

Seedance 2.0 — это новое поколение модели генерации видео от ByteDance, официально запущенной в марте 2026 года. Она поддерживает ввод текста, изображений, аудио и видео, может использовать до 9 изображений, 3 видеоклипа и 3 аудиоклипа в качестве референсов и ориентирована на управление на уровне режиссёра, устойчивость движения и совместную генерацию аудио и видео. В текущих рейтингах со слепым голосованием Artificial Analysis Seedance 2.0 лидирует как в категориях text-to-video, так и image-to-video без аудио, с рейтингами Elo 1269 и 1351 соответственно.
Что такое Seedance 2.0?
Seedance 2.0 — это новое поколение модели создания видео от ByteDance Seed. Официально она построена на единой мультимодальной архитектуре совместной генерации аудио и видео, принимающей текст, изображения, аудио и видео, и позиционируется как инструмент для создателей с необычно широкими возможностями по работе с референсами и редактированием. Seedance 2.0 создана для промышленных контент‑процессов и превосходит версию 1.5 по физической достоверности, реалистичности, управляемости и стабильности в сценах со сложной динамикой. В отличие от ранних моделей, сосредоточенных преимущественно на text-to-video, Seedance 2.0 вводит полностью единую мультимодальную конвейерную генерацию, позволяющую:
- Генерацию видео по тексту
- Анимацию по изображению (image-to-video)
- Редактирование видео (video-to-video)
- Синхронизированный вывод аудио
Это делает её одной из самых всеобъемлющих платформ для создания видео с ИИ в 2026 году.
Почему это важно?
Большинство генераторов видео всё ещё оптимизированы под сравнительно узкий сценарий: «промпт на вход — клип на выход». Seedance 2.0 идёт дальше, обращаясь с генерацией видео как с рабочим местом режиссёра. По данным ByteDance, она может одновременно использовать несколько типов референсов, сохранять согласованность субъекта, точнее следовать детальным инструкциям и даже планировать «язык камеры» более режиссёрским образом. Это важно потому, что самые сложные проблемы в генерации видео — не только эстетика, но непрерывность, согласованность движения и контроль над тем, что происходит во времени.
Что нового и ключевые возможности Seedance 2.0?
Единая мультимодальная генерация
Самая важная особенность — способность модели совместно рассуждать по нескольким модальностям. Seedance 2.0 поддерживает до 9 изображений, 3 видео и 3 аудиоклипов в качестве референсов вместе с инструкциями на естественном языке и может генерировать ролики до 15 секунд. На практике это значит, что вы можете задавать не только объект и сцену, но и стиль движения, работу камеры, спецэффекты и аудиосигналы в одном проходе генерации.
Управление на уровне режиссёра
Seedance 2.0 также построена вокруг того, что ByteDance называет управлением на уровне режиссёра. Создатели могут формировать игру, свет, тени и движение камеры, используя референсы изображений, аудио и видео. Модель может сохранять стабильную идентичность персонажей, точно воспроизводить сложные сценарии и выбирать «язык камеры» в духе встроенной логики монтажа. Для создателей это шаг далеко за пределы базового text-to-video.
Редактирование и расширение, а не только генерация
Ещё одно заметное улучшение — Seedance 2.0 не ограничивается генерацией. Она добавляет возможности редактирования и расширения видео, позволяя целенаправленно изменять конкретные сцены, персонажей, действия или сюжетные точки, а также обеспечивать непрерывные последующие кадры. В статье для разработчиков также объясняется, что модель можно использовать для «продолжения съёмки» путём расширения клипа вместо начала с нуля. Это важно для эффективности рабочего процесса, поскольку снижает необходимость регенерировать всю сцену ради исправления одного фрагмента.
Лучшее обращение со сложной динамикой
Seedance 2.0 заметно сильнее в сценах с несколькими субъектами, взаимодействиями и сложным движением. Качество генерации существенно выросло по сравнению с версией 1.5: улучшились физическая достоверность, реалистичность и управляемость. Доля пригодных результатов в сложных сценах движения достигает уровня SOTA по внутренней оценке, при этом признаётся, что дальнейшие улучшения всё ещё необходимы в стабильности мелких деталей, реалистичности и выразительности.
Тесты производительности
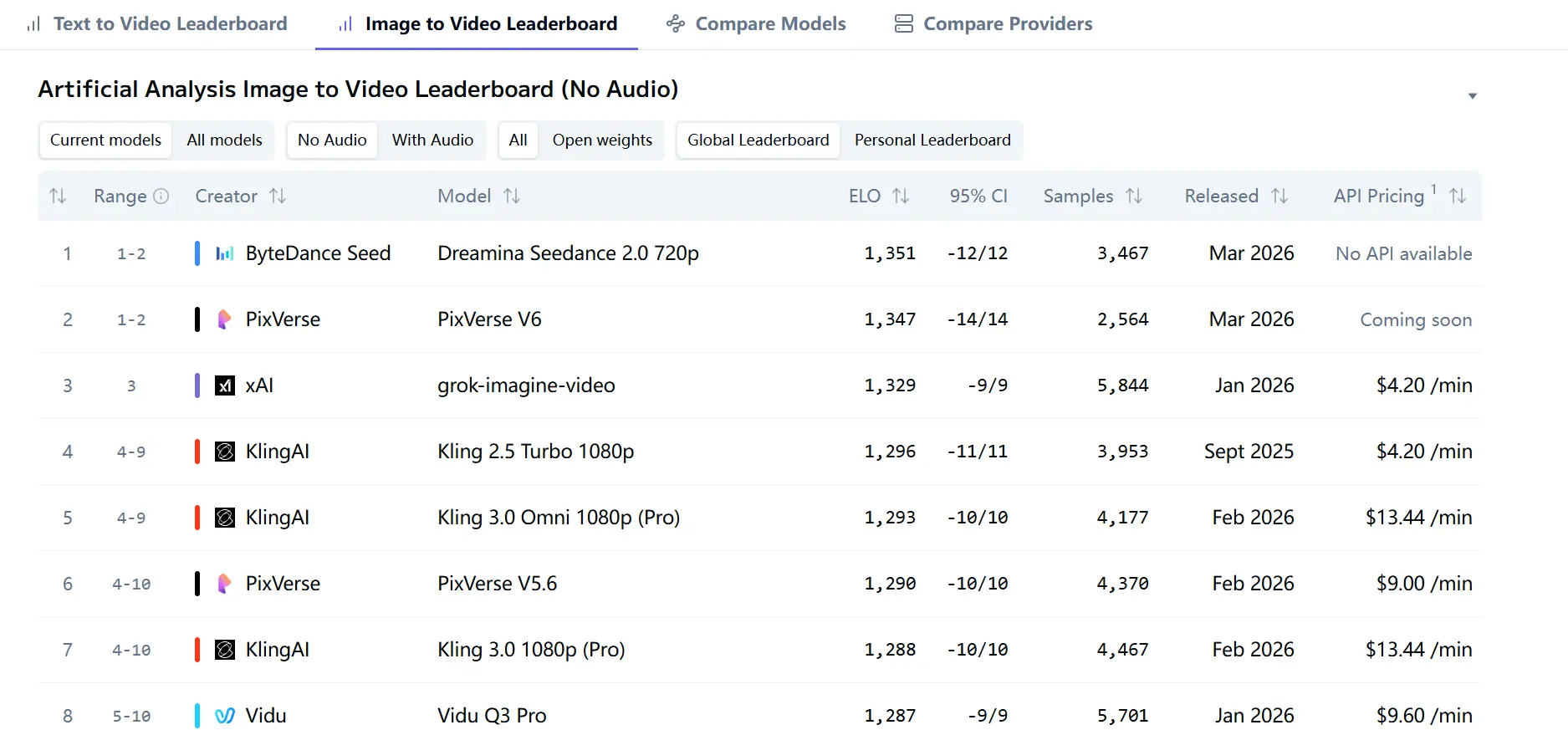
Самым сильным внешним сигналом среди рассмотренных источников является Artificial Analysis Video Arena. На текущих страницах рейтингов Dreamina Seedance 2.0 720p лидирует в Image-to-Video Arena без аудио с Elo 1351 и в Text-to-Video Arena без аудио с Elo 1269. Там же указано, что ранжирование основано на слепом голосовании пользователей, что важно, поскольку измеряет человеческие предпочтения в масштабе, а не только внутренние метрики модели.
Это важно, потому что означает: Seedance 2.0 не просто маркетируется как «способная» — она в настоящее время предпочитается пользователями в парных сравнениях на двух крупных аренах. В text-to-video без аудио она опережает Kling 3.0 1080p (Pro), SkyReels V4, PixVerse V6 и Kling 3.0 Omni 1080p (Pro). В image-to-video без аудио она с небольшим отрывом опережает PixVerse V6 и grok-imagine-video.

Seedance 2.0: срез производительности
| Metric | Seedance 2.0 |
|---|---|
| Image-to-Video Rank | Топ-15 в мире |
| ELO Score | ~1258 |
| Text-to-Video Rank | Топ-25 |
| Cost | ~$1.56/мин |
| Strength | Баланс цены и качества |
👉 Интерпретация:
- Это не всегда №1 по чистому качеству
- Но выдающееся соотношение ценности и производительности
Насколько хороша Seedance 2.0 на самом деле?
Её сильнейшие стороны
Главные сильные стороны Seedance 2.0 очевидны: она лучше многих видеомоделей справляется со сложной динамикой, поддерживает несколько референсных модальностей, предлагает редактирование и расширение, а также лидирует в наиболее заметных публичных рейтингах в text-to-video и image-to-video без аудио. Улучшения в физической достоверности, реалистичности и управляемости — именно те качества, которые важны при переходе модели от демонстрационных роликов к профессиональным рабочим процессам.
Текущие ограничения
ByteDance не представляет Seedance как безупречную. Остаётся пространство для улучшения стабильности деталей, реалистичности и выразительности движения; также отмечаются остающиеся вызовы в согласованности нескольких объектов, точности рендеринга текста и сложных эффектах редактирования.
Моя оценка
Судя по рассмотренным источникам, Seedance 2.0 — это не косметическое обновление, а серьёзный шаг к системе видео промышленного уровня. Её главная сила — не один эффектный демо‑ролик, а сочетание более широкой мультимодальной входной конфигурации, прямых средств редактирования, расширения клипов и убедительного лидерства в публичных рейтингах. Это делает её одной из самых важных видеомоделей на рынке, особенно для команд, которым так же важна управляемость, как и «сырой» кинематографический уровень.
Seedance 2.0 vs Sora 2 vs Veo 3.1
Таблица сравнения (лидеры ИИ‑видео 2026)
| Feature | Seedance 2.0 | Sora 2 | Veo 3.1 |
|---|---|---|---|
| Developer | ByteDance | OpenAI | |
| Input Types | Text, image, audio, video | Text | Text + image |
| Audio Generation | ✅ Native | ❌ Limited | ✅ |
| Max Video Length | 15–20 сек | ~25 сек | ~8 сек (расширяемо) |
| Editing Capability | ⭐ Advanced (reference-based) | Средняя | Средняя |
| ELO Ranking | Топ-15–25 | Высокий | Высокий |
| Cost Efficiency | ⭐ High | Средняя | Средняя |
| Commercial Use | Yes | Ограниченно (водяной знак) | Yes |
| Unique Strength | Мультимодальное редактирование | Длина повествования | Визуальная точность |
Ключевые выводы
- Seedance 2.0 = лучшее редактирование + мультимодальная гибкость
- Sora 2 = лучшая длина повествования
- Veo 3.1 = лучшая визуальная точность image-to-video
В текущем рейтинге Artificial Analysis по text-to-video Seedance 2.0 720p опережает и Veo 3.1, и Sora 2 Pro в категории без аудио. Это не закрывает все споры о качестве, поскольку модели различаются по рабочим процессам, ограничениям безопасности и упаковке продукта, но показывает, что Seedance 2.0 вышла в ту же высшую лигу, что и наиболее заметные западные предложения.
Самое очевидное преимущество Seedance 2.0 — широта входных данных. По словам ByteDance, она может совместно обрабатывать текст, изображение, аудио и видео и одновременно использовать до 9 изображений, 3 видео и 3 аудиоклипов. Для сравнения, в документации OpenAI по Sora 2 указаны текст и изображение как входы, а видео и аудио — как выходы, с доступом через приложение Sora и sora.com; Sora 2 Pro также доступна пользователям ChatGPT Pro в веб‑версии. Google Veo 3.1 находится где‑то посередине: она ориентирована на создание по изображению и генерацию видео с насыщенным звуком, поддерживает до 3 референсных изображений, расширение сцен и контроль по первому и последнему кадрам.
Как получить доступ и где сравнивать
Если вы хотите получить доступ к Sora 2, Veo 3.1 и xx одновременно на одной платформе, я рекомендую CometAPI. Playgoud CometAPI предоставляет прямую генерацию видео, используя лишь простую команду или несколько референс‑изображений. Если вы хотите программно настроить собственный API генерации видео, CometAPI тем более стоит рассмотреть. Он предоставляет API для Sora 2, Veo 3.1 и др., и в настоящее время действует скидка 20%.
Как использовать Seedance 2.0 с CometAPI
Генерация видео по тексту
Опишите свою сцену. Чем конкретнее, тем лучше — укажите движение камеры, освещение, настроение и стиль. Сильная следовательность Seedance 2.0 промпту означает, что результат близко соответствует вашему замыслу, делая её надёжной для производства контента, а не для бесконечных итераций.
В CometAPI Playground вы можете напрямую вводить подсказки и генерировать видео с использованием модели Seedance 2.0. Это особенно полезно для контента соцсетей (Reels, TikTok, YouTube Shorts), брендовых видео и коротких нарративных клипов.
Как это работает:
- Откройте CometAPI
- Выберите модель Seedance 2.0
- Введите ваш промпт
- Настройте параметры (длительность, разрешение, соотношение сторон)
- Запустите задачу генерации и дождитесь результата
Image-to-Video с CometAPI
Загрузите статичное изображение — например, фото продукта, концепт‑иллюстрацию или дизайн‑макет — и используйте возможности image-to-video Seedance 2.0 через CometAPI, чтобы анимировать его.
Результат — плавное, контекстно‑осмысленное движение, созданное на основе вашего визуального ввода. Это идеально для команд, у которых уже есть дизайнерские ассеты и которые хотят превратить их в видео без полного продакшн‑процесса.
Как это работает:
- Используйте
input_reference(или соответствующее поле загрузки файлов в Playground) - Добавьте промпт, сфокусированный на движении, описывающий, как должна двигаться сцена
Пример промпта:
«Камера медленно наезжает на продукт, мягкий студийный свет, тонкие отражения, ощущение премиального рекламного ролика»
Совместная генерация аудио и видео за один проход
Вместо того чтобы сначала генерировать видео, а затем отдельно добавлять аудио, CometAPI поддерживает нативный конвейер совместной аудио‑видеогенерации Seedance 2.0.
Описав одновременно визуал и звук в одном промпте, вы можете получить синхронизированные видео и аудио за один шаг. Это даёт более цельный и осмысленный результат, а также сокращает время редактирования.
Пример промпта:
«Спокойный пляж на рассвете, мягкие набегающие волны, тёплый золотистый свет, мягкая эмбиент‑музыка со звуками океана»
Выход включает:
- Сгенерированное видео
- Синхронизированную фоновую дорожку
- Естественно согласованные тайминг и настроение
Почему использовать CometAPI для Seedance 2.0
- Прямой доступ через API или Playground
- Удобный контроль параметров (длительность, разрешение, формат)
- Поддержка рабочих процессов text-to-video и image-to-video
- Встроенная обработка задач для асинхронной генерации видео
Заключение
Seedance 2.0 выглядит как настоящий скачок в генерации видео ИИ: мультимодальная система, объединяющая ввод текста, изображений, аудио и видео; лидер рейтингов как в text-to-video, так и в image-to-video; и модель, созданная для управления на уровне режиссёра, а не для случайного «игрушечного» использования. Если вас интересует только субъективно воспринимаемое качество, текущие данные говорят, что оно исключительное.
Начните создавать с Seedance 2.0 на CometAPI уже сегодня.