

O Uni-1 da Luma AI é mais do que um novo modelo de texto para imagem. Na própria formulação da Luma, trata-se de um “modelo de raciocínio multimodal que pode gerar pixels”, construído sobre “Inteligência Unificada” para entender a intenção, responder a direções e “pensar com você”. O relatório técnico da empresa diz que o modelo usa um transformer autoregressivo somente decodificador, no qual texto e imagens são representados em uma única sequência intercalada, e que o Uni-1 pode realizar raciocínio interno estruturado antes e durante a síntese de imagens. Essa combinação é o que torna o Uni-1 um dos lançamentos de modelos de imagem mais interessantes de 2026.
O que é o modelo de imagem UNI-1?
O Uni-1 é o novo modelo de imagem da Luma AI para tarefas que exigem entendimento e geração no mesmo sistema. A Luma o apresenta como um modelo de raciocínio multimodal, em vez de um mecanismo clássico de imagem apenas por difusão, o que importa porque o modelo pretende fazer mais do que produzir resultados visualmente agradáveis: ele foi projetado para interpretar instruções, preservar restrições de referência e raciocinar sobre a lógica da cena como parte da geração. O relatório técnico da empresa descreve o Uni-1 como seu primeiro modelo unificado de entendimento e geração no caminho para uma inteligência multimodal geral.
Por que o Uni-1 é diferente
O pipeline antigo tem um teto: a geração de imagens sem entendimento só pode ir até certo ponto. O Uni-1 é apresentado como um passo em direção à “inteligência unificada”, na qual linguagem, percepção, imaginação, planejamento e execução são tratados dentro de uma única arquitetura. Isso é mais do que branding. O Uni-1 consegue avançar da semelhança visual para a composição intencional, plausibilidade e lógica de cena.
A história maior é que os modelos de imagem estão se tornando mais agentes, com maior capacidade de agir. A pilha de imagem mais recente do Google agora enfatiza edição conversacional, fundamentação em busca, fusão de múltiplas imagens e consistência de personagem; a família GPT Image da OpenAI enfatiza multimodalidade nativa e seguimento de instruções. O Uni-1 se soma a essa mudança, mas aposta ainda mais na ideia de que o modelo deve “pensar” sobre a imagem antes de desenhá-la. Isso torna o Uni-1 especialmente interessante para fluxos de trabalho em que precisão e repetibilidade importam tanto quanto o apelo visual.
Como o Uni-1 realmente funciona?
🔬 Processo de Tokenização
- Texto → sequência de tokens
- Imagem → patches tokenizados
- Combinados em uma única sequência intercalada
🔁 Processo de Geração
- Prompt de entrada + referências
- O modelo realiza raciocínio interno
- Planeja a composição
- Gera tokens sequencialmente
Matematicamente: P(x1,...,xn)=∏P(xi∣x1,...,xi−1)P(x_1,...,x_n) = \prod P(x_i | x_1,...,x_{i-1})P(x1,...,xn)=∏P(xi∣x1,...,xi−1)
🧠 Camada de Raciocínio Interno
Uni-1:
- Decompõe instruções
- Resolve restrições
- Planeja o layout antes da renderização
👉 Isso é um grande salto em relação aos modelos de difusão.
Geração autoregressiva somente decodificador
O detalhe técnico mais importante é que o Uni-1 é autoregressivo, e não baseado em difusão. O relatório técnico da Luma diz que é um transformer autoregressivo somente decodificador e que texto e imagens são codificados em uma única sequência intercalada. Em termos simples, o modelo não apenas começa a partir de ruído e gradualmente “desfaz o ruído” rumo a uma imagem. Em vez disso, ele gera tokens passo a passo, permitindo raciocinar sobre o prompt, resolver restrições e planejar a composição antes e durante a renderização.
🔬 Processo de Tokenização
- Texto → sequência de tokens
- Imagem → patches tokenizados
- Combinados em uma única sequência intercalada
Difusão vs Autoregressivo
| Recurso | Modelos de difusão | Uni-1 (Autoregressivo) |
|---|---|---|
| Geração | Ruído → Imagem | Token a token |
| Raciocínio | Limitado | Forte |
| Edição | Fraca | Multiturno |
| Renderização de texto | Fraca | Forte |
| Controle | Baixo | Alto |
Arquitetura principal
O Uni-1 é:
- Transformer autoregressivo somente decodificador
- Espaço de tokens compartilhado para texto + imagens
Essa arquitetura importa porque dá ao modelo a chance de manter a coerência quando o prompt é complicado. A Luma diz que o Uni-1 pode decompor instruções, resolver restrições conflitantes e planejar a imagem antes que a renderização comece. Isso é especialmente útil para tarefas como preenchimento estruturado de cenas, posicionamento de múltiplos sujeitos, refinamento multiturno e edições que exigem que a saída permaneça fiel a uma imagem de referência enquanto ainda obedece às novas instruções.
O que o modelo parece projetado para fazer melhor
Aprender a gerar imagens melhora o entendimento. A Luma afirma que o treinamento de geração de imagens melhora materialmente o entendimento visual de alto nível, especialmente sobre regiões, objetos e layouts. É por isso que o Uni-1 não é visto como um gerador unidirecional, mas como um sistema unificado cujo processo de geração e compreensão se reforçam mutuamente. Do ponto de vista de inferência, isso significa que o Uni-1 tenta reduzir a lacuna entre “ver” e “fazer”. Isso é um grande salto em relação aos modelos de difusão.
Processo de Geração:
- Prompt de entrada + referências
- O modelo realiza raciocínio interno
- Planeja a composição
- Gera tokens sequencialmente
Matematicamente: P(x1,...,xn)=∏P(xi∣x1,...,xi−1)P(x_1,...,x_n) = \prod P(x_i | x_1,...,x_{i-1})P(x1,...,xn)=∏P(xi∣x1,...,xi−1)
Quais recursos e vantagens centrais o Uni-1 oferece?
Forte seguimento de instruções e direcionabilidade
O ponto mais forte do Uni-1 é o controle. O modelo foi construído para edição de precisão, uso estruturado de referências e fluxos de trabalho repetíveis. Para criadores, isso significa menos aposta no prompt e mais resultados reproduzíveis.
Uma vantagem prática do Uni-1 é ter sido projetado para iteração controlada. Seeds permitem reproduzir resultados, enquanto papéis de referência ajudam o modelo a saber se uma imagem deve orientar a identidade do personagem, o clima, a paleta ou a composição. Isso torna o Uni-1 mais fácil de dirigir do que um modelo puramente orientado a prompt, especialmente para equipes que produzem anúncios, storyboards, mockups de produto ou ativos de marca em que a consistência é importante.
Geração baseada em referências que preserva a identidade
Uma grande vantagem é o tratamento de referências. A Luma afirma explicitamente que o Uni-1 usa controles fundamentados em fonte e pode preservar identidade, composição e restrições visuais-chave a partir de uma ou mais referências. Isso o torna atraente para fluxos de trabalho comerciais, como personagens de marca, mockups de produto, ativos de campanha e qualquer projeto em que um sujeito deva permanecer reconhecível entre variantes. Este é um dos modos mais claros pelos quais o Uni-1 difere de sistemas de imagem mais puramente estéticos.
Fluência cultural e amplitude de estilos
A Luma também enfatiza geração consciente de cultura. Sua seção “Cultured” aponta para memes, mangá, visuais cinematográficos, fotos casuais, esportes e imagens de animais, mostrando que o modelo foi pensado para operar entre linguagens visuais, e não em um estilo genérico. Isso importa porque um bom modelo de imagem moderno não precisa apenas renderizar uma cena realista; ele também precisa entender as convenções visuais da cultura da internet, do design editorial, da ilustração estilizada e do conteúdo social.
Pensamento multimodal como escolha de design
O diferencial real não é apenas que o Uni-1 gera imagens, mas que a Luma encara a geração de imagens como uma tarefa de raciocínio. O Uni-1 pode realizar raciocínio interno estruturado e que aprender a gerar imagens melhora o entendimento visual minucioso sobre regiões, objetos e layouts. Isso sugere um modelo feito para entender a cena antes de renderizá-la, em vez de simplesmente aproximar o prompt estatisticamente.
Benchmarks de Desempenho
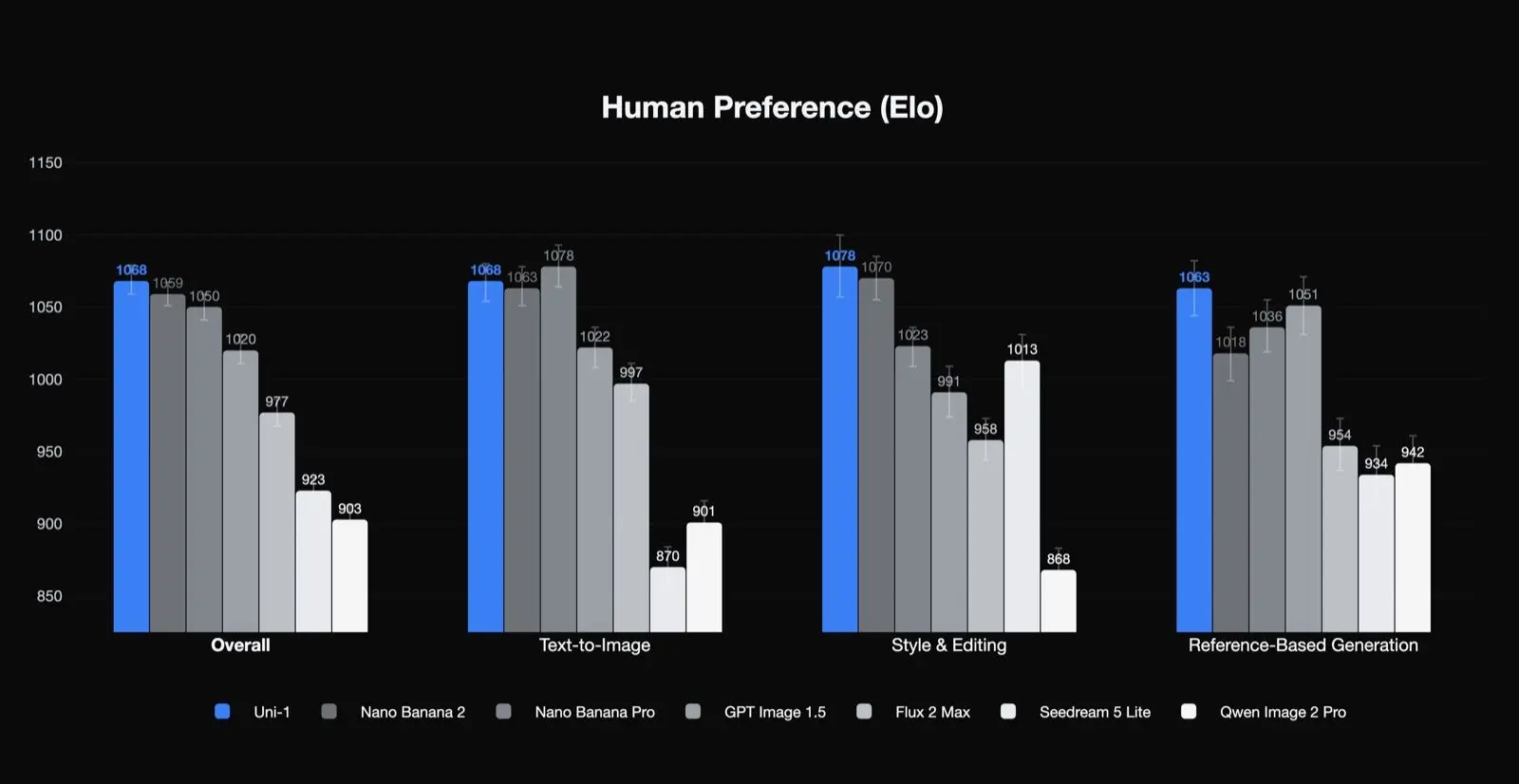
Resultados de preferência humana da própria Luma
O Uni-1 fica em primeiro lugar no Elo de preferência humana para qualidade geral, estilo e edição, e geração baseada em referência, e em segundo em texto para imagem. Esse é um resultado significativo porque sugere que o modelo é especialmente forte nos tipos de tarefas que importam para equipes de produção: edição, consistência e transformação guiada. Também sugere que seus melhores casos de uso podem não ser apenas geração texto-para-imagem de tiro único.
RISEBench: edição visual orientada por raciocínio
O benchmark que mais chama atenção é o RISEBench, que avalia edição visual orientada por raciocínio ao longo de raciocínio temporal, causal, espacial e lógico. Relatos de terceiros sobre o lançamento da Luma dizem que o Uni-1 marca 0,51 no geral no RISEBench, à frente do Nano Banana 2 do Google com 0,50, Nano Banana Pro com 0,49 e GPT Image 1.5 da OpenAI com 0,46. Em raciocínio espacial, o Uni-1 é reportado com 0,58 versus 0,47 do Nano Banana 2. Em raciocínio lógico, o Uni-1 é reportado com 0,32, mais do que o dobro dos 0,15 do GPT Image 1.5. As margens não são enormes no geral, mas são grandes nas categorias de raciocínio mais difíceis.

ODinW-13 e a afirmação de que “geração melhora o entendimento”
O Uni-1 também apresenta desempenho forte no ODinW-13, um benchmark de detecção densa de vocabulário aberto. Relatos dos dados técnicos da Luma dizem que o modelo completo marca 46,2 mAP, quase igualando o Gemini 3 Pro do Google com 46,3. Os mesmos relatos dizem que uma variante apenas de entendimento marca 43,9 mAP, o que implica que o treinamento de geração melhora o entendimento em 2,3 pontos. Esse é um achado notável porque apoia a tese central da Luma: geração de imagens e entendimento de imagens podem ser objetivos mutuamente reforçadores, e não concorrentes.
Preço da API do Uni-1
| Preço de entrada (texto) | $0.50 |
|---|---|
| Preço de entrada (imagens) | $1.20 |
| Preço de saída (texto e pensamento) | $3.00 |
| Preço de saída (imagens) | $45.45 |
No lado do consumidor, a página de preços da Luma lista Plus por $30/mês, Pro por $90/mês e Ultra por $300/mês, com créditos de teste gratuitos incluídos em todos os planos. Isso significa que há essencialmente duas camadas de preços a considerar: a assinatura do consumidor para a plataforma e o preço em nível de modelo da API para uso em produção.
Por enquanto, a API do Uni-1 na CometAPI estará disponível em breve, com um desconto prometido no lançamento. Atualmente, a CometAPI também oferece excelentes modelos de imagem brutos, como Midjourney e Nano Banana 2.
Uni-1 vs GPT Image 1.5 vs Nano Banana 2
Uni-1 versus Nano Banana 2 do Google
O Nano Banana 2 parece mais forte na amplitude do tratamento de referências e na integração ao ecossistema. O Google enfatiza fundamentação em busca de imagens, iteração conversacional e fluxos de trabalho com muitas referências, com até 14 referências. O Uni-1, por sua vez, é enquadrado mais explicitamente em raciocínio, plausibilidade de cena e edição de precisão em uma arquitetura de modelo unificada. Em termos práticos, o Google parece otimizado para velocidade, escala de produção mainstream e ancoragem nativa do Google; a Luma parece otimizada para raciocínio visual estruturado e edição de imagem direcionável.
Nas comparações públicas em torno do Uni-1, o trade-off é claro: o Nano Banana 2 parece permanecer muito forte para qualidade e velocidade em puro texto-para-imagem, enquanto o Uni-1 avança mais em edições com raciocínio, controle por referência e fidelidade às instruções.
Uni-1 versus GPT Image da OpenAI
Em relatórios de benchmark, o Uni-1 supera levemente o GPT Image 1.5 no geral no RISEBench e de forma mais decisiva em raciocínio lógico. Em comparação com a família GPT Image da OpenAI, o Uni-1 é posicionado de forma mais estreita e agressiva em torno de raciocínio visual e edição controlada. A documentação da OpenAI enfatiza conhecimento de mundo, entendimento multimodal e consciência contextual; a da Luma enfatiza raciocínio interno estruturado, controle fundamentado em referência e habilidade de edição visual avaliada por benchmarks. Portanto, embora ambos sejam multimodais, o Uni-1 é o mais claramente “modelo de raciocínio especialista em imagens”, enquanto o GPT Image soa mais como um sistema multimodal geral que também gera imagens extremamente bem.
Comparação de preços entre os três
Em preços, a comparação depende do tamanho da saída e do nível de produto, então não é um paralelo perfeito. O equivalente a 2048px publicado do Uni-1 custa cerca de $0,0909 por imagem. A página de preços do modelo de imagem mais recente do Google lista $0,134 por imagem 1K/2K e $0,24 por imagem 4K para o seu último preview de imagem Gemini, enquanto a página de preços do GPT Image da OpenAI lista preços por imagem de $0,011 em baixa qualidade para 1024x1024, $0,042 em qualidade média e $0,167 em alta qualidade, com saídas maiores de alta qualidade a $0,25. Em outras palavras, a OpenAI pode ser muito mais barata na faixa de entrada, o Google é agressivo no extremo de velocidade e escala, e o Uni-1 fica no meio, com um perfil de preço-desempenho forte voltado para 2K.
Diferenças filosóficas
| Modelo | Abordagem |
|---|---|
| Uni-1 | Inteligência multimodal unificada |
| GPT Image | LLM + geração de imagens |
| Nano Banana 2 | Difusão otimizada para produção |
Tabela de comparação detalhada
| Recurso | Uni-1 | GPT Image 1.5 | Nano Banana 2 |
|---|---|---|---|
| Arquitetura | Autoregressivo | Híbrido | Difusão |
| Unificação multimodal | ✅ Nativa | Parcial | ❌ |
| Capacidade de raciocínio | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ |
| Qualidade de imagem | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| Renderização de texto | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐ |
| Fluxos de edição | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ |
| Velocidade | Média | Rápida | Rápida |
| Controle | Alto | Médio | Médio |
CometAPI oferece imagens brutas interativas para GPT Image 1.5, Nano Banana 2, e o futuro Uni-1, além de programação via API. Preços com desconto e opções de pagamento conforme o uso tornam a plataforma uma escolha preferida para desenvolvedores.
Para que o Uni-1 é melhor
O Uni-1 parece especialmente forte para casos em que você precisa de repetibilidade, consistência de personagens ou controle por múltiplas referências. Isso inclui campanhas de marca, mockups de produto, conceitos editoriais, storyboards, variantes de localização e edições de imagem em que a composição deve permanecer intacta, mas o estilo ou o ambiente podem mudar. Os próprios exemplos da Luma reforçam muito esses casos de uso, e a divisão do modelo entre “Create vs Modify” é basicamente uma resposta direta às dores comuns de produção.
Se o seu trabalho é principalmente “fazer algo bonito a partir de um único prompt”, o diferencial pode parecer menos dramático. Mas se o seu fluxo é “faça cinco versões relacionadas, mantenha o mesmo personagem, preserve o enquadramento, mude a iluminação e torne isso reproduzível na semana que vem”, o design do Uni-1 começa a fazer muito sentido. Essa é uma inferência, mas decorre naturalmente dos recursos de controle que a Luma enfatiza.
Melhores práticas para obter resultados melhores com o Uni-1
Comece usando o modo correto. A orientação da Luma é simples: Create quando você quiser uma nova cena, Modify quando quiser preservar uma existente. Misturar essas intenções deixa as saídas mais instáveis.
Use rótulos de referência como um profissional. A Luma recomenda frases como “Use IMAGE1 como referência de ESTILO” ou “Use IMAGE2 como ILUMINAÇÃO”. O modelo trabalha melhor quando cada referência tem uma função, em vez de “inspiração” vaga.
Bloqueie a seed depois que encontrar algo bom. A Luma recomenda explicitamente explorar sem seed primeiro e, em seguida, salvar a seed assim que você tiver um resultado forte. A partir daí, mude uma variável por vez. Essa é a maneira mais fácil de transformar geração em um sistema de produção controlado.
Seja específico e concreto. A Luma alerta contra palavras vagas como “bonito” ou “incrível” e, em vez disso, incentiva estéticas nomeadas, como “cartaz de filme giallo italiano dos anos 1970” ou dicas exatas de estilo de câmera. Na prática, prompts específicos geralmente superam prompts poéticos, porque o modelo pode se ancorar em estrutura real.
Use a cadeia Create → Modify. A Luma afirma explicitamente que esse é um dos fluxos de trabalho mais poderosos: explorar em Create e depois refinar em Modify. Esse é o ponto ideal para trabalho sério de produção, porque reduz retrabalho e preserva as partes boas de uma composição enquanto aperta os detalhes.
Veredito final
O Uni-1 é a declaração mais clara da Luma de que a geração de imagens está mudando de “prompt entra, imagem sai” para criação visual guiada por raciocínio. Seus pontos fortes públicos são controle, tratamento de referências, reprodutibilidade e uma arquitetura de modelo que mantém linguagem e pixels no mesmo sistema.
Para criadores e equipes que se importam com saídas visuais de alto impacto, personagens consistentes, edições precisas e clareza de preços em alta resolução, o Uni-1 é um modelo para ficar de olho. Se o lançamento da API ocorrer sem percalços, ele pode se tornar uma das alternativas mais interessantes ao Nano Banana 2 do Google e ao GPT Image 1.5 da OpenAI em 2026.
Planejando começar a criar imagens brutas? A CometAPI, uma plataforma agregadora de APIs de modelos multimodais, dá as boas-vindas!