

DeepSeek выпустила DeepSeek V3.2 как преемника линейки V3.x и сопутствующий вариант DeepSeek‑V3.2‑Speciale, который компания позиционирует как высокопроизводительное издание «с приоритетом на рассуждение» для использования агентами/инструментами. V3.2 опирается на экспериментальную ветку (V3.2‑Exp) и приносит повышенные способности к рассуждению, издание Speciale, оптимизированное для «золотого уровня» в математике/соревновательном программировании, а также то, что DeepSeek описывает как первую в своём роде двухрежимную систему «мышление + инструмент», тесно интегрирующую внутреннее пошаговое рассуждение с внешними вызовами инструментов и агентными рабочими процессами.
Что такое DeepSeek V3.2 — и чем отличается V3.2‑Speciale?
DeepSeek‑V3.2 — официальный преемник экспериментальной ветки DeepSeek V3.2‑Exp. DeepSeek описывает его как семейство моделей «с приоритетом на рассуждение», созданных для агентов, то есть моделей, настроенных не только на естественное качество диалога, но и специально на многошаговый вывод, вызов инструментов и надёжные рассуждения в стиле цепочек мыслей в средах с внешними инструментами (API, выполнение кода, коннекторы данных).
Что такое DeepSeek‑V3.2 (базовая)
- Позиционируется как массовый продакшен-преемник экспериментальной линии V3.2‑Exp; предназначена для широкого доступа через приложение/веб/API DeepSeek.
- Сохраняет баланс между вычислительной эффективностью и устойчивыми рассуждениями для агентных задач.
Что такое DeepSeek‑V3.2‑Speciale
DeepSeek‑V3.2‑Speciale — вариант, который DeepSeek продвигает как «Special Edition» повышенной мощности, настроенный на уровень соревнований в рассуждениях, продвинутую математику и производительность агентов. Позиционируется как более мощный вариант, «расширяющий границы возможностей рассуждения». В настоящее время DeepSeek предоставляет Speciale только через API с временной схемой доступа; ранние бенчмарки указывают, что он нацелен на конкуренцию с высокоуровневыми закрытыми моделями в задачах рассуждения и кодирования.
Какая линия развития и инженерные решения привели к V3.2?
V3.2 унаследовала итеративную инженерную линию, которую DeepSeek освещал в течение 2025 года: V3 → V3.1 (Terminus) → V3.2‑Exp (экспериментальный шаг) → V3.2 → V3.2‑Speciale. Экспериментальная V3.2‑Exp представила DeepSeek Sparse Attention (DSA) — тонкозернистый механизм разреженного внимания, нацеленный на снижение затрат памяти и вычислений для очень больших окон контекста при сохранении качества вывода. Эти исследования DSA и работа по снижению стоимости стали техническим трамплином для официального семейства V3.2.
Что нового в официальной DeepSeek 3.2?
1) Усиленные способности к рассуждению — что именно улучшено?
DeepSeek продвигает V3.2 как «reasoning‑first». Это означает, что архитектура и дообучение сосредоточены на надёжном выполнении многошагового вывода, поддержке внутренних цепочек рассуждений и видах структурированной делиберации, которые необходимы агентам для корректного использования внешних инструментов.
Конкретные улучшения включают:
- Обучение и RLHF (или аналогичные процедуры согласования), нацеленные на явное пошаговое решение задач и стабильные промежуточные состояния (полезно для математических рассуждений, многошаговой генерации кода и логических задач).
- Архитектурные решения и функции потерь, которые сохраняют более длинные окна контекста и позволяют модели с высокой точностью ссылаться на более ранние шаги рассуждения.
- Практические режимы (см. «двухрежимность» ниже), позволяющие одной и той же модели работать либо в более быстром «чат»-режиме, либо в делиберативном «режиме мышления», где она намеренно проходит через промежуточные шаги до действия.
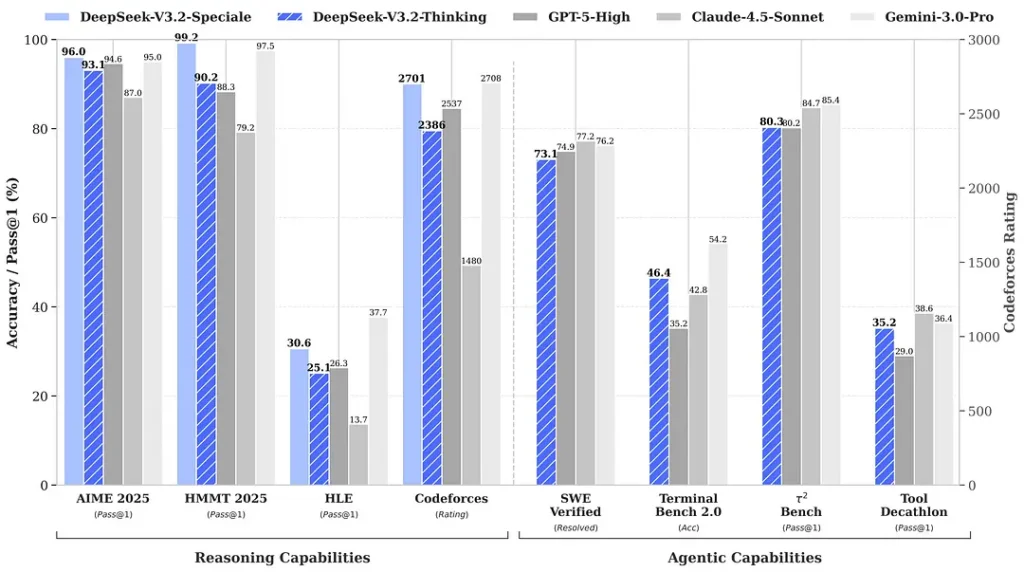
Бенчмарки, приведённые вокруг релиза, заявляют о заметном росте результатов в математических и рассуждательных наборах; независимые ранние оценки сообщества также фиксируют впечатляющие показатели на конкурентных наборах:
2) Прорывная производительность в Special Edition — насколько лучше?
DeepSeek‑V3.2‑Speciale, как заявляется, обеспечивает шаг вперёд в точности рассуждений и оркестровке агентов по сравнению со стандартной V3.2. Провайдер позиционирует Speciale как уровень производительности, нацеленный на тяжёлые рассуждательные нагрузки и сложные агентные задачи; сейчас это API‑only и предлагается как временная, более мощная конечная точка (DeepSeek указывает, что доступ к Speciale поначалу будет ограниченным). Версия Speciale интегрирует предыдущую математическую модель DeepSeek‑Math‑V2; она может доказывать математические теоремы и самостоятельно проверять логические рассуждения; она добилась выдающихся результатов в нескольких соревнованиях мирового уровня:
- 🥇 IMO (International Mathematical Olympiad) — Золотая медаль
- 🥇 CMO (Chinese Mathematical Olympiad) — Золотая медаль
- 🥈 ICPC (International Computer Programming Contest) — Второе место (человеческий конкурс)
- 🥉 IOI (International Olympiad in Informatics) — Десятое место (человеческий конкурс)
| Бенчмарк | GPT-5 High | Gemini-3.0 Pro | Kimi-K2 Thinking | DeepSeek-V3.2 Thinking | DeepSeek-V3.2 Speciale |
|---|---|---|---|---|---|
| AIME 2025 | 94.6 (13k) | 95.0 (15k) | 94.5 (24k) | 93.1 (16k) | 96.0 (23k) |
| HMMT Feb 2025 | 88.3 (16k) | 97.5 (16k) | 89.4 (31k) | 92.5 (19k) | 99.2 (27k) |
| HMMT Nov 2025 | 89.2 (20k) | 93.3 (15k) | 89.2 (29k) | 90.2 (18k) | 94.4 (25k) |
| IMOAnswerBench | 76.0 (31k) | 83.3 (18k) | 78.6 (37k) | 78.3 (27k) | 84.5 (45k) |
| LiveCodeBench | 84.5 (13k) | 90.7 (13k) | 82.6 (29k) | 83.3 (16k) | 88.7 (27k) |
| CodeForces | 2537 (29k) | 2708 (22k) | — | 2386 (42k) | 2701 (77k) |
| GPQA Diamond | 85.7 (8k) | 91.9 (8k) | 84.5 (12k) | 82.4 (7k) | 85.7 (16k) |
| HLE | 26.3 (15k) | 37.7 (15k) | 23.9 (24k) | 25.1 (21k) | 30.6 (35k) |
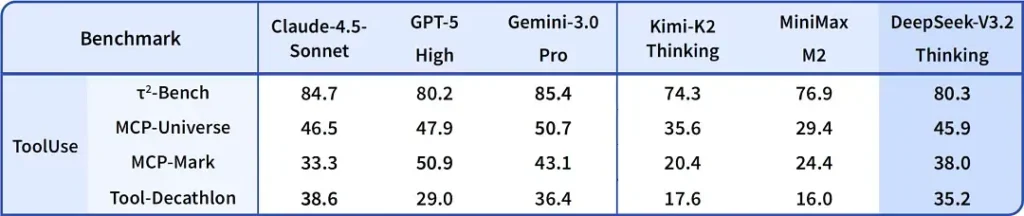
Первая реализация двухрежимной системы «мышление + инструмент»
Одним из наиболее практично интересных заявлений в V3.2 является двухрежимный рабочий процесс, который разделяет (и позволяет выбирать между) быструю разговорную работу и более медленный, делиберативный «режим мышления», тесно интегрированный с использованием инструментов.
- «Чат/быстрый» режим: Спроектирован для низкой задержки, пользовательских диалогов с лаконичными ответами и меньшим количеством внутренних трасс рассуждений — подходит для повседневной помощи, коротких вопросов‑ответов и приложений, критичных к скорости.
- «Мышление/reasoner» режим: Оптимизирован для строгих цепочек мыслей, пошагового планирования и оркестровки внешних инструментов (API, запросы к базам данных, выполнение кода). При работе в режиме мышления модель выдаёт более явные промежуточные шаги, которые можно инспектировать или использовать для запуска безопасных, корректных вызовов инструментов в агентных системах.
Этот паттерн (двухрежимный дизайн) присутствовал в ранних экспериментальных ветках, и DeepSeek глубже интегрировал его в V3.2 и Speciale — Speciale в настоящее время поддерживает исключительно режим мышления (поэтому доступ ограничен через API). Возможность переключаться между скоростью и делиберацией ценна для инженерии, поскольку позволяет разработчикам выбирать правильный компромисс между задержкой и надёжностью при построении агентов, которые должны взаимодействовать с реальными системами.
Почему это важно: многие современные системы предлагают либо сильную модель с цепочкой мыслей (для объяснения рассуждений), либо отдельный слой оркестровки агентов/инструментов. Формулировка DeepSeek подразумевает более тесную связку — модель может «думать», а затем детерминированно вызывать инструменты, используя ответы инструментов для последующего мышления — что более бесшовно для разработчиков, создающих автономных агентов.
Где получить DeepSeek v3.2
Короткий ответ — получить DeepSeek v3.2 можно несколькими способами в зависимости от нужд:
- Официальный веб/приложение (онлайн) — попробуйте веб‑интерфейс DeepSeek или мобильное приложение, чтобы использовать V3.2 интерактивно.
- Доступ через API — DeepSeek предоставляет V3.2 через свой API (документация включает названия моделей /
base_urlи цены). Зарегистрируйтесь, получите ключ API и вызывайте endpoint v3.2. - Скачиваемые/открытые веса (Hugging Face) — модель (варианты V3.2 / V3.2‑Exp) опубликована на Hugging Face и доступна для загрузки (open‑weight). Используйте
huggingface-hubилиtransformers, чтобы получить файлы. - CometAPI — платформа‑агрегатор AI API предоставляет хостинг endpoint’ов V3.2‑Exp. Цена ниже официальной.
Несколько практических замечаний:
- Если вам нужны веса для локального запуска, перейдите на страницу модели на Hugging Face (примите лицензию/условия доступа) и используйте
huggingface-cliилиtransformersдля загрузки; как правило, точные команды приведены в репозитории GitHub. - Если вам нужен продакшен через API, следуйте документации выбранной платформы, например CometAPI, по названиям endpoint’ов и корректному
base_urlдля варианта V3.2.
DeepSeek‑V3.2‑Speciale:* Только для исследовательского использования, поддерживает диалог в «режиме мышления», но не поддерживает вызовы инструментов.
- Максимальный вывод может достигать 128K токенов (ультрадлинная цепочка мышления).
- В настоящее время бесплатен для тестирования до 15 декабря 2025 года.
Заключение
DeepSeek‑V3.2 представляет собой важный шаг в зрелости моделей, ориентированных на рассуждение. Сочетание улучшенного многошагового вывода, специализированного высокопроизводительного издания (Speciale) и промышленной интеграции «мышление + инструмент» заслуживает внимания всех, кто строит продвинутых агентов, ассистентов для кодирования или исследовательские пайплайны, которым нужно чередовать делиберацию с внешними действиями.
Разработчики могут получить доступ к DeepSeek V3.2 через CometAPI. Для начала изучите возможности модели на CometAPI в Playground и обратитесь к API guide за подробными инструкциями. Перед доступом убедитесь, что вы вошли в CometAPI и получили ключ API. CometAPI предлагает цену значительно ниже официальной, чтобы помочь вам с интеграцией.
Готовы начать?→ Зарегистрируйтесь в CometAPI сегодня!
Если хотите получать больше советов, гайдов и новостей об ИИ, следите за нами в VK, X и Discord!