

Uni-1 от Luma AI — это больше, чем просто новая модель text-to-image. В формулировке Luma это «мультимодальная рассуждающая модель, способная генерировать пиксели», основанная на «Unified Intelligence», благодаря чему она понимает намерение, следует указаниям и «думает вместе с вами». В техническом отчете компании говорится, что модель использует авторегрессионный трансформер с декодером (decoder-only), в котором текст и изображения представлены в единой чередующейся последовательности, и что Uni-1 может выполнять структурированное внутреннее рассуждение до и во время синтеза изображения. Эта комбинация делает Uni-1 одним из самых интересных релизов моделей изображений 2026 года.
Что такое модель изображений UNI-1?
Uni-1 — это новая модель изображений Luma AI для задач, где понимание и генерация объединены в одной системе. Luma представляет её как мультимодальную рассуждающую модель, а не классический «чисто диффузионный» движок, и это важно, потому что модель предназначена не просто для визуально приятных результатов: она создана для интерпретации инструкций, сохранения референсных ограничений и рассуждения о логике сцены в рамках генерации. Технический отчёт компании описывает Uni-1 как первую унифицированную модель понимания и генерации на пути к мультимодальному общему интеллекту.
Почему Uni-1 отличается
У старого конвейера есть потолок: генерация изображений без понимания может зайти лишь до определённой точки. Uni-1 представлена как шаг к «единому интеллекту», где язык, восприятие, воображение, планирование и исполнение обрабатываются внутри одной архитектуры. Это больше, чем просто брендинг. Uni-1 способна переходить от визуального сходства к намеренной композиции, правдоподобию и логике сцены.
Главная тенденция в том, что модели изображений становятся более агентными. Новая стек-модель от Google теперь делает упор на диалоговое редактирование, привязку к поиску, слияние нескольких изображений и консистентность персонажей; семейство GPT Image от OpenAI подчёркивает нативную мультимодальность и следование инструкциям. Uni-1 присоединяется к этому сдвигу, но ещё сильнее продвигает идею, что модель должна «подумать» об изображении до того, как начнёт его рисовать. Это делает Uni-1 особенно интересной для рабочих процессов, где точность и повторяемость важны не меньше, чем визуальная выразительность.
Как Uni-1 работает на практике?
🔬 Процесс токенизации
- Текст → последовательность токенов
- Изображение → токенизированные фрагменты
- Объединяются в единую чередующуюся последовательность
🔁 Процесс генерации
- Входной промпт + референсы
- Модель выполняет внутреннее рассуждение
- Планирует композицию
- Порождает токены последовательно
С математической точки зрения: P(x1,...,xn)=∏P(xi∣x1,...,xi−1)P(x_1,...,x_n) = \prod P(x_i | x_1,...,x_{i-1})P(x1,...,xn)=∏P(xi∣x1,...,xi−1)
🧠 Слой внутреннего рассуждения
Uni-1:
- Декомпозирует инструкции
- Разрешает ограничения
- Планирует раскладку до рендеринга
👉 Это серьёзный шаг вперёд по сравнению с диффузионными моделями.
Авторегрессионная генерация с декодером
Самая важная техническая деталь — Uni-1 авторегрессионная, а не диффузионная. В техотчёте Luma сказано, что это трансформер «только декодер» (decoder-only autoregressive), причём текст и изображения кодируются в единой чередующейся последовательности. Проще говоря, модель не просто стартует с шума и постепенно «денойзит» его до изображения. Вместо этого она порождает токены шаг за шагом, что позволяет ей рассуждать по промпту, разрешать ограничения и планировать композицию до и во время рендеринга.
🔬 Процесс токенизации
- Текст → последовательность токенов
- Изображение → токенизированные фрагменты
- Объединяются в единую чередующуюся последовательность
Диффузия vs Авторегрессия
| Характеристика | Диффузионные модели | Uni-1 (авторегрессия) |
|---|---|---|
| Генерация | Шум → Изображение | Токен-за-токеном |
| Рассуждение | Ограниченное | Сильное |
| Редактирование | Слабое | Многошаговое |
| Отрисовка текста | Плохая | Сильная |
| Управляемость | Низкая | Высокая |
Базовая архитектура
Uni-1 — это:
- Авторегрессионный трансформер только с декодером
- Общая токен-пространство для текста и изображений
Эта архитектура важна, потому что она даёт модели шанс сохранять целостность при сложных промптах. Luma утверждает, что Uni-1 может декомпозировать инструкции, разрешать конфликтующие ограничения и планировать изображение до начала рендеринга. Это особенно полезно для задач вроде структурного дополнения сцен, размещения нескольких объектов, многошаговой доработки и правок, где выход должен оставаться верным референсному изображению, одновременно подчиняясь новым инструкциям.
Что модель, по задумке, делает лучше
Обучение генерации изображений улучшает понимание. Luma говорит, что обучение генерации существенно повышает тонкое визуальное понимание, особенно по областям, объектам и раскладкам. Поэтому Uni-1 рассматривается не как односторонний генератор, а как унифицированная система, в которой генерация и понимание взаимно усиливают друг друга. На этапе инференса это означает, что Uni-1 стремится закрыть разрыв между «видеть» и «создавать». Это серьёзный шаг вперёд по сравнению с диффузионными моделями.
Generation Process:
- Входной промпт + референсы
- Модель выполняет внутреннее рассуждение
- Планирует композицию
- Порождает токены последовательно
С математической точки зрения: P(x1,...,xn)=∏P(xi∣x1,...,xi−1)P(x_1,...,x_n) = \prod P(x_i | x_1,...,x_{i-1})P(x1,...,xn)=∏P(xi∣x1,...,xi−1)
Какие возможности и ключевые преимущества предлагает Uni-1?
Сильное следование инструкциям и управляемость
Самая сильная сторона Uni-1 — контроль. Модель создана для точного редактирования, структурной работы с референсами и повторяемых рабочих процессов. Для создателей это означает меньше «азартной» генерации по промпту и более воспроизводимые результаты.
Одно из практических преимуществ — модель ориентирована на контролируемую итеративность. Сиды позволяют воспроизводить результаты, а роли референсов помогают модели понимать, должно ли изображение задавать идентичность персонажа, настроение, палитру или композицию. Это делает Uni-1 проще в управлении, чем модель, полностью зависящая от текста, особенно для команд, создающих рекламу, раскадровки, продуктовые макеты или бренд-ассеты, где важна консистентность.
Генерация на основе референсов с сохранением идентичности
Крупное преимущество — работа с референсами. Luma прямо заявляет, что Uni-1 использует элементы управления, привязанные к источникам, и может сохранять идентичность, композицию и ключевые визуальные ограничения по одному или нескольким референсам. Это делает модель привлекательной для коммерческих рабочих процессов — бренд-персонажи, продуктовые макеты, материалы кампаний и любые проекты, где субъект должен оставаться узнаваемым в вариациях. Это один из самых явных способов, которыми Uni-1 отличается от более «эстетических» систем.
Культурная осведомлённость и широта стилей
Luma также подчёркивает культурно-осознанную генерацию. Раздел «Cultured» указывает на мемы, мангу, кинематографические стили, бытовые фото, спорт и животных, показывая, что модель предназначена для работы в разных визуальных «языках», а не в одном универсальном стиле. Это важно, потому что хорошая современная модель изображений должна не только уметь рендерить реалистичную сцену; ей нужно понимать визуальные конвенции интернет-культуры, редакционного дизайна, стилизованной иллюстрации и социального контента.
Мультимодальное мышление как дизайн-принцип
Ключевое отличие в том, что Uni-1 не просто генерирует изображения, а рассматривает их создание как задачу рассуждения. Uni-1 способна к структурированному внутреннему рассуждению, а обучение генерации изображений улучшает тонкое визуальное понимание областей, объектов и раскладок. Это говорит о модели, которая должна понимать сцену до рендеринга, а не просто статистически аппроксимировать промпт.
Показатели производительности
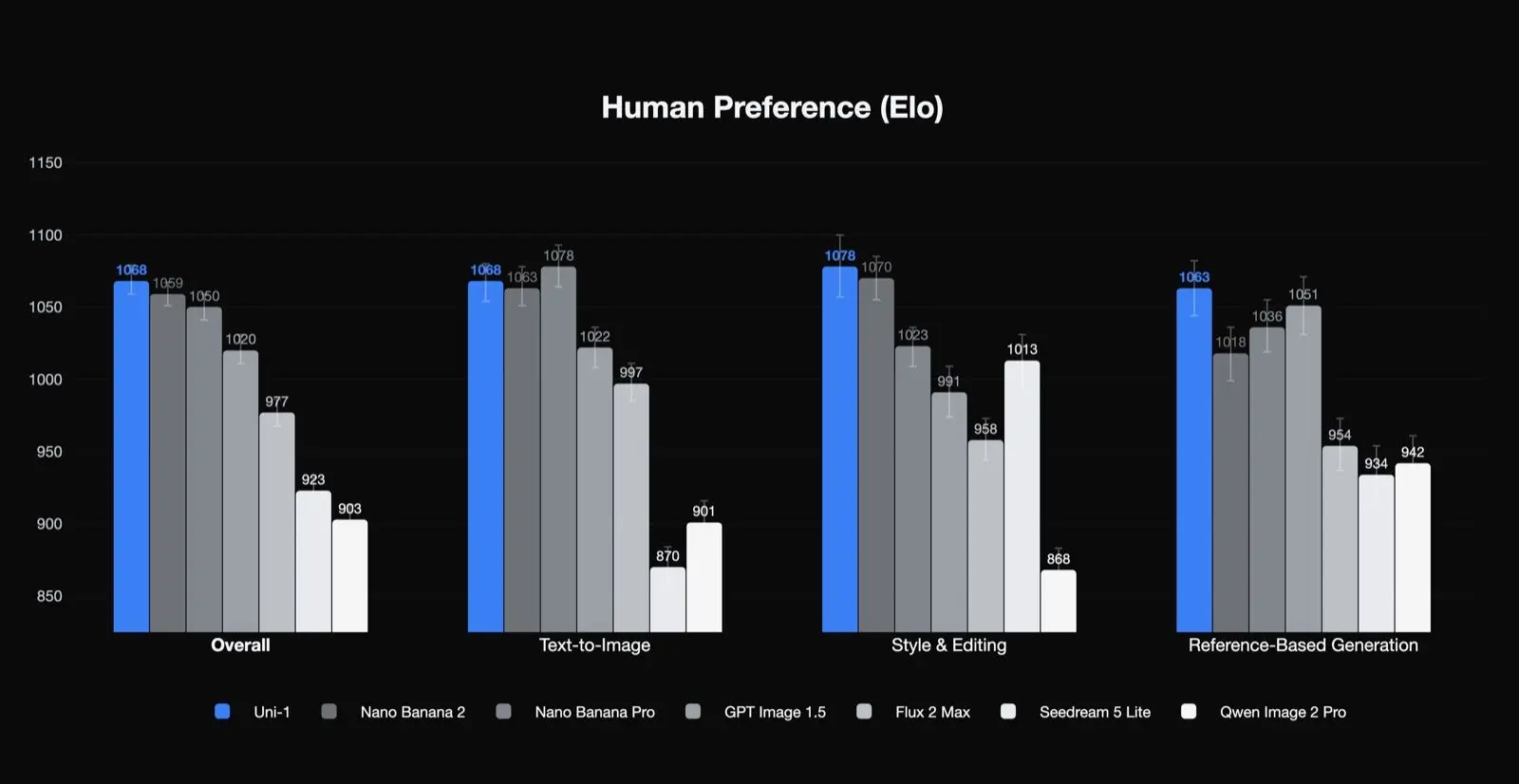
Собственные результаты Luma по человеческим предпочтениям
Uni-1 занимает первое место в рейтинге Elo по человеческим предпочтениям за общее качество, стиль и редактирование, а также генерацию на основе референсов, и второе место по text-to-image. Это значимо, потому что показывает особую силу модели в типах задач, которые важны для продакшн-команд: редактирование, консистентность и управляемые преобразования. Это также намекает, что лучшие кейсы использования — не одиночная генерация по одному промпту.
RISEBench: редактирование изображений, информируемое рассуждением
Самый заметный бенчмарк — RISEBench, оценивающий редактирование изображений, требующее рассуждений во временном, причинно-следственном, пространственном и логическом аспектах. По сторонним сообщениям о запуске Luma, Uni-1 набирает 0.51 по RISEBench в целом — выше, чем Nano Banana 2 от Google с 0.50, Nano Banana Pro с 0.49 и GPT Image 1.5 от OpenAI с 0.46. По пространственному рассуждению у Uni-1 указано 0.58 против 0.47 у Nano Banana 2. По логическому рассуждению у Uni-1 — 0.32, более чем вдвое выше, чем у GPT Image 1.5 с 0.15. В сумме разрывы невелики, но в самых сложных категориях рассуждения они значительны.

ODinW-13 и тезис «генерация улучшает понимание»
Uni-1 также показывает сильные результаты на ODinW-13, бенчмарке плотного обнаружения с открытой словарной базой. По данным из отчёта Luma, полная модель достигает 46.2 mAP, почти приближаясь к Gemini 3 Pro от Google с 46.3. Там же говорится, что вариант только для понимания набирает 43.9 mAP, что означает улучшение понимания на 2.3 пункта благодаря обучению генерации. Это примечательно, потому что поддерживает основной тезис Luma: генерация изображений и понимание изображений могут взаимно усиливаться, а не конкурировать.
Цена API Uni-1
| Цена входа (текст) | $0.50 |
|---|---|
| Цена входа (изображения) | $1.20 |
| Цена выхода (текст и «мышление») | $3.00 |
| Цена выхода (изображения) | $45.45 |
Для потребителей страница цен Luma указывает Plus за $30/месяц, Pro за $90/месяц и Ultra за $300/месяц, с бесплатными тестовыми кредитами во всех планах. То есть фактически нужно учитывать два уровня ценообразования: потребительскую подписку на платформу и уровень цен API модели для продакшн-использования.
Пока что Uni-1 API от CometAPI имеет статус Available Soon, с обещанной скидкой при запуске. В настоящее время CometAPI также предлагает отличные «сырые» модели генерации изображений, такие как Midjourney и Nano Banana 2.
Uni-1 vs GPT Image 1.5 vs Nano Banana 2
Uni-1 против Nano Banana 2 от Google
Nano Banana 2 выглядит сильнее по широте работы с референсами и интеграции в экосистему. Google делает акцент на привязке к поиску изображений, диалоговой итерации и референсно-насыщенных сценариях с до 14 референсов. Uni-1, напротив, более явно сфокусирована на рассуждении, правдоподобии сцены и точном редактировании в рамках унифицированной архитектуры. На практике Google оптимизирован под скорость, массовый продакшн и нативную привязку к сервисам Google; Luma — под структурное визуальное рассуждение и управляемое редактирование изображений.
В публичных сравнениях вокруг Uni-1 компромисс очевиден: Nano Banana 2 остаётся очень сильной для чистого качества text-to-image и скорости, тогда как Uni-1 делает упор на редактирование, требующее рассуждения, контроль референсов и точное следование инструкциям.
Uni-1 против GPT Image от OpenAI
В отчётах по бенчмаркам Uni-1 чуть опережает GPT Image 1.5 на RISEBench в целом и заметнее — по логическому рассуждению. В сравнении с семейством GPT Image от OpenAI Uni-1 более узко и агрессивно позиционируется вокруг визуального рассуждения и контролируемого редактирования. Документация OpenAI подчёркивает мировые знания, мультимодальное понимание и контекстную осведомлённость; документация Luma — структурированное внутреннее рассуждение, управление по референсам и проверенные метриками навыки визуального редактирования. То есть обе системы мультимодальны, но Uni-1 — это более очевидная «специализированная рассуждающая модель для изображений», тогда как GPT Image — это общий мультимодальный стэк, который, помимо прочего, отлично генерирует изображения.
Сравнение цен для всех троих
По ценам многое зависит от размера вывода и тарифов, поэтому сравнение не полностью эквивалентно. Опубликованный для Uni-1 эквивалент 2048px — около $0.0909 за изображение. На последней странице цен модели изображений Google указано $0.134 за изображение 1K/2K и $0.24 за 4K для последнего превью Gemini image, тогда как страница цен OpenAI для GPT Image указывает $0.011 за изображение при низком качестве 1024x1024, $0.042 при среднем и $0.167 при высоком, а для более крупных высококачественных выводов — $0.25. Иными словами, OpenAI может быть значительно дешевле на нижнем уровне, Google агрессивна в сегменте скорости и масштаба, а Uni-1 оказывается посередине с сильным профилем цены/качества для 2K.
Философские различия
| Модель | Подход |
|---|---|
| Uni-1 | Унифицированный мультимодальный интеллект |
| GPT Image | LLM + генерация изображений |
| Nano Banana 2 | Оптимизированная продакшн-диффузия |
Подробная таблица сравнения
| Характеристика | Uni-1 | GPT Image 1.5 | Nano Banana 2 |
|---|---|---|---|
| Архитектура | Авторегрессивная | Гибридная | Диффузионная |
| Мультимодальная унификация | ✅ Нативная | Частичная | ❌ |
| Способности к рассуждению | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ |
| Качество изображения | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| Отрисовка текста | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐ |
| Рабочие процессы редактирования | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ |
| Скорость | Средняя | Быстрая | Быстрая |
| Управляемость | Высокая | Средняя | Средняя |
CometAPI предоставляет интерактивную генерацию изображений для GPT Image 1.5, Nano Banana 2, а также будущей Uni-1, и предлагает программный доступ к API. Скидочные цены и оплата по факту делают её предпочтительным выбором для разработчиков.
Для чего лучше всего подходит Uni-1
Uni-1 выглядит особенно сильной в случаях, когда вам нужны повторяемость, консистентность персонажей или контроль с несколькими референсами. Это включает бренд-кампании, продуктовые макеты, редакционные концепты, раскадровки, локализованные варианты и правки изображений, где композиция должна сохраняться, но стиль или окружение могут меняться. Собственные примеры Luma сильно акцентируют именно эти сценарии, а разделение модели на «Create vs Modify» — по сути прямой ответ на частые продакшн-боли.
Если ваша работа в основном сводится к «сделать что-то красивое по одному промпту», разница может показаться менее драматичной. Но если ваш процесс — «сделать пять связанных версий, сохранить того же персонажа, выдержать кадрирование, изменить свет и суметь воспроизвести результат на следующей неделе», дизайн Uni-1 начинает очень логично смотреться. Это вывод по косвенным признакам, но он естественно следует из подчёркнутых Luma возможностей контроля.
Лучшие практики для получения лучших результатов с Uni-1
Начните с правильного режима. Рекомендации Luma просты: Create, когда вам нужна новая сцена, Modify, когда вы хотите сохранить существующую. Смешение намерений делает результаты менее устойчивыми.
Используйте метки референсов как профессионал. Luma рекомендует формулировки вроде «Use IMAGE1 as a STYLE reference» или «Use IMAGE2 as LIGHTING». Модель работает лучше, когда у каждого референса есть роль, а не расплывчатое «вдохновение».
Зафиксируйте сид, когда найдёте удачный результат. Luma прямо советует сначала исследовать без сида, затем сохранить сид после получения сильного результата. После этого меняйте по одному параметру за раз. Это самый простой способ превратить генерацию в управляемую производственную систему.
Будьте конкретны и предметны. Luma предостерегает от расплывчатых слов вроде «beautiful» или «amazing» и поощряет именованные эстетики типа «постер итальянского джалло 1970‑х» или точные указания по кадру и камере. На практике конкретные промпты обычно выигрывают у поэтических, поскольку модель может опереться на реальную структуру.
Используйте цепочку Create → Modify. Luma прямо называет это одним из самых мощных сценариев: исследуйте в Create, затем уточняйте в Modify. Это «сладкое место» для серьёзной продакшн-работы, потому что уменьшает откаты и сохраняет удачные части композиции, одновременно докручивая детали.
Итоговый вывод
Uni-1 — это самое ясное заявление Luma о том, что генерация изображений движется от «ввод промпта — вывод картинки» к управляемому рассуждением визуальному созданию. Её публичные сильные стороны — контроль, работа с референсами, воспроизводимость и архитектура, которая удерживает язык и пиксели в одной системе.
Для создателей и команд, которым важны высококликабельные визуалы, консистентные персонажи, точные правки и ясная стоимость высоких разрешений, Uni-1 — определённо модель, за которой стоит следить. Если запуск API пройдет гладко, она может стать одной из самых интересных альтернатив Nano Banana 2 от Google и GPT Image 1.5 от OpenAI в 2026 году.
Планируете начать создавать «сырые» изображения? CometAPI, единая платформа-агрегатор для API мультимодальных моделей, ждёт вас!