

Em 17 de junho, o unicórnio de IA de Xangai, MiniMax, tornou oficialmente o código-fonte aberto MiniMax‑M1, o primeiro modelo de inferência de atenção híbrida em larga escala e peso aberto do mundo. Ao combinar uma arquitetura de Mistura de Especialistas (MoE) com o novo mecanismo Lightning Attention, o MiniMax-M1 proporciona ganhos significativos em velocidade de inferência, processamento de contextos ultralongos e desempenho em tarefas complexas.
Antecedentes e Evolução
Com base na fundação de MiniMax-Texto-01, que introduziu atenção relâmpago em uma estrutura de Mistura de Especialistas (MoE) para atingir contextos de 1 milhão de tokens durante o treinamento e até 4 milhões de tokens na inferência, o MiniMax-M1 representa a próxima geração da série MiniMax-01. O modelo anterior, MiniMax-Text-01, continha 456 bilhões de parâmetros no total, com 45.9 bilhões ativados por token, demonstrando desempenho comparável aos LLMs de ponta, ao mesmo tempo em que expandia significativamente as capacidades de contexto.
Principais recursos do MiniMax‑M1
- MoE híbrido + atenção relâmpago: O MiniMax‑M1 combina um design esparso de Mistura de Especialistas — 456 bilhões de parâmetros no total, mas apenas 45.9 bilhões ativados por token — com o Lightning Attention, uma atenção de complexidade linear otimizada para sequências muito longas.
- Contexto Ultra Longo: Suporta até 1 milhões tokens de entrada — cerca de oito vezes o limite de 128 K do DeepSeek‑R1 — permitindo a compreensão profunda de documentos enormes.
- Eficiência Superior:Ao gerar 100 K tokens, o Lightning Attention do MiniMax‑M1 requer apenas ~25–30% da computação usada pelo DeepSeek‑R1.
Variantes do modelo
- MiniMax‑M1‑40K: 1 contexto de token M, orçamento de inferência de token 40 K
- MiniMax‑M1‑80K: 1 contexto de token M, orçamento de inferência de token 80 K
Em cenários de uso de ferramentas de bancada TAU, a variante 40K superou todos os modelos de peso aberto, incluindo o Gemini 2.5 Pro, demonstrando suas capacidades de agente.
Custo e configuração do treinamento
O MiniMax-M1 foi treinado de ponta a ponta usando aprendizado por reforço (RL) em larga escala em um conjunto diversificado de tarefas — desde raciocínio matemático avançado até ambientes de engenharia de software baseados em sandbox. Um novo algoritmo, CISPO (Amostragem de Importância Recortada para Otimização de Políticas) aprimora ainda mais a eficiência do treinamento, reduzindo os pesos da amostragem de importância em vez de atualizações em nível de token. Essa abordagem, combinada com a atenção relâmpago do modelo, permitiu a conclusão completa do treinamento RL em 512 GPUs H800 em apenas três semanas, com um custo total de aluguel de US$ 534,700.
Disponibilidade e preço
O MiniMax-M1 é lançado sob a Apache 2.0 licença de código aberto e pode ser acessado imediatamente por meio de:
- Repositório GitHub, incluindo pesos de modelo, scripts de treinamento e benchmarks de avaliação.
- Nuvem de Silício hospedagem, oferecendo duas variantes — 40 K‑token (“M1‑40K”) e 80 K‑token (“M1‑80K”) — com planos para habilitar o funil completo de 1 M token.
- O preço atualmente definido é ¥ 4 por milhão tokens para entrada e ¥ 16 por milhão tokens para saída, com descontos por volume disponíveis para clientes empresariais.
Desenvolvedores e organizações podem integrar o MiniMax-M1 por meio de APIs padrão, fazer ajustes finos em dados específicos do domínio ou implantar no local para cargas de trabalho confidenciais.
Desempenho em nível de tarefa
| Categoria de tarefa | Destaques | Desempenho Relativo |
|---|---|---|
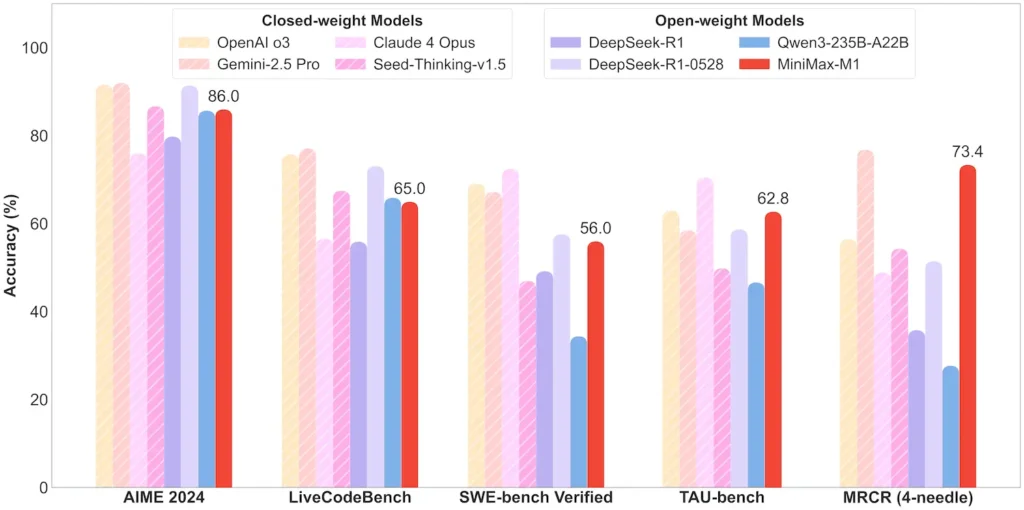
| Matemática e Lógica | AIME 2024: 86.0% | > Qwen 3, DeepSeek‑R1; código-fonte quase fechado |
| Compreensão de Contexto Longo | Governante (4 fichas K–1 M): Nível superior estável | Supera o GPT‑4 em comprimentos de tokens de 128 K |
| Engenharia de Software | SWE-bench (bugs reais do GitHub): 56% | Melhor entre os modelos abertos; 2º depois dos principais modelos fechados |
| Uso de agentes e ferramentas | TAU‑bench (simulação de API) | 62–63.5% vs. Gêmeos 2.5, Claude 4 |
| Diálogo e Assistente | MultiDesafio: 44.7% | Combina com Claude 4, DeepSeek‑R1 |
| Controle de qualidade de fatos | SimpleQA: 18.5% | Área para melhorias futuras |
Nota: percentuais e referências da divulgação oficial da MiniMax e de relatórios de notícias independentes
Inovações Técnicas
- Pilha de Atenção Híbrida: Atenção relâmpago camadas (custo linear) intercaladas com atenção Softmax periódica (quadrática, mas mais expressiva) para equilibrar eficiência e poder de modelagem.
- Roteamento MoE esparso: 32 módulos especializados; cada token ativa apenas ~10% do total de parâmetros, reduzindo o custo de inferência e preservando a capacidade.
- Aprendizado por Reforço CISPO: Um novo algoritmo de “Otimização de Política de Peso IS Recortado” que retém tokens raros, mas cruciais, no sinal de aprendizagem, acelerando a estabilidade e a velocidade do RL.
A liberação de peso aberto do MiniMax-M1 desbloqueia inferência de contexto ultralongo e alta eficiência para todos, preenchendo a lacuna entre a pesquisa e a IA implantável em larga escala.
Começando a jornada
A CometAPI fornece uma interface REST unificada que agrega centenas de modelos de IA — incluindo a família ChatGPT — em um endpoint consistente, com gerenciamento de chaves de API, cotas de uso e painéis de faturamento integrados. Em vez de lidar com várias URLs e credenciais de fornecedores.
Para começar, explore as capacidades dos modelos no Playground e consulte o Guia de API para obter instruções detalhadas. Antes de acessar, certifique-se de ter feito login no CometAPI e obtido a chave da API.
A mais recente integração da API MiniMax‑M1 aparecerá em breve no CometAPI, portanto, fique atento! Enquanto finalizamos o upload do modelo MiniMax‑M1, explore nossos outros modelos no Página de modelos ou experimentá-los no IA Playground. O modelo mais recente da MiniMax no CometAPI é Minimax ABAB7-Prévia API e API de vídeo MiniMax-01 ,consulte:
