

Em 17 de junho de 2025, a MiniMax, líder em IA de Xangai (também conhecida como Xiyu Technology), lançou oficialmente o MiniMax-M1 (doravante "M1") — o primeiro modelo de raciocínio de atenção híbrida, aberto e em larga escala, do mundo. Combinando uma arquitetura de Mistura de Especialistas (MoE) com um inovador mecanismo Lightning Attention, o M1 alcança desempenho líder do setor em tarefas voltadas à produtividade, rivalizando com os principais sistemas de código fechado, mantendo uma relação custo-benefício incomparável. Neste artigo aprofundado, exploramos o que é o M1, como funciona, suas características definidoras e orientações práticas sobre como acessar e usar o modelo.
O que é MiniMax-M1?
O MiniMax-M1 representa o ápice da pesquisa da MiniMaxAI sobre mecanismos de atenção escaláveis e eficientes. Com base na base do MiniMax-Text-01, a iteração M1 integra a atenção relâmpago com uma estrutura MoE para alcançar eficiência sem precedentes durante o treinamento e a inferência. Essa combinação permite que o modelo mantenha alto desempenho mesmo ao processar sequências extremamente longas — um requisito essencial para tarefas que envolvem extensas bases de código, documentos legais ou literatura científica.
Arquitetura central e parametrização
Em sua essência, o MiniMax-M1 utiliza um sistema MoE híbrido que roteia tokens dinamicamente por meio de um subconjunto de sub-redes especializadas. Embora o modelo tenha um total de 456 bilhões de parâmetros, apenas 45.9 bilhões são ativados para cada token, otimizando o uso de recursos. Este design se inspira em implementações anteriores de MoE, mas refina a lógica de roteamento para minimizar a sobrecarga de comunicação entre GPUs durante a inferência distribuída.
Atenção relâmpago e suporte de longo contexto
Uma característica marcante do MiniMax-M1 é seu mecanismo de atenção relâmpago, que reduz drasticamente a carga computacional da autoatenção para sequências longas. Ao aproximar matrizes de atenção por meio de uma combinação de kernels locais e globais, o modelo reduz os FLOPs em até 75% em comparação com transformadores tradicionais ao processar sequências de 100 mil tokens. Essa eficiência não apenas acelera a inferência, mas também possibilita o processamento de janelas de contexto de até um milhão de tokens sem requisitos de hardware proibitivos.
Como o MiniMax-M1 atinge eficiência computacional?
Os ganhos de eficiência do MiniMax-M1 decorrem de duas inovações principais: sua arquitetura híbrida de Mistura de Especialistas e o novo algoritmo de aprendizado por reforço CISPO, utilizado durante o treinamento. Juntos, esses elementos reduzem o tempo de treinamento e o custo de inferência, permitindo experimentação e implantação rápidas.
Roteamento híbrido de mistura de especialistas
O componente MoE emprega 32 sub-redes de especialistas, cada uma especializada em diferentes aspectos do raciocínio ou em tarefas específicas de domínio. Durante a inferência, um mecanismo de controle de acesso aprendido seleciona dinamicamente os especialistas mais relevantes para cada token, ativando apenas as sub-redes necessárias para processar a entrada. Essa ativação seletiva reduz computações redundantes e a demanda por largura de banda de memória, concedendo ao MiniMax-M1 uma vantagem substancial em termos de custo-benefício em relação aos modelos de transformador monolítico.
CISPO: Um novo algoritmo de aprendizagem por reforço
Para aumentar ainda mais a eficiência do treinamento, a MiniMaxAI desenvolveu o CISPO (Amostragem de Importância Recortada com Substituições Parciais), um algoritmo de RL que substitui atualizações de peso em nível de token por recortes baseados em amostragem de importância. O CISPO atenua problemas de explosão de peso comuns em configurações de RL em larga escala, acelera a convergência e garante a melhoria estável das políticas em diversos benchmarks. Como resultado, o treinamento completo de RL do MiniMax-M1 em 512 GPUs H800 é concluído em apenas três semanas, custando aproximadamente US$ 534,700 — uma fração do custo relatado para execuções de treinamento GPT-4 comparáveis.
Quais são os benchmarks de desempenho do MiniMax-M1?
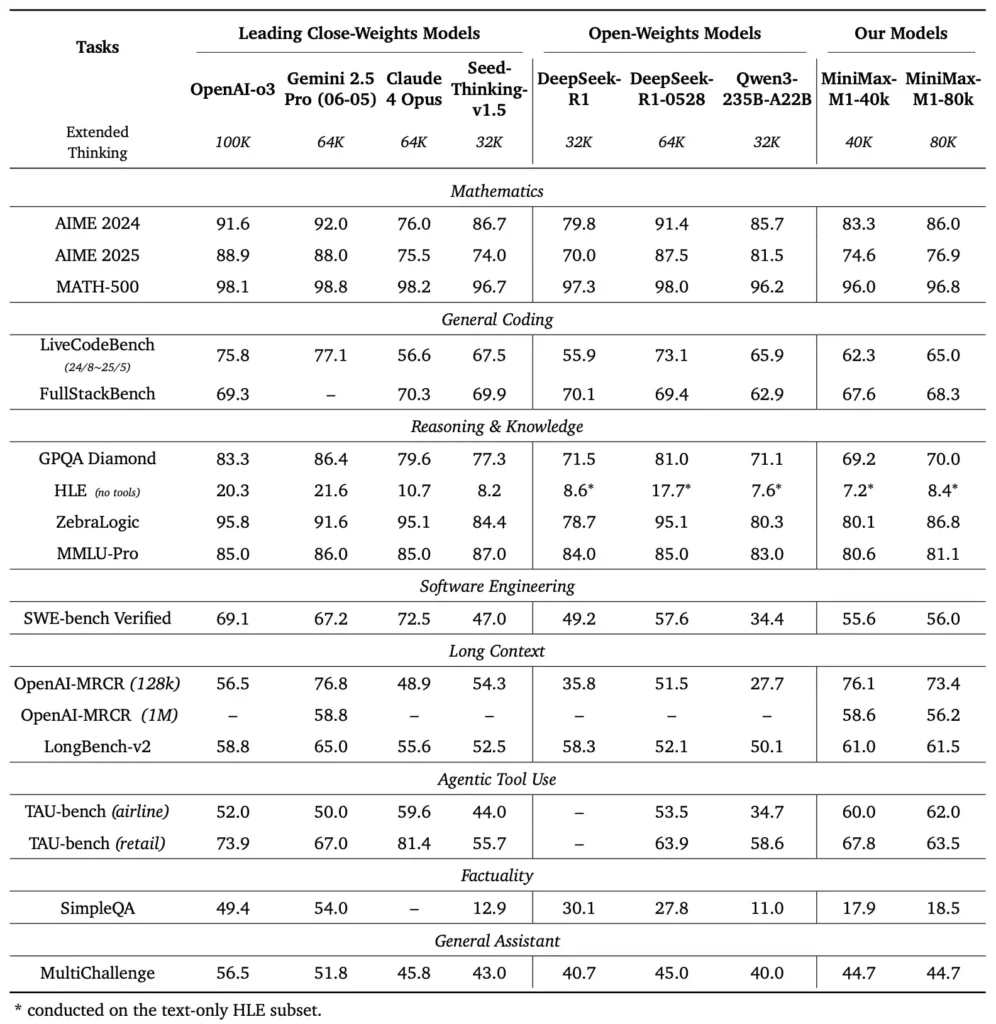
O MiniMax-M1 se destaca em uma variedade de benchmarks padrão e específicos de domínio, demonstrando sua capacidade de lidar com raciocínio de longo contexto, resolução de problemas matemáticos e geração de código.
Tarefas de raciocínio de contexto longo
Em testes extensivos de compreensão de documentos, o MiniMax-M1 processa janelas de contexto de até 1,000,000 de tokens, superando o DeepSeek-R1 em oito vezes o comprimento máximo de contexto e reduzindo pela metade os requisitos de computação para sequências de 100 mil tokens. Em benchmarks como a avaliação de contexto estendida do NarrativeQA, o modelo atinge pontuações de compreensão de última geração, atribuídas à capacidade de sua atenção relâmpago de capturar dependências locais e globais com eficiência.
Engenharia de software e utilização de ferramentas
O MiniMax-M1 foi treinado especificamente em ambientes de engenharia de software em sandbox, utilizando RL em larga escala, permitindo-lhe gerar e depurar código com precisão notável. Em benchmarks de codificação como HumanEval e MBPP, o modelo atinge taxas de aprovação comparáveis ou superiores às do Qwen3-235B e do DeepSeek-R1, particularmente em bases de código com vários arquivos e tarefas que exigem referências cruzadas de longos segmentos de código. Além disso, as primeiras demonstrações do MiniMaxAI demonstram a capacidade do modelo de se integrar a ferramentas de desenvolvedor, desde a geração de pipelines de CI/CD até fluxos de trabalho de documentação automática.
Como os desenvolvedores podem acessar o MiniMax-M1?
Para promover a adoção generalizada, a MiniMaxAI disponibilizou gratuitamente o MiniMax-M1 como um modelo de peso aberto. Os desenvolvedores podem acessar pontos de verificação pré-treinados, pesos do modelo e código de inferência por meio do repositório oficial do GitHub.
Lançamento de peso aberto no GitHub
A MiniMaxAI publicou os arquivos do modelo MiniMax-M1 e os scripts que os acompanham sob uma licença permissiva de código aberto no GitHub. Usuários interessados podem clonar o repositório em https://github.com/MiniMax-AI/MiniMax-M1, que hospeda pontos de verificação para as variantes de orçamento de tokens de 40 mil e 80 mil, bem como exemplos de integração para frameworks comuns de ML, como PyTorch e TensorFlow.
Pontos de extremidade de API e integração em nuvem
Além da implantação local, a MiniMaxAI firmou parcerias com grandes provedores de nuvem para oferecer serviços de API gerenciados. Por meio dessas parcerias, os desenvolvedores podem chamar o MiniMax-M1 por meio de endpoints RESTful, com SDKs disponíveis para Python, JavaScript e Java. As APIs incluem parâmetros configuráveis para comprimento de contexto, limites de roteamento de especialistas e orçamentos de token, permitindo que os usuários personalizem o desempenho de acordo com seus casos de uso, monitorando o consumo de computação em tempo real.
Como integrar e usar o MiniMax-M1 em aplicações reais?
Para aproveitar os recursos do MiniMax-M1, é necessário entender seus padrões de API, práticas recomendadas para prompts de contexto longo e estratégias para orquestração de ferramentas.
Exemplo básico de uso da API
Uma chamada de API típica envolve o envio de um payload JSON contendo o texto de entrada e substituições de configuração opcionais. Por exemplo:
POST /v1/minimax-m1/generate
{
"input": "Analyze the following 500K token legal document and summarize the key obligations:",
"max_output_tokens": 1024,
"context_window": 500000,
"expert_threshold": 0.6
}
A resposta retorna um JSON estruturado com texto gerado, estatísticas de uso de token e logs de roteamento, permitindo o monitoramento detalhado de ativações de especialistas.
Uso de ferramentas e agente MiniMax
Além do modelo principal, a MiniMaxAI introduziu o MiniMax Agent, uma estrutura de agente beta que pode chamar ferramentas externas — desde ambientes de execução de código até web scrapers — internamente. Os desenvolvedores podem instanciar uma sessão de agente que encadeia o raciocínio do modelo com a invocação de ferramentas, por exemplo, para recuperar dados em tempo real, realizar cálculos ou atualizar bancos de dados. Esse paradigma de agente simplifica o desenvolvimento de aplicações de ponta a ponta, permitindo que o MiniMax-M1 funcione como orquestrador em fluxos de trabalho complexos.
Melhores práticas e armadilhas
- Engenharia rápida para contextos longos: Divida as entradas em segmentos coerentes, incorpore resumos em intervalos lógicos e utilize estratégias de “resumir e depois raciocinar” para manter o foco no modelo.
- Compensação entre computação e desempenho: Experimente limites de especialistas mais baixos ou orçamentos de pensamento reduzidos (por exemplo, a variante 40K) para aplicativos sensíveis à latência.
- Monitoramento e governança: Use logs de roteamento e estatísticas de token para auditar a utilização de especialistas e garantir a conformidade com os orçamentos de custos, especialmente em ambientes de produção.
Seguindo essas diretrizes, os desenvolvedores podem aproveitar os pontos fortes do MiniMax-M1 — amplo manuseio de contexto e raciocínio eficiente — ao mesmo tempo em que reduzem os riscos associados a implantações de modelos em larga escala.
Como usar o MiniMax-M1?
Uma vez instalado, o M1 pode ser invocado por meio de scripts Python simples ou notebooks interativos.
Como é um script de inferência básico?
from minimax_m1 import MiniMaxM1Tokenizer, MiniMaxM1ForCausalLM
tokenizer = MiniMaxM1Tokenizer.from_pretrained("MiniMax-AI/MiniMax-M1-40k")
model = MiniMaxM1ForCausalLM.from_pretrained("MiniMax-AI/MiniMax-M1-40k")
inputs = tokenizer("Translate the following paragraph to French: ...", return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(outputs))
Este exemplo invoca a variante de orçamento de 40 k; trocando para "MiniMax-AI/MiniMax-M1-80k" desbloqueia o orçamento total de raciocínio de 80 k ().
Como você lida com contextos ultralongos?
Para entradas que excedem os tamanhos típicos de buffer, o M1 suporta tokenização de streaming. Use o stream=True sinalizador no tokenizador para alimentar tokens em blocos e aproveitar a inferência de reinicialização de ponto de verificação para manter o desempenho em sequências de milhões de tokens.
Como você pode ajustar ou adaptar o M1?
Embora os pontos de verificação básicos sejam suficientes para a maioria das tarefas, os pesquisadores podem aplicar o ajuste fino de RL usando o código CISPO incluído no repositório. Ao fornecer funções de recompensa personalizadas — que vão da correção do código à fidelidade semântica — os profissionais podem adaptar o M1 a fluxos de trabalho específicos de cada domínio.
Conclusão
O MiniMax-M1 se destaca como um modelo de IA inovador, expandindo os limites da compreensão e do raciocínio em linguagem de contexto longo. Com sua arquitetura híbrida MoE, mecanismo de atenção rápida e regime de treinamento apoiado pela CISPO, o modelo oferece alto desempenho em tarefas que vão da análise jurídica à engenharia de software, reduzindo drasticamente os custos computacionais. Graças à sua versão de peso aberto e às ofertas de API em nuvem, o MiniMax-M1 está acessível a um amplo espectro de desenvolvedores e organizações ávidos por construir aplicativos de IA de última geração. À medida que a comunidade de IA continua a explorar o potencial dos modelos de contexto longo, as inovações do MiniMax-M1 estão prontas para influenciar futuras pesquisas e o desenvolvimento de produtos em todo o setor.
Começando a jornada
A CometAPI fornece uma interface REST unificada que agrega centenas de modelos de IA — incluindo a família ChatGPT — em um endpoint consistente, com gerenciamento de chaves de API, cotas de uso e painéis de faturamento integrados. Em vez de lidar com várias URLs e credenciais de fornecedores.
Para começar, explore as capacidades dos modelos no Playground e consulte o Guia de API para obter instruções detalhadas. Antes de acessar, certifique-se de ter feito login no CometAPI e obtido a chave da API.
A mais recente integração da API MiniMax‑M1 aparecerá em breve no CometAPI, portanto, fique atento! Enquanto finalizamos o upload do modelo MiniMax‑M1, explore nossos outros modelos no Página de modelos ou experimentá-los no IA Playground. O modelo mais recente da MiniMax no CometAPI é Minimax ABAB7-Prévia API e API de vídeo MiniMax-01 ,consulte:
