência (e o custo).
- Precisão/casos extremos: embora forte em tarefas rotineiras, o Grok-code-fast-1 pode alucinar ou produzir código incorreto para algoritmos inéditos ou enunciados adversariais; pode ter desempenho inferior aos principais modelos focados em raciocínio em benchmarks algorítmicos exigentes.
Casos de uso típicos
- Assistência em IDE e prototipagem rápida: conclusões rápidas, escrita incremental de código e depuração interativa.
- Agentes automatizados / fluxos de trabalho de código: agentes que orquestram testes, executam comandos e editam arquivos (por exemplo, auxiliares de CI, bots revisores).
- Tarefas cotidianas de engenharia: geração de esqueletos de código, refatorações, sugestões de triagem de bugs e scaffolding de projetos multifile, em que baixa latência melhora materialmente o fluxo do desenvolvedor.
Como chamar a API grok-code-fast-1 a partir da CometAPI
grok-code-fast-1 Preços da API na CometAPI, 20% abaixo do preço oficial:
- Tokens de entrada: $0.16/ M tokens
- Tokens de saída: $2.0/ M tokens
Etapas necessárias
- Faça login em cometapi.com. Se você ainda não é nosso usuário, registre-se primeiro.
- Obtenha a chave de API de credenciais de acesso da interface. Clique em “Add Token” no token de API no centro pessoal, obtenha a chave do token: sk-xxxxx e envie.
Método de uso
- Selecione o endpoint “
grok-code-fast-1” para enviar a solicitação de API e defina o corpo da solicitação. O método e o corpo da solicitação são obtidos na documentação da API do nosso site. Nosso site também fornece teste Apifox para sua conveniência. - Substitua <YOUR_API_KEY> pela sua chave CometAPI real da sua conta.
- Insira sua pergunta ou solicitação no campo content — é a isso que o modelo responderá.
- . Processe a resposta da API para obter a resposta gerada.
A CometAPI fornece uma API REST totalmente compatível — para migração sem atrito. Detalhes principais na documentação da API:
- Base URL: https://api.cometapi.com/v1/chat/completions
- Model Names: “
grok-code-fast-1“ - Autenticação: token Bearer via cabeçalho
Authorization: Bearer YOUR_CometAPI_API_KEY - Content-Type:
application/json.
Integração da API e exemplos
Trecho em Python para uma chamada de ChatCompletion via CometAPI:
pythonimport openai
openai.api_key = "YOUR_CometAPI_API_KEY"
openai.api_base = "https://api.cometapi.com/v1/chat/completions"
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Summarize grok-code-fast-1's main features."}
]
response = openai.ChatCompletion.create(
model="grok-code-fast-1",
messages=messages,
temperature=0.7,
max_tokens=500
)
print(response.choices.message)
Veja também Grok 4