

DeepSeek lançou DeepSeekV3.2 e uma variante de alto poder computacional DeepSeek-V3.2-EspecialCom um novo mecanismo de atenção esparsa (DSA), comportamento aprimorado do agente/ferramenta e um modo de "pensamento" (cadeia de raciocínio) que revela o raciocínio interno. Ambos os modelos estão disponíveis por meio da API da DeepSeek (endpoints compatíveis com OpenAI) e os artefatos/relatórios técnicos dos modelos são publicados publicamente.
O que é DeepSeek V3.2?
O DeepSeek V3.2 é o sucessor de produção da família DeepSeek V3 — uma família de modelos generativos de contexto amplo, projetada especificamente para raciocínio-primeiro fluxos de trabalho e uso do agente. A versão 3.2 consolida melhorias experimentais anteriores (V3.2-Exp) em uma linha de modelos principal, exposta por meio do aplicativo DeepSeek, da interface web e da API. Ela oferece suporte tanto a saídas rápidas e conversacionais quanto a uma interface dedicada. pensando O modo de raciocínio em cadeia é adequado para tarefas de raciocínio com várias etapas, como matemática, depuração e planejamento.
Por que a versão 3.2 é importante (contexto rápido)
O DeepSeek V3.2 destaca-se por três razões práticas:
- Contexto longo: Suporta janelas de contexto de até 128 mil tokens, o que o torna adequado para documentos longos, contratos legais ou pesquisas com múltiplos documentos.
- Design orientado ao raciocínio: O modelo integra a linha de raciocínio ("pensamento") aos fluxos de trabalho e ao uso de ferramentas — uma mudança em direção a aplicativos autônomos que necessitam de etapas intermediárias de raciocínio.
- Custo e eficiência: A introdução do DSA (atenção esparsa) reduz o custo computacional para sequências longas, permitindo inferências muito mais econômicas para contextos extensos.
O que é o DeepSeek-V3.2-Speciale e como ele difere da versão base v3.2?
O que torna a variante “Speciale” especial?
DeepSeek V3.2-Speciale é um alto poder computacional, alto raciocínio Variante da família v3.2. Comparada com a variante balanceada v3.2, a Speciale é otimizada (e pós-treinada) especificamente para raciocínio em múltiplas etapas, matemática e tarefas de ação; ela utiliza aprendizado por reforço adicional a partir de feedback humano (RLHF) e uma cadeia de pensamento interna expandida durante o treinamento. Esse endpoint temporário e o acesso à API da Speciale foram anunciados como tendo prazo de validade (consulte a data de expiração do endpoint para o caminho da Speciale em 15 de dezembro de 2025).
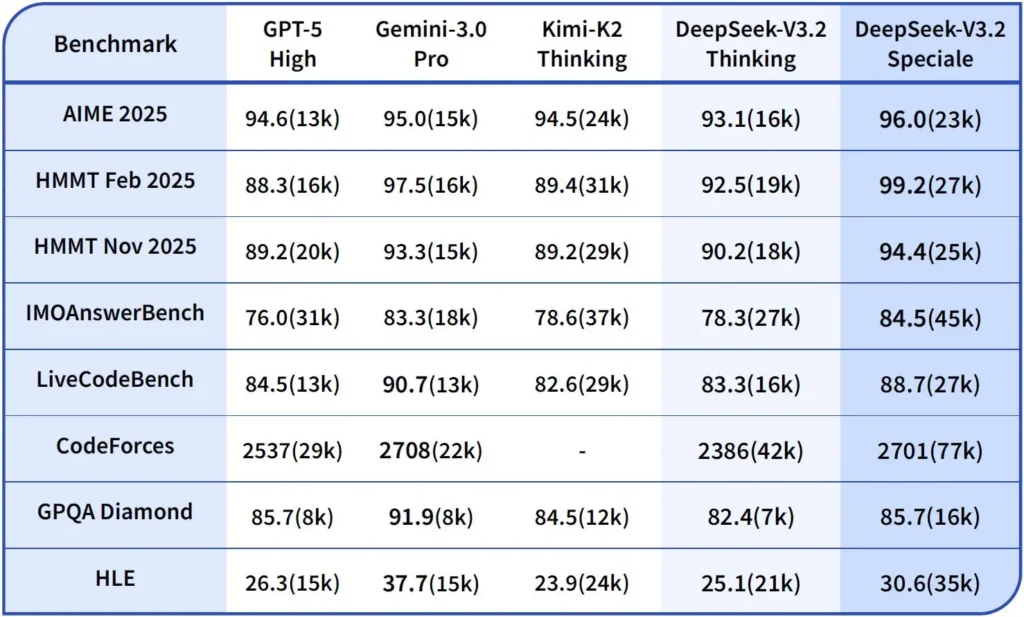
Desempenho e benchmarks
DeepSeek-V3.2-Speciale é a variante de alto poder computacional e otimizada para raciocínio do V3.2. A versão Speciale integra o modelo matemático anterior, DeepSeek-Math-V2, e se posiciona como o modelo a ser usado quando a carga de trabalho exige... Sequência de pensamento mais profunda possível, resolução de problemas em várias etapas, raciocínio competitivo (por exemplo, no estilo de olimpíada matemática) e orquestração de agentes complexos..
É capaz de demonstrar teoremas matemáticos e verificar raciocínio lógico por conta própria; obteve resultados notáveis em diversas competições de nível mundial:
- Medalha de Ouro da Olimpíada Internacional de Matemática (IMO)
- Medalha de Ouro da Olimpíada Chinesa de Matemática (CMO)
- ICPC (Concurso Internacional de Programação de Computadores) - 2º Lugar (Competição Humana)
- IOI (Olimpíada Internacional de Informática) - 10º lugar (Competição Humana)
O que é o Modo de Raciocínio no DeepSeek v3.2?
DeepSeek expõe um explícito modo de pensamento/raciocínio o que faz com que o modelo produza um Cadeia de Pensamento (CoT) como uma parte discreta da saída antes A resposta final. A API expõe esse CoT para que os aplicativos cliente possam inspecioná-lo, exibi-lo ou destilá-lo.
Mecânica — o que a API fornece
reasoning_contentcampoQuando o modo de pensamento está ativado, a estrutura de resposta inclui umreasoning_contentcampo (o CoT) no mesmo nível que o finalcontentIsso permite que os clientes acessem programaticamente as etapas internas.- Ferramentas são chamadas durante o pensamentoA versão 3.2 afirma suportar chamadas de ferramentas. dentro A trajetória do pensamento: o modelo pode intercalar etapas de raciocínio e invocações de ferramentas, o que melhora o desempenho em tarefas complexas.
Como a API DeepSeek v3.2 implementa o raciocínio
A versão 3.2 introduz um mecanismo de API de cadeia de raciocínio padronizado para manter a lógica de raciocínio consistente em conversas com múltiplas interações:
- Cada solicitação de raciocínio contém um
reasoning_contentcampo dentro do modelo; - Se o usuário quiser que o modelo continue o raciocínio, este campo deve ser passado de volta para a próxima etapa;
- Quando uma nova pergunta começa, a antiga
reasoning_contentdeve ser limpo para evitar contaminação lógica; - O modelo pode executar o loop “raciocínio → chamada de ferramenta → re-raciocínio” várias vezes no modo de raciocínio.
Como faço para acessar e usar a API do DeepSeek v3.2?
Curta: A CometAPI é um gateway no estilo OpenAI que expõe muitos modelos (incluindo famílias DeepSeek) através de https://api.cometapi.com/v1 assim você pode trocar de modelo alterando o model string em solicitações. Cadastre-se no CometAPI e obtenha sua chave de API primeiro.
Por que usar a API Comet em vez de usar o DeepSeek diretamente?
- A CometAPI centraliza a cobrança, os limites de taxa e a seleção de modelos (útil se você planeja trocar de provedor sem alterar o código).
- Endpoints DeepSeek diretos (por exemplo,
https://api.deepseek.com/v1Ainda existem endpoints que, às vezes, expõem recursos específicos do provedor; escolha a CometAPI pela conveniência ou o endpoint direto do fornecedor para controles nativos do provedor. Verifique quais recursos (por exemplo, Speciale, endpoints experimentais) estão disponíveis por meio da CometAPI antes de utilizá-los.
Etapa A — Crie uma conta na CometAPI e obtenha uma chave de API.
- Acesse o CometAPI (cadastro/console) e gere uma chave de API (o painel geralmente mostra...).
sk-...Mantenha em segredo. CometAPI
Etapa B — Confirme o nome exato do modelo disponível.
- Consulte a lista de modelos para confirmar a string exata do modelo que a CometAPI expõe (os nomes dos modelos podem incluir sufixos variantes). Use o endpoint de modelos antes de codificar nomes diretamente no código:
curl -s -H "Authorization: Bearer $COMET_KEY" \
https://api.cometapi.com/v1/models | jq .
Procure a entrada DeepSeek (por exemplo, deepseek-v3.2 or deepseek-v3.2-exp) e anote o ID exato. A CometAPI expõe um /v1/models listagem.
Etapa C — Faça uma chamada de bate-papo básica (curl)
Substituir <COMET_KEY> e deepseek-v3.2 Com o ID do modelo que você confirmou:
curl https://api.cometapi.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <COMET_KEY>" \
-d '{
"model": "deepseek-v3.2",
"messages": [
{"role":"system","content":"You are a helpful assistant."},
{"role":"user","content":"Summarize DeepSeek v3.2 in two sentences."}
],
"max_tokens":300
}'
Este é o mesmo padrão de chamada no estilo OpenAI — a CometAPI encaminha para o provedor selecionado.
Compatibilidade e Precauções
- Permite ativar o Modo de Reflexão no ambiente de código Claude;
- Na linha de comando (CLI), basta inserir o nome do modelo deepseek-reasoner;
- No entanto, pode não ser compatível com ferramentas não padronizadas, como Cline e RooCode, por enquanto;
- Recomenda-se usar o Modo Normal (sem modo de reflexão) para tarefas comuns e o Modo de Reflexão (com modo de reflexão) para raciocínio lógico complexo.
Padrões práticos de adoção: alguns exemplos de arquiteturas
1 — Agente auxiliar para fluxos de trabalho de desenvolvedores
- Modo: O modo Speciale (modo de raciocínio) é ativado para geração de código complexo e criação de testes; o modo de bate-papo rápido serve como assistente integrado.
- Segurança: Utilize verificações de pipeline de CI e execução de testes em ambiente isolado (sandbox) para o código gerado.
- hospedagem: API ou hospedagem própria em vLLM + cluster multi-GPU para contextos amplos.
2 — Análise de documentos para equipes jurídicas/financeiras
- Modo: A versão 3.2 conta com otimizações DSA de contexto longo para processar contratos extensos e gerar resumos estruturados e listas de ações.
- Segurança: Aprovação judicial humana para decisões subsequentes; redação de informações pessoais identificáveis antes do envio para os endpoints hospedados.
3 — Orquestrador autônomo de pipeline de dados
- Modo: Modo de pensamento para planejar tarefas ETL de várias etapas, chamar ferramentas para consultar bancos de dados e executar testes de validação.
- Segurança: Implemente a confirmação de ações e verificações antes de qualquer operação irreversível (por exemplo, gravação destrutiva no banco de dados).
Cada um dos padrões acima é viável com os modelos da família V3.2 atualmente, mas você deve combinar o modelo com ferramentas de verificação e governança conservadora.
Como otimizar custo e desempenho com a versão 3.2?
Use os dois modos deliberadamente.
- Modo rápido para microinterações: Use o modo de ferramenta automática para consultas rápidas, conversões de formato ou chamadas diretas à API, onde a latência é importante.
- Modo de raciocínio para planejamento e verificação: Direcione tarefas complexas, agentes com múltiplas ações ou decisões críticas para a segurança para o modo de raciocínio. Capture as etapas intermediárias e execute uma verificação (automatizada ou humana) antes de executar ações críticas.
Qual variante do modelo devo escolher?
- deepseek-v3.2 — modelo de produção balanceado para tarefas gerais de agentes.
- deepseek-v3.2-Speciale — variante especializada para raciocínio complexo; pode ser inicialmente apenas via API e usada quando você precisa do melhor desempenho possível em raciocínio/benchmark (e aceita um custo potencialmente maior).
Controle de custos prático e dicas
- Engenharia de prompts: mantenha as instruções do sistema concisas e evite enviar contexto redundante. Instruções explícitas do sistema: use prompts do sistema que declarem a intenção do modo: por exemplo, "Você está no modo PENSAMENTO — liste seu plano antes de chamar as ferramentas". Para o modo de ferramenta, adicione restrições como "Ao interagir com a API da calculadora, gere apenas JSON com os seguintes campos".
- Segmentação e aumento da recuperação de dados: utilize um mecanismo de recuperação externo para enviar apenas os segmentos mais relevantes para cada pergunta do usuário.
- Temperatura e amostragem: Diminua a temperatura durante as interações com as ferramentas para aumentar o determinismo; aumente-a em tarefas exploratórias ou de ideação.
Estabelecer parâmetros e medir.
- Considere as saídas como não confiáveis até que sejam verificadas: mesmo as saídas de raciocínio podem estar incorretas. Adicione verificações determinísticas (testes unitários, verificações de tipo) antes de tomar ações irreversíveis.
- Realize testes A/B em uma carga de trabalho de amostra (latência, uso de tokens, correção) antes de adotar uma variante. A versão 3.2 apresentou ganhos significativos em benchmarks de raciocínio, mas o comportamento real do aplicativo depende do design dos prompts e da distribuição de entrada.
Perguntas Frequentes
P: Qual é a maneira recomendada de obter o CoT a partir do modelo?
A: Use o deepseek-reasoner modelo ou conjunto thinking/thinking.type = enabled Em sua solicitação. A resposta inclui reasoning_content (CoT) e o final content.
P: O modelo pode acessar ferramentas externas enquanto está no modo de processamento?
A: Sim — A versão 3.2 introduziu a capacidade de usar ferramentas tanto em modos de pensamento quanto em modos não-pensamento; o modelo pode emitir chamadas de ferramentas estruturadas durante o raciocínio interno. Use strict Use o modo de limpeza e os esquemas JSON para evitar chamadas malformadas.
P: Usar o modo de pensamento aumenta o custo?
A: Sim — o modo de pensamento gera tokens CoT intermediários, o que aumenta o uso de tokens e, portanto, o custo. Projete seu sistema para habilitar o modo de pensamento somente quando necessário.
P: Qual endpoint e URL base devo usar?
A: A CometAPI fornece endpoints compatíveis com OpenAI. A URL base padrão é https://api.cometapi.com e o ponto de acesso principal do chat é /v1/chat/completions (ou /chat/completions dependendo da URL base que você escolher).
P: É necessário algum tipo de ferramenta especial para usar a chamada de ferramentas?
A: Não — a API suporta declarações de funções estruturadas em JSON. Você precisa fornecer o tools O parâmetro, os esquemas da ferramenta e o gerenciamento do ciclo de vida da função JSON em sua aplicação: receber o JSON da chamada de função, executar a função e, em seguida, retornar os resultados para o modelo para continuação ou encerramento. O modo de reflexão adiciona um requisito para retornar o parâmetro. reasoning_content juntamente com os resultados da ferramenta.
Conclusão
DeepSeek V3.2 e DeepSeek-V3.2-Speciale representam um claro avanço em direção a aberto, centrado no raciocínio Modelos de lógica de aprendizagem (LLMs) que explicitam a cadeia de raciocínio e suportam fluxos de trabalho de ferramentas com agentes. Eles oferecem novas primitivas poderosas (DSA, modo de pensamento, treinamento de uso de ferramentas) que podem simplificar a construção de agentes confiáveis — desde que você leve em conta os custos dos tokens, o gerenciamento cuidadoso do estado e os controles operacionais.
Os desenvolvedores podem acessar API Deepseek v3.2 etc. através da CometAPI, a versão mais recente do modelo está sempre atualizado com o site oficial. Para começar, explore as capacidades do modelo no Playground e consulte o Guia de API para obter instruções detalhadas. Antes de acessar, certifique-se de ter feito login no CometAPI e obtido a chave da API. CometAPI oferecem um preço muito mais baixo que o preço oficial para ajudar você a se integrar.
Pronto para ir?→ Teste grátis do Deepseek v3.2 !
Se você quiser saber mais dicas, guias e novidades sobre IA, siga-nos em VK, X e Discord!